锯齿产生的原因:
采样:
采样是 一种从模拟信号到数字信号再重建到模拟信号的过程
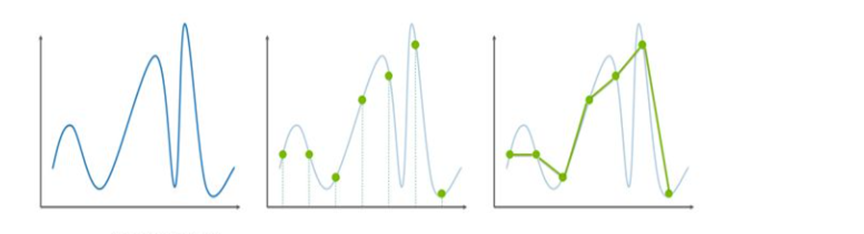
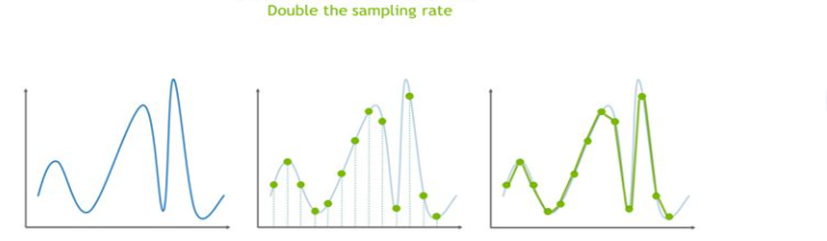
1倍频率和2倍频率 采样曲线
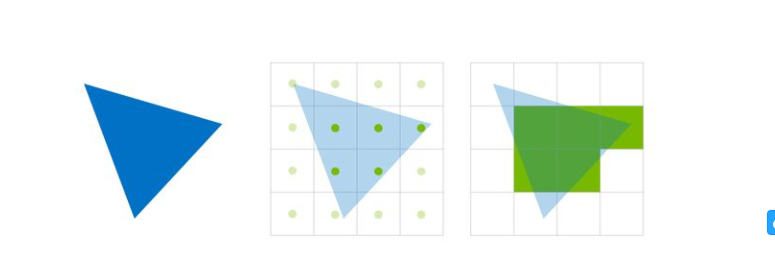
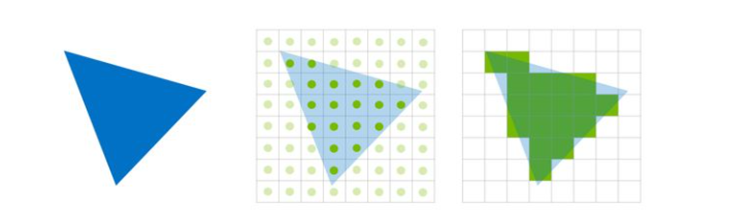
三角形采样
Nyquist采样定理
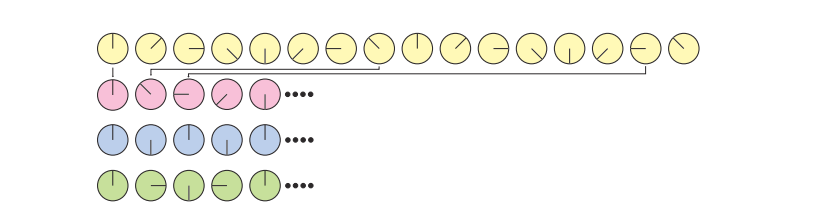
说明:第一行 原始采样的轮子转动(假使第一行原始采样周期是1s 中转一圈,也就是周期是1)
第二行 采样的轮子1/8 s 采样一次(此时看到的采样的轮子是逆时针旋转,明显是错误的)
第三行 采样轮子 0.5s 采样一次(此时是该定理的临界值,无法看到轮子旋转方向)
第四行 采样的轮子 0.25s 采样一次 (此时轮子可以恢复正确的转动方向,采样频率 > 2)

