主要内容:
一.Photo OCR
二.Getting lots of data:artificial data synthesis
三.Ceiling analysis
一.Photo OCR
Photo OCR就是从图片中提取文本或者需要的数据,其具体步骤可分三个:
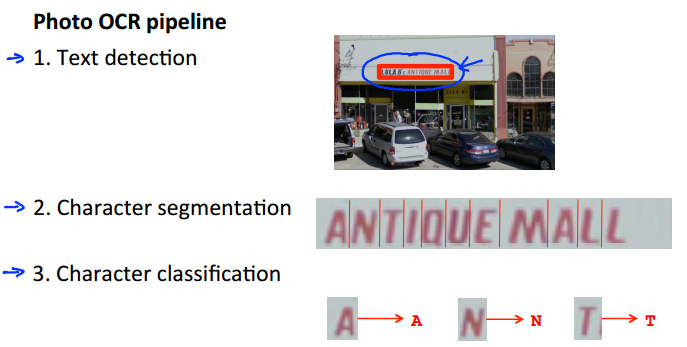
第一步:Text detection or pedestrain detection
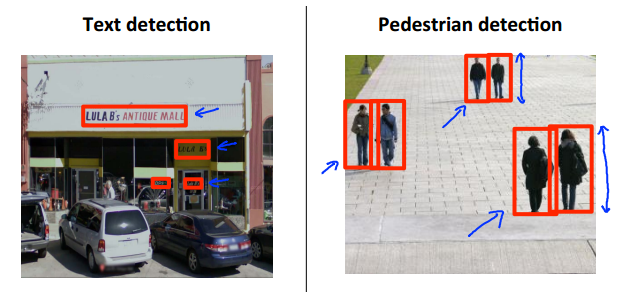
采用的方法是,sliding windows。即设置一个大小固定的窗口去扫描增长图片,以次去检测文字(文字检测稍微复杂)或者行人。当然由于字体或者人因远近而大小不一,需要不断地调整窗口的大小。
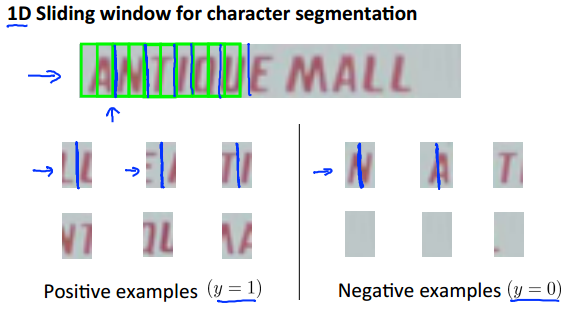
第二步:隔断文字。同样是采用一个窗口从左往右取扫描文字区域,当滑动到两个文字中间时,y设为1;当滑动到一个文字时,y设为0。
第三步,直接将分割出的文字进行分类:

二.Getting lots of data:artificial data synthesis
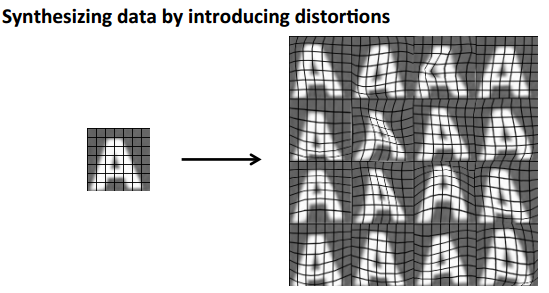
当我们手头上的数据不够多时,可以利用已有的数据做一些变形或扭曲的操作,从而人工合成大量且可靠的数据。
例如,对一个字母A做适当的扭曲:
或者对音频加噪音、设置不同的背景(如电话、山洞等):

下面是有关“获得更多数据”的一些讨论:

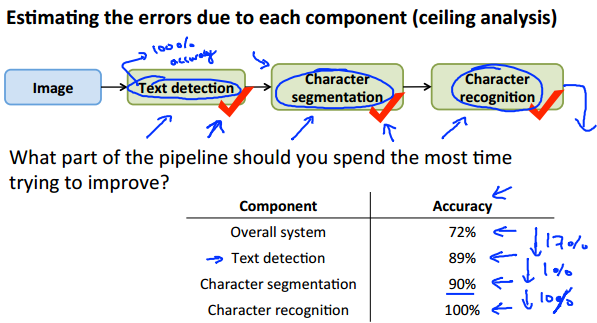
三.Ceiling analysis
在Photo OCR的整个过程中,我们想知道:哪个环节的改进对于最终结果的影响是最大的?以此避免做一些无用功,如我们花很多时间去改进某一环节,但这个环节的改进对于最终结果的影响是微乎其微的。因此,这里引入一个方法:ceiling analysis。
其核心思想是:将某一部分的精度提升为100%(可以是人工操作),然后看最终的准确率提升了多少。当然,在检测完前面的环节后,需保持前面环节100%的准确率,再去检测后面的环节。(疑问:问什么不能只把要检测的环节提升至100%?)