主要内容:
一.贝叶斯公式与朴素贝叶斯法
二.先验概率与后验概率
三.极大似然估计与贝叶斯估计
四.利用朴素贝叶斯进行文档分类
五.利用朴素贝叶斯进行垃圾邮件过滤
六.补充
一.贝叶斯公式与朴素贝叶斯法
1.贝叶斯公式
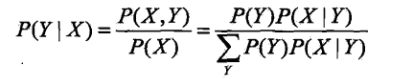
2.朴素贝叶斯:假定所有变量X都相互独立(条件独立性),那么上式中的P(X|Y)可以变为:
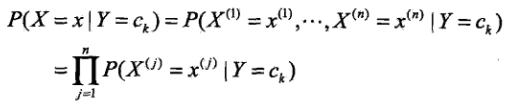
这是一个较强的假设,即假设比较简单直接、没有考虑太多因素。但正因如此,模型包含的条件概率的数量大为减少,朴素贝叶斯法的学习与预测大为简化。
因而朴素贝叶斯法高效,且易于实现;缺点是分类的性能不一定很高。
3.在使用朴素贝叶斯法时,我们要做的就是计算[P(Y0|X)、P(Y1|X)、……P(Yn|X)],然后选取概率最大的那一个分类,作为输入值的分类。
在计算P(Yi|X)时,根据贝叶斯公式,都需要除以相同的值P(X),但由于我们只需要比较大小,而不需要求出具体的值,所以可以免去这一步,所以总体而言,朴素贝叶斯法就是:

可以看出,在朴素贝叶斯法中,我们需要计算两类值:P(Y)和P(X|Y)。
二.先验概率与后验概率
1.先验概率:根据以往经验和分析得到的概率。
2.后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。
如贝叶斯公式中:P(Y|X) = P(X|Y)*P(Y)/P(X)
P(X)、P(Y)是根据以往大量的经验而获得的概率,因此他们是先验概率(P(X|Y)这一个条件概率应该也是先验概率?)
而P(Y|X)则是:在X已经发生的情况下,问其是由Y引起的概率。即由果溯因,为后验概率。
三.极大似然估计与贝叶斯估计
1.极大似然估计(也是最普通的做法):

其算法流程如下:

2.贝叶斯估计(对极大似然估计的优化):