重建:
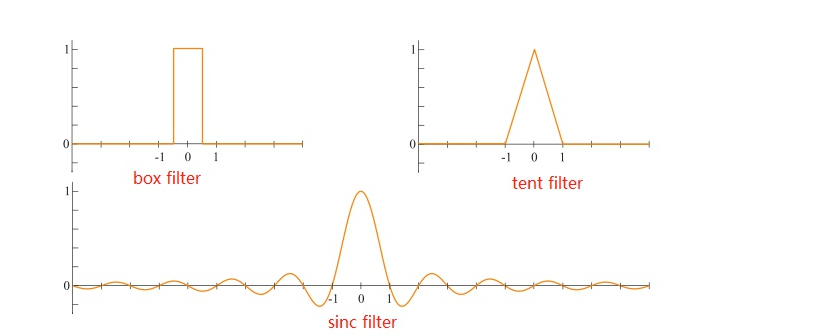

卷积:
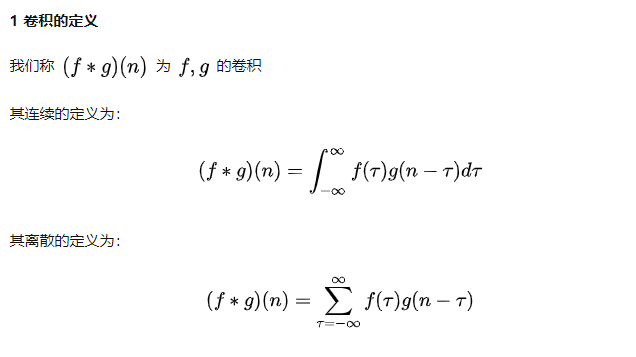

AA 方案:SSAA、MSAA、FXAA、MLAA、SMAA、TXAA、TAA、DLSS
SSAA:
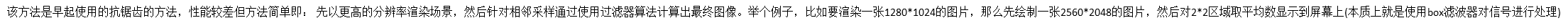
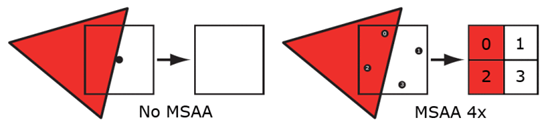
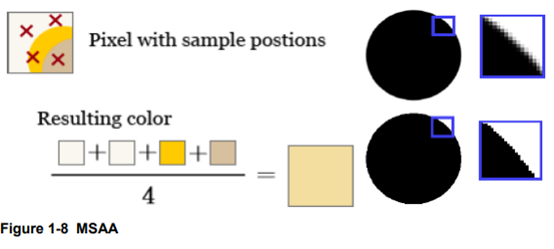
MSAA:

TAA:
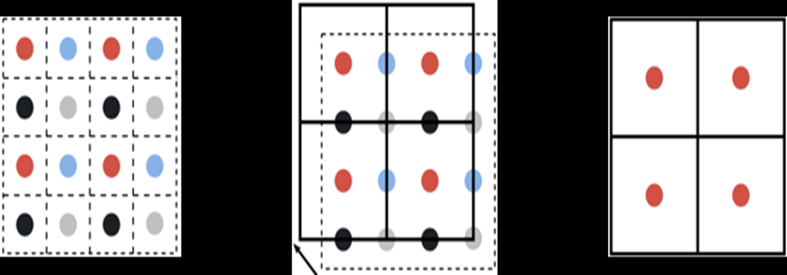

采样多帧颜色:


历史颜色融合:
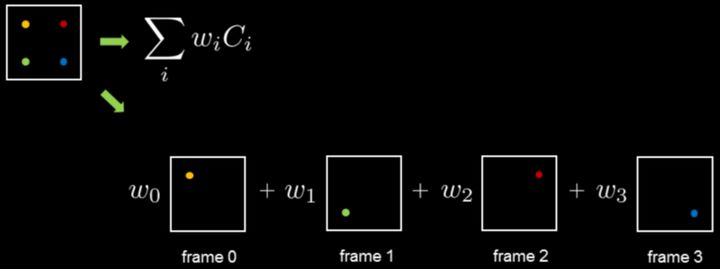


TXAA:


![]()
FXAA:

