目标网址:
http://www.51eliao.com/WinBidType.aspx?typeid=0
需要信息:
- √ 已完成:(第一页)
- 对应网址
- 中标时间
- 中标类型
- 中标名称
ps:下一页(即除了第一页)未完成
- × 未完成:新打开网页中需采集
- 招标单位
- 省
- 市
- 项目编号
- 供应商名称
- 供应商地址
- 联系人
- 联系电话
- 产品
- 品牌
- 厂家
- 规格型号
- 数量
- 单价
- 金额
ps:部分网页中暂无详细信息,需要点开网页中的网页,查看flash文件,人工采集信息。
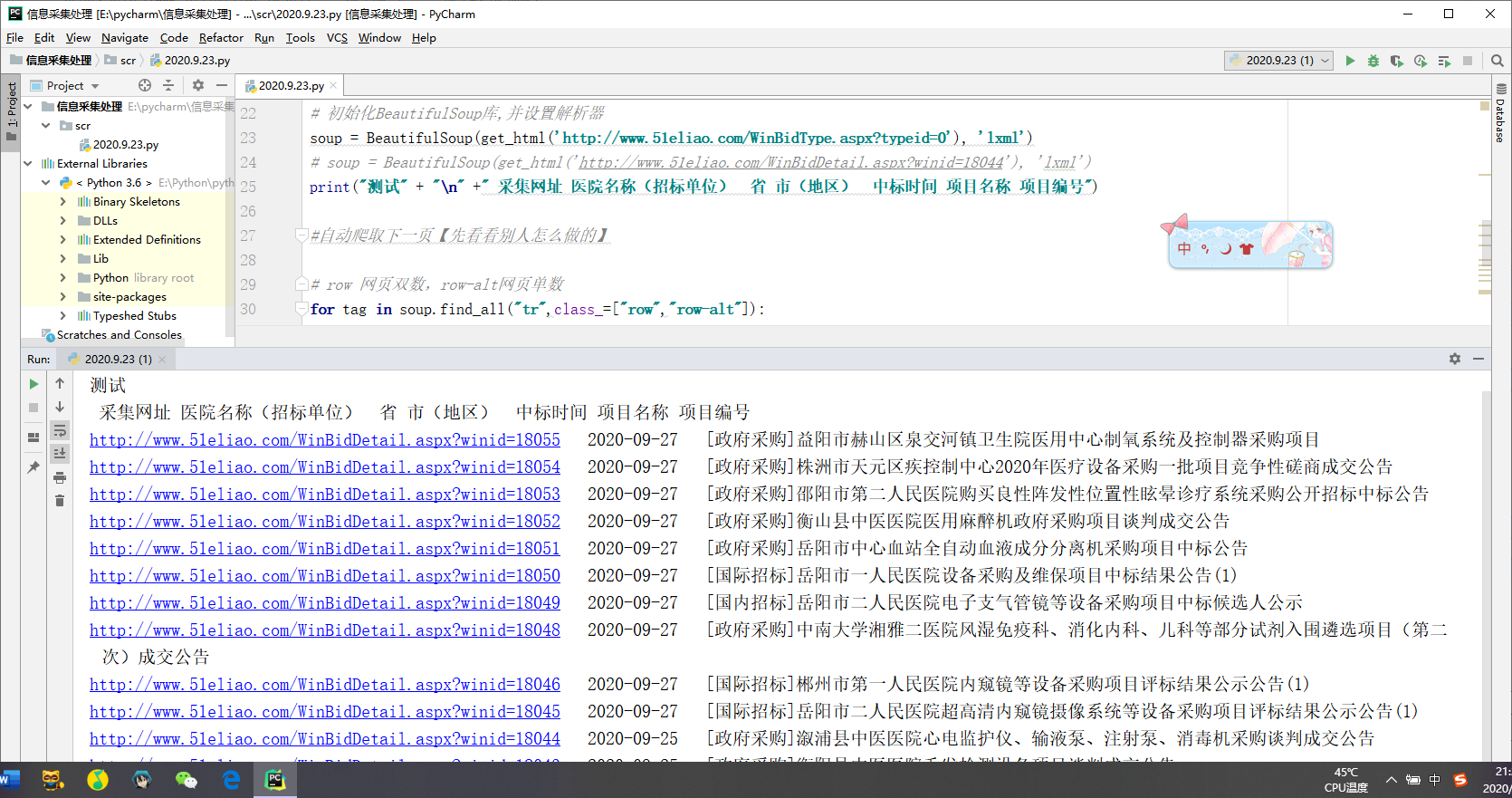
最后是要写入表格中的,暂时先在控制台中显示,用的python3.6
import requests from bs4 import BeautifulSoup def get_html(url): headers = { 'User-Agent': 'Mozilla/5.0(Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36(KHTML, like Gecko) Chrome/52 .0.2743. 116 Safari/537.36' } # 模拟浏览器访问 response = requests.get(url, headers=headers) # 请求访问网站 html = response.text # 获取网页源码 return html # 返回网页源码 # 初始化BeautifulSoup库,并设置解析器 soup = BeautifulSoup(get_html('http://www.51eliao.com/WinBidType.aspx?typeid=0'), 'lxml') # soup = BeautifulSoup(get_html('http://www.51eliao.com/WinBidDetail.aspx?winid=18044'), 'lxml') print("测试" + " " +" 采集网址 医院名称(招标单位) 省 市(地区) 中标时间 项目名称 项目编号") #自动爬取下一页【先看看别人怎么做的】 # row 网页双数,row-alt网页单数 for tag in soup.find_all("tr",class_=["row","row-alt"]): m_url = tag.find('a').get('href') #链接 m_type = tag.find('em').get_text() #中标类型 m_name = tag.find('a').get('title') #公司 m_time = tag.find('div',class_="d").get_text() #中标时间 print("http://www.51eliao.com/"+m_url+" "+m_time + " "+m_type+m_name)
小知识:
- ctrl+D 被选中的代码直接复制粘贴在下面
- ctrl+?被选中的代码全体被注释或解除注释
- shift+Tab 被选中代码前移,tab后移
- .get_text()函数:
会把你正在处理的HTML文档中所有的标签都清除,
然后返回一个只含有文字的字符串,
通常在准备打印,存储,和操作数据时,应该最后才使用这个函数。
一般情况下,应该尽可能的保留与HTML文档的标签结构。