四.利用朴素贝叶斯进行文档分类


1 # coding:utf-8 2 ''' 3 Created on Oct 19, 2010 4 @author: Peter 5 ''' 6 from numpy import * 7 8 '''创造一些数据''' 9 def loadDataSet(): 10 postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], 11 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], 12 ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], 13 ['stop', 'posting', 'stupid', 'worthless', 'garbage'], 14 ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], 15 ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] 16 classVec = [0, 1, 0, 1, 0, 1] # 相应的标签,1是带有侮辱性的,0不带侮辱性 17 return postingList, classVec 18 19 '''创建单词表,先用set去重,然后再以list的形式返回''' 20 def createVocabList(dataSet): 21 vocabSet = set([]) # create empty set 22 for document in dataSet: 23 vocabSet = vocabSet | set(document) # union of the two sets 24 return list(vocabSet) 25 26 '''返回一个01列表,表示单词表中的某个单词是否出现在inputSet中''' 27 def setOfWords2Vec(vocabList, inputSet): 28 returnVec = [0] * len(vocabList) 29 for word in inputSet: 30 if word in vocabList: 31 returnVec[vocabList.index(word)] = 1 32 else: 33 print "the word: %s is not in my Vocabulary!" % word 34 return returnVec 35 36 '''文档词袋模型,即把原来“单词是否出现在文档上”改为“单词在文档上出现了几次”''' 37 def bagOfWords2VecMN(vocabList, inputSet): 38 returnVec = [0] * len(vocabList) 39 for word in inputSet: 40 if word in vocabList: 41 returnVec[vocabList.index(word)] += 1 #把原先的 “=1”改为“+=1” 42 return returnVec 43 44 '''求出P(c1)、P(w|c1)、P(w|c0). 当P(c1)求出时,P(c0) = 1-P(c1)''' 45 '''其中P(w|c1)是一个列表,等于[P(w1|c1),P(w2|c1),P(w3|c1)……],P(w|c0)也是一个列表;P(c0)为一个实数''' 46 def trainNB0(trainMatrix, trainCategory): 47 numTrainDocs = len(trainMatrix) #训练数据集的大小,即第一维 48 numWords = len(trainMatrix[0]) #一条训练数据集的特征数,也就是单词表的长度,即第二维 49 pAbusive = sum(trainCategory) / float(numTrainDocs) #P(c1) 50 ''' 51 以下是计算P(w|c1)、P(w|c0)的初始化阶段。 52 在计算P(w1|c1)*P(w2|c0)*……时,如果其中一个为0,那么结果就为0,为了降低这种影响, 53 可使用拉普拉斯平滑:分子初始化为1,分母初始化为2(有几个分类就初始化为几。这里有两个分类,所以初始化为2) 54 ''' 55 p0Num = ones(numWords) 56 p1Num = ones(numWords) 57 p0Denom = 2.0 58 p1Denom = 2.0 59 '''''' 60 for i in range(numTrainDocs): 61 if trainCategory[i] == 1: 62 p1Num += trainMatrix[i] 63 p1Denom += sum(trainMatrix[i]) 64 else: 65 p0Num += trainMatrix[i] 66 p0Denom += sum(trainMatrix[i]) 67 ''' 68 以下是计算P(w|c1)、P(w|c0)的最终部分。 69 在计算P(w1|c1)*P(w2|c0)*……时,由于太多很小的数相乘,很容易造成下溢,当四舍五入时结果就很可能为0, 70 解决办法是对乘积取对数,就有:ln(ab) = lna+lnb把“小数相乘”转化为小数相加,避免了下溢。 71 由于x与lnx在x>0处有相同的增减性,两者的最值不相同,但最值点是相同的,所以不会影响最终的分类。 72 ''' 73 p1Vect = log(p1Num / p1Denom) # P(w|c1) 74 p0Vect = log(p0Num / p0Denom) # P(w|c0) 75 '''''' 76 return p0Vect, p1Vect, pAbusive 77 78 '''利用朴素贝叶斯进行分类,其中vec2Classify为输入数据,他是有关单词表的01串, 79 p0Vec, p1Vec, pClass1则为trainNB0()的3个返回值,即P(w|c0)、P(w|c1)、P(c1)''' 80 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 81 ''' 82 vec2Classify * p1Vec是什么意思? 83 可知p1Vec为训练数据集中的P(w|c1),它是一个列表(对应着单词表)。在计算P(w|c1)时,每一个单词的概率即P(wi|c1)都计算了, 84 但对于输入数据而言,有些单词出现了,有些单词没有出现,而我们只需要计算基础了的单词,所以要乘上系数ec2Classify 85 ''' 86 ''' 87 sum(vec2Classify * p1Vec)计算的是P(w|c1),log(pClass1)计算的是P(c1) 88 按照贝叶斯公式,理应还要减去P(w)的那一部分。