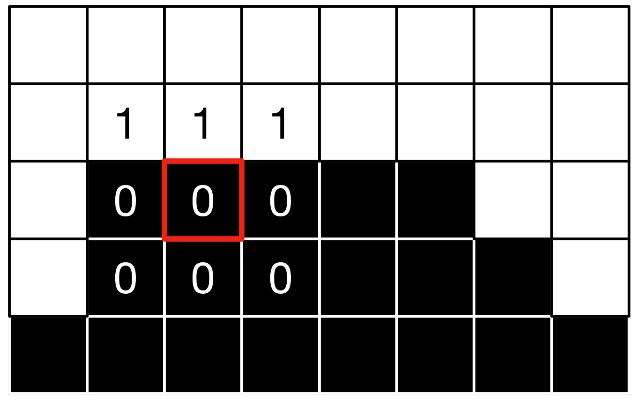

FXAA代码描述:
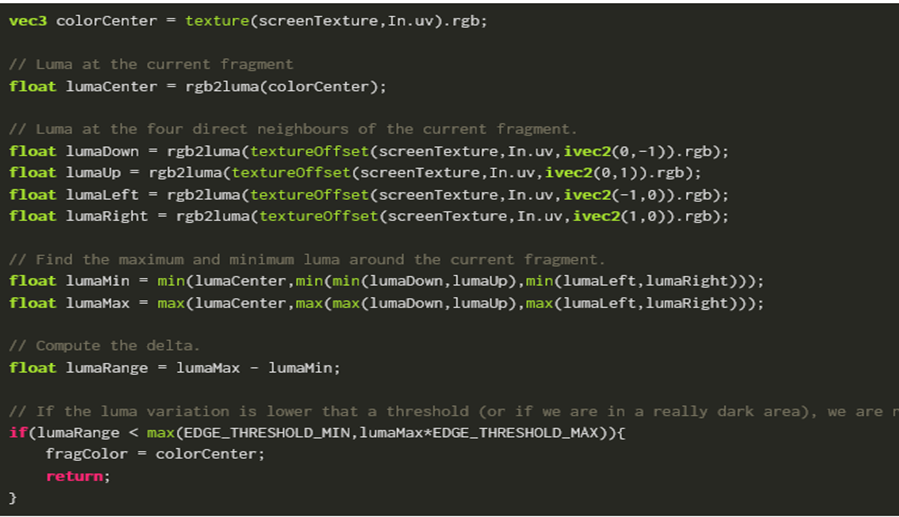
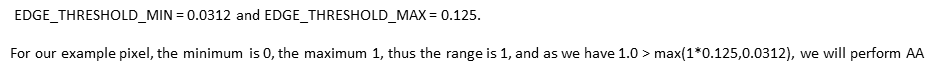
计算边缘朝向:

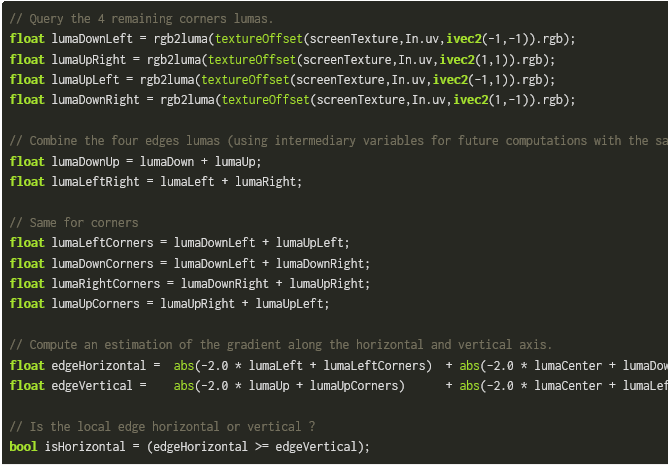
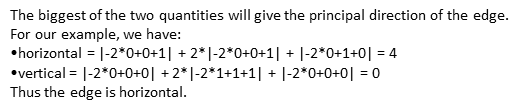
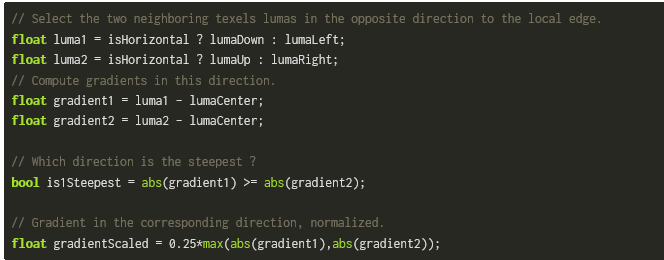
估算梯度---计算边界:


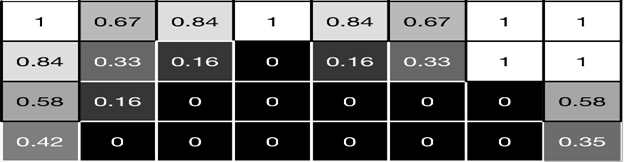
结果:


