题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=1560
DNA sequence
Time Limit: 15000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)
Total Submission(s): 2999 Accepted Submission(s): 1462
Problem Description
The twenty-first century is a biology-technology developing century. We know that a gene is made of DNA. The nucleotide bases from which DNA is built are A(adenine), C(cytosine), G(guanine), and T(thymine). Finding the longest common subsequence between DNA/Protein
sequences is one of the basic problems in modern computational molecular biology. But this problem is a little different. Given several DNA sequences, you are asked to make a shortest sequence from them so that each of the given sequence is the subsequence
of it.
For example, given "ACGT","ATGC","CGTT" and "CAGT", you can make a sequence in the following way. It is the shortest but may be not the only one.
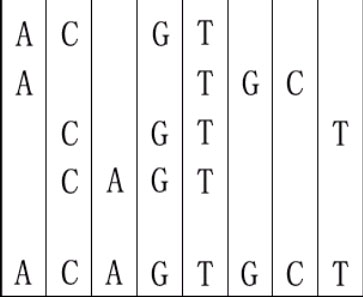
For example, given "ACGT","ATGC","CGTT" and "CAGT", you can make a sequence in the following way. It is the shortest but may be not the only one.
Input
The first line is the test case number t. Then t test cases follow. In each case, the first line is an integer n ( 1<=n<=8 ) represents number of the DNA sequences. The following k lines contain the k sequences, one per line. Assuming that the length of any
sequence is between 1 and 5.
Output
For each test case, print a line containing the length of the shortest sequence that can be made from these sequences.
Sample Input
1
4
ACGT
ATGC
CGTT
CAGT
Sample Output
8
Author
LL
Source
题解:
一开始以为是直接用回溯的方法,结果TLE。看了题解是用IDA*(迭代加深搜),其实自己不太了解迭代加深搜为什么比较快,而且什么时候用合适?下面是自己对迭代加深搜的一些浅薄的了解:
1.首先迭代加深搜适合用在:求最少步数(带有BFS的特点)并且不太容易估计搜索深度的问题上,同时兼有了BFS求最少步数和DFS易写、无需多开数组的特点。
2.相对于赤裸裸的回溯,迭代加深搜由于限制了搜索深度,所以也能适当地剪枝。
3.我编不下去了……
代码一:


1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 #include <cmath> 5 #include <algorithm> 6 #include <vector> 7 #include <queue> 8 #include <stack> 9 #include <map> 10 #include <string> 11 #include <set> 12 #define ms(a,b) memset((a),(b),sizeof((a))) 13 using namespace std; 14 typedef long long LL; 15 const int INF = 2e9; 16 const LL LNF = 9e18; 17 const int MOD = 1e9+7; 18 const int MAXN = 10+10; 19 20 int n; 21 char dna[MAXN][MAXN]; 22 int len[MAXN], pos[MAXN]; 23 char s[4] = {'A', 'G', 'C', 'T'}; 24 25 bool dfs(int k, int limit) //k为放了几个, k+1才为当前要放的 26 { 27 int maxx = 0, cnt = 0; //maxx为最长剩余的dna片段, cnt为剩余的片段之和(核苷酸链?好怀念啊) 28 for(int i = 0; i<n; i++) 29 { 30 cnt += len[i]-pos[i]; 31 maxx = max(maxx, len[i]-pos[i]); 32 } 33 if(cnt==0) return true; //如果片段都放完,则已得到答案 34 if(cnt<=limit-k) return true; //剪枝:片段之和小于等于剩余能放数量,肯定能够得到答案 35 if(maxx>limit-k) return false; //剪枝:最小的估计值都大于剩余能放数量,肯定不能得到答案 36 37 int tmp[MAXN]; 38 for(int i = 0; i<4; i++) 39 { 40 memcpy(tmp, pos, sizeof(tmp)); 41 bool flag = false; 42 for(int j = 0; j<n; j++) 43 if(dna[j][pos[j]]==s[i]) 44 pos[j]++, flag = true; 45 46 //k+1<=limit:在限制范围内 47 if(k+1<=limit && flag && dfs(k+1, limit) ) 48 return true; 49 memcpy(pos, tmp, sizeof(pos)); 50 } 51 return false; 52 } 53 54 int main() 55 { 56 int T; 57 scanf("%d",&T); 58 while(T--) 59 { 60 scanf("%d",&n); 61 int limit = 0; 62 for(int i = 0; i<n; i++) 63 { 64 scanf("%s",dna[i]); 65 len[i] = strlen(dna[i]); 66 limit = max(limit, len[i]); 67 } 68 69 ms(pos, 0); 70 while(!dfs(0, limit)) 71 limit++; 72 printf("%d ", limit); 73 } 74 }
代码二:
1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 #include <cmath> 5 #include <algorithm> 6 #include <vector> 7 #include <queue> 8 #include <stack> 9 #include <map> 10 #include <string> 11 #include <set> 12 #define ms(a,b) memset((a),(b),sizeof((a))) 13 using namespace std; 14 typedef long long LL; 15 const int INF = 2e9; 16 const LL LNF = 9e18; 17 const int MOD = 1e9+7; 18 const int MAXN = 10+10; 19 20 int n; 21 char dna[MAXN][MAXN]; 22 int len[MAXN], pos[MAXN]; 23 char s[4] = {'A', 'G', 'C', 'T'}; 24 25 bool dfs(int k, int limit) //k为放了几个, k+1才为当前要放的 26 { 27 if(k>limit) return false; 28 29 int maxx = 0, cnt = 0; //maxx为最长剩余的dna片段, cnt为剩余的片段之和(核苷酸链?好怀念啊) 30 for(int i = 0; i<n; i++) 31 { 32 cnt += len[i]-pos[i]; 33 maxx = max(maxx, len[i]-pos[i]); 34 } 35 if(cnt==0) return true; //如果片段都放完,则已得到答案 36 if(cnt<=limit-k) return true; //剪枝:片段之和小于等于剩余能放数量,肯定能够得到答案 37 if(maxx>limit-k) return false; //剪枝:最小的估计值都大于剩余能放数量,肯定不能得到答案 38 39 int tmp[MAXN]; 40 for(int i = 0; i<4; i++) 41 { 42 memcpy(tmp, pos, sizeof(tmp)); 43 bool flag = false; 44 for(int j = 0; j<n; j++) 45 if(dna[j][pos[j]]==s[i]) 46 pos[j]++, flag = true; 47 48 if(flag && dfs(k+1, limit) ) 49 return true; 50 memcpy(pos, tmp, sizeof(pos)); 51 } 52 return false; 53 } 54 55 int main() 56 { 57 int T; 58 scanf("%d",&T); 59 while(T--) 60 { 61 scanf("%d",&n); 62 int limit = 0; 63 for(int i = 0; i<n; i++) 64 { 65 scanf("%s",dna[i]); 66 len[i] = strlen(dna[i]); 67 limit = max(limit, len[i]); 68 } 69 70 ms(pos, 0); 71 while(!dfs(0, limit)) 72 limit++; 73 printf("%d ", limit); 74 } 75 }