MLAA:
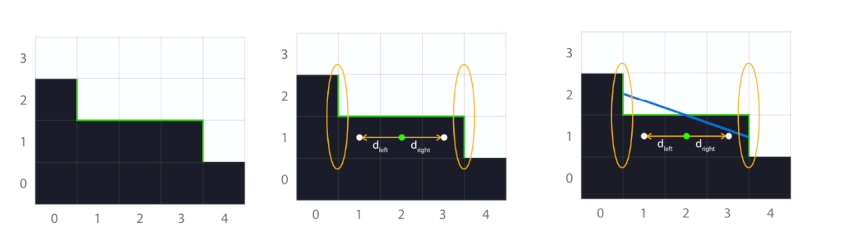
假设现在我们要对左边这样一张图片进行AA处理:
就需要找到中间图片中这条蓝色的线, 这就是对像素进行重矢量化(revectorization)
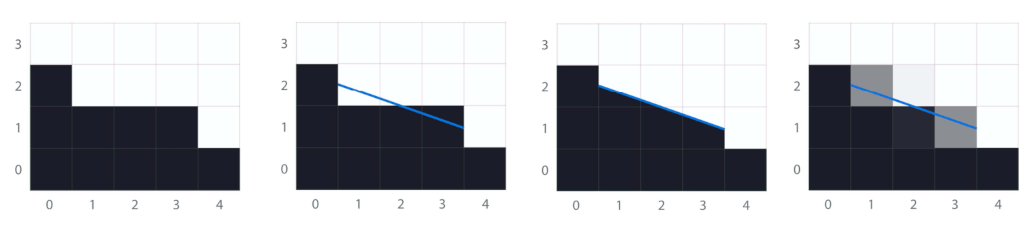
矢量化以后, 根据像素点被蓝色线覆盖的比例及位置, 就可以将像素进行处理, 得到右边图片. 这样, 我们就完成了AA处理的过程.
从这点出发, 我们可以大致梳理出我们想要的MLAA处理的流程:
- 边缘检测, 得到每个像素的边缘, 如下左图中绿色的线;
- 往左右两侧搜索边界线的终点, 即边缘线交叉的地方;
- 根据两侧交叉点位置, 将像素矢量化, 作出一条蓝色的线;
- 算出蓝色线覆盖像素的面积覆盖率;
- 根据覆盖率对像素进行处理
MLAA流程
实践中, 有这样几个问题需要解决:
- 每个点需要计算4条线;
- 搜索交叉边缘很慢;
- 重矢量化需要消耗大量带宽, 区域覆盖率计算很费;
针对这样几个问题, 我们提出了这样的解决方案:
- 像素边缘是共享的, 每个像素其实只需要计算左侧和上侧的边界;
- 借助双线性采样加速搜索;
- 使用预计算好的贴图, 避免实时计算.
接着来看具体的实现, 我们将MLAA实现分为三个PASS

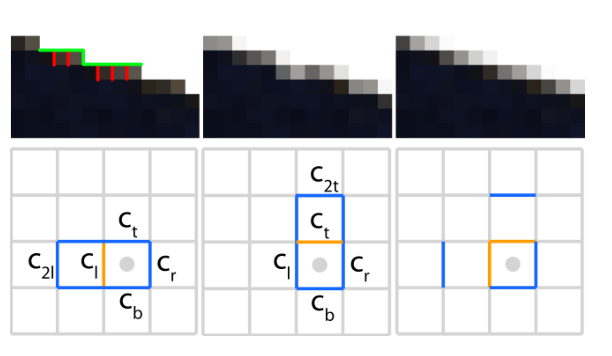
PASS1:边缘检测
就是简单地检测目标像素和周围点像素之间是否构成边界, 因为边界信息是共享的, 所以这里我们只需要考虑左边和上边像素点的边界.
边界判断方式可以是以下几种之一:
- 根据颜色, 通过亮度函数
, 得到像素亮度, 再判断两个像素亮度差超过某个阈值(比如0.1), 则认为是边界. 最常用普适的方法;
- 根据深度值判断, 需要将深度值先转为线性的;
- 材质ID/法线, 适用于Deferred-Rendering.
这样, 我们成功得到了像素间的边界, 并保存到一张R8G8的贴图中(0表示无边界, 1表示有边界, RG分别是左侧和上侧).
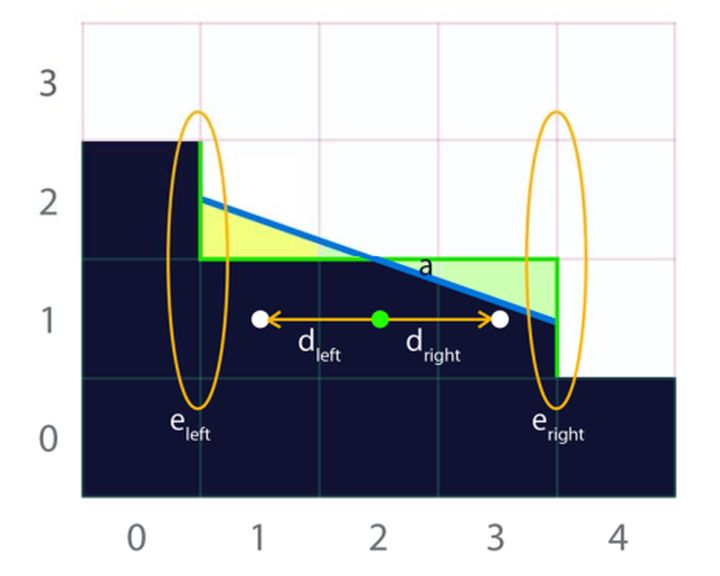
PASS2:混合权重计算
包括这样三步:
- 在当前需要计算的边界线两侧进行搜索, 取得距离
;
- 获取交叉处边界信息
;
- 根据前面的信息算出像素覆盖率
PASS3: 像素混合
这一步就是简单地取得上一步中的覆盖率信息, 并将颜色做混合.
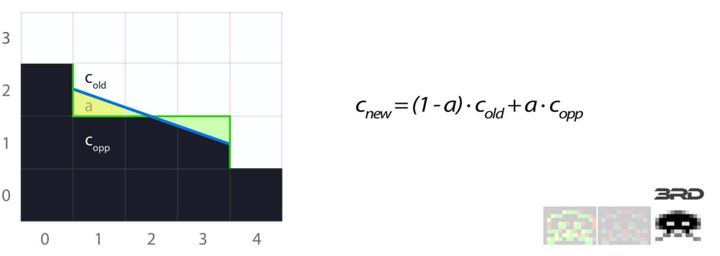
两个相邻像素颜色的混合, 其实就是两个颜色的线性插值. 这样, 我们又可以借助双线性采样, 从两个像素中间的某个位置取颜色, 直接得到插值后的颜色
SMAA:
SMAA对MLAA的几个部分做了如下改进:
1.更准确的边界判断
对于使用颜色判断边界的情况, 很容易出现边界误判, 使得本来不应该是边界的地方被视为边界, 比如一些光照很强的地方, 虽然亮度变化快, 但是不应该是边界. SMAA中使用Local contrast adaption对边界进行二次判断
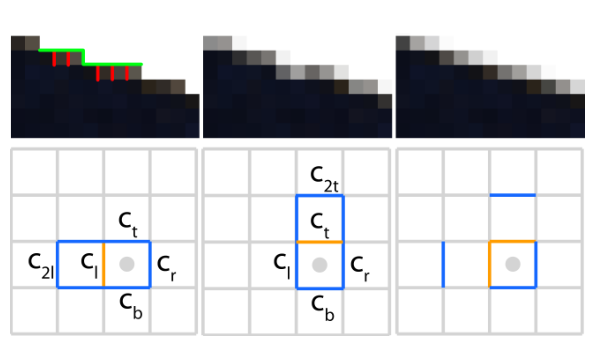
左图上侧, 红色部分是被错误计算的边界
假设我们现在要判断某个像素和左侧像素是否构成边界.
首先使用相对亮度差的绝对值和亮度差阈值初步判断是否构成边界:
如果构成, 则需要根据周围点亮度再判断一次:
如果二次判断通过, 这个边界被保留, 如果判断不通过, 这个边界被丢弃
2. 转角保留
在某些情况下, 一些几何体的棱角可能被错误地识别为是需要AA处理的部分.
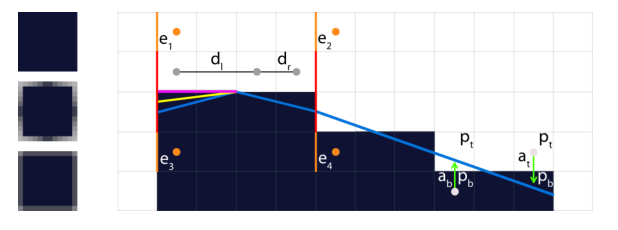
比如图中左上的正方形, 很可能被MLAA处理成左中的样子, 这种情况下, 其实是不需要AA处理的.
那么如何分辨这样的情况呢? 这里SMAA沿着交叉边界, 往外再取一次边界值(图中 ).
如果取不到边界, 则认为是需要进行AA处理.
如果还能取到边界, 则在原来计算出的覆盖率基础上, 再乘以一个转角系数 (范围是0~1, 通常取0.25). 比如右图中橙色, 黄色, 和蓝色, 分别代表三个不同转角系数下得到的新的覆盖率).
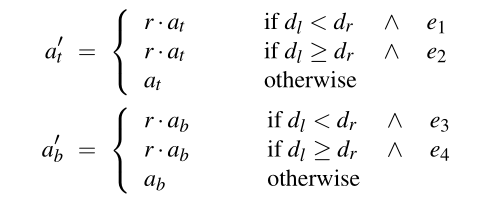
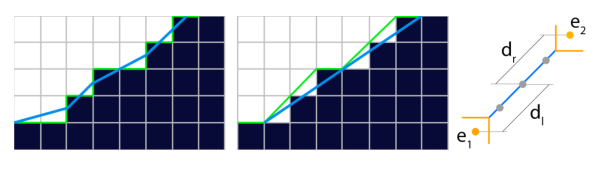
3. 对角线模式
MLAA中的模式, 主要针对的是水平方向和垂直方向. 然而这两种模式, 处理一些斜向的边界, 效果不是很好.
4. 更精确的边界搜索
前面在使用MLAA搜索边界时, 有可能在搜索途中遗漏一些交叉边界.
比如下图中在沿着左边进行搜索时, MLAA会使用橙色的点采样, 这样其实会将第一个左侧的边界遗漏, 因为搜索过程中, 仅判断了上边界, 没有判断左边界.
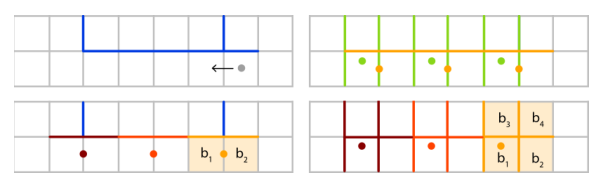
SMAA将双线性采样的技巧进一步发挥, 在右下图中的采样点采样, 在xy轴上取不同的偏移量, 这样就可以做到一次采样, 根据得到的值判断出周围4个点的信息.
如下图, 将采样点放置在2x2像素中心, 向左偏移1/3, 向下偏移1/6. 在R处采样, 在周围四个像素采样的权重分别为
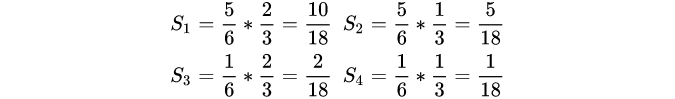
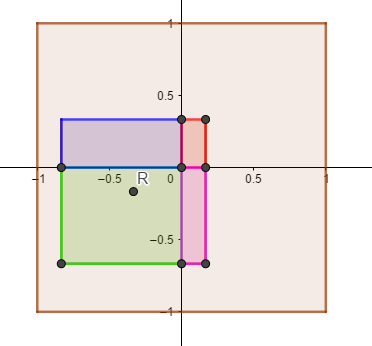
2x2像素中, 共有16中可能的组合, 每种组合下, 双线性采样得到的值都是唯一的.
这样, 我们实现了带边界的搜索. 不过需要注意的时, 使用这种方法的话, 使用的边界信息必须是上下左右全部都包括, 而不能是MLAA中的只生成上左的边界.
https://zhuanlan.zhihu.com/p/342211163
https://zhuanlan.zhihu.com/p/71785353
https://blog.codinghorror.com/fast-approximate-anti-aliasing-fxaa/