但由于p1、p0都需要减去这一部分的值, 89 且我们只需要比较p1、p0的大小而不需求求出具体的值,所以可以省去这一部分的计算 90 ''' 91 p1 = sum(vec2Classify * p1Vec) + log(pClass1) # element-wise mult 92 p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) 93 if p1 > p0: 94 return 1 95 else: 96 return 0 97 98 def testingNB(): 99 listOPosts, listClasses = loadDataSet() #提取数据 100 myVocabList = createVocabList(listOPosts) 101 trainMat = [] 102 for postinDoc in listOPosts: #数据加工,trainMat、listClasses为训练数据集,其中trainMat为特征X,listClasses为标签Y 103 trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) 104 p0V, p1V, pAb = trainNB0(array(trainMat), array(listClasses)) #计算出概率P(c1)、P(w|c1)、P(w|c0) 105 testEntry = ['love', 'my', 'dalmation'] #测试数据 106 thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) 107 print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb) 108 testEntry = ['stupid', 'garbage'] 109 thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) 110 print testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb) 111 112 if __name__=="__main__": 113 testingNB()
五.利用朴素贝叶斯进行垃圾邮件过滤
1 # coding:utf-8 2 3 from numpy import * 4 5 '''创建单词表,先用set去重,然后再以list的形式返回''' 6 def createVocabList(dataSet): 7 vocabSet = set([]) # create empty set 8 for document in dataSet: 9 vocabSet = vocabSet | set(document) # union of the two sets 10 return list(vocabSet) 11 12 '''文档词袋模型,即把原来“单词是否出现在文档上”改为“单词在文档上出现了几次”''' 13 def bagOfWords2VecMN(vocabList, inputSet): 14 returnVec = [0] * len(vocabList) 15 for word in inputSet: 16 if word in vocabList: 17 returnVec[vocabList.index(word)] += 1 #把原先的 “=1”改为“+=1” 18 return returnVec 19 20 '''求出P(c1)、P(w|c1)、P(w|c0). 当P(c1)求出时,P(c0) = 1-P(c1)''' 21 '''其中P(w|c1)是一个列表,等于[P(w1|c1),P(w2|c1),P(w3|c1)……],P(w|c0)也是一个列表;P(c0)为一个实数''' 22 def trainNB0(trainMatrix, trainCategory): 23 numTrainDocs = len(trainMatrix) #训练数据集的大小,即第一维 24 numWords = len(trainMatrix[0]) #一条训练数据集的特征数,也就是单词表的长度,即第二维 25 pAbusive = sum(trainCategory) / float(numTrainDocs) #P(c1) 26 ''' 27 以下是计算P(w|c1)、P(w|c0)的初始化阶段。 28 在计算P(w1|c1)*P(w2|c0)*……时,如果其中一个为0,那么结果就为0,为了降低这种影响, 29 可使用拉普拉斯平滑:分子初始化为1,分母初始化为2(有几个分类就初始化为几。这里有两个分类,所以初始化为2) 30 ''' 31 p0Num = ones(numWords) 32 p1Num = ones(numWords) 33 p0Denom = 2.0 34 p1Denom = 2.0 35 '''''' 36 for i in range(numTrainDocs): 37 if trainCategory[i] == 1: 38 p1Num += trainMatrix[i] 39 p1Denom += sum(trainMatrix[i]) 40 else: 41 p0Num += trainMatrix[i] 42 p0Denom += sum(trainMatrix[i]) 43 ''' 44 以下是计算P(w|c1)、P(w|c0)的最终部分。 45 在计算P(w1|c1)*P(w2|c0)*……时,由于太多很小的数相乘,很容易造成下溢,当四舍五入时结果就很可能为0, 46 解决办法是对乘积取对数,就有:ln(ab) = lna+lnb把“小数相乘”转化为小数相加,避免了下溢。 47 由于x与lnx在x>0处有相同的增减性,两者的最值不相同,但最值点是相同的,所以不会影响最终的分类。 48 ''' 49 p1Vect = log(p1Num / p1Denom) # P(w|c1) 50 p0Vect = log(p0Num / p0Denom) # P(w|c0) 51 '''''' 52 return p0Vect, p1Vect, pAbusive 53 54 '''利用朴素贝叶斯进行分类,其中vec2Classify为输入数据,他是有关单词表的01串, 55 p0Vec, p1Vec, pClass1则为trainNB0()的3个返回值,即P(w|c0)、P(w|c1)、P(c1)''' 56 def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): 57 ''' 58 vec2Classify * p1Vec是什么意思? 59 可知p1Vec为训练数据集中的P(w|c1),它是一个列表(对应着单词表)。在计算P(w|c1)时,每一个单词的概率即P(wi|c1)都计算了, 60 但对于输入数据而言,有些单词出现了,有些单词没有出现,而我们只需要计算基础了的单词,所以要乘上系数ec2Classify 61 ''' 62 ''' 63 sum(vec2Classify * p1Vec)计算的是P(w|c1),log(pClass1)计算的是P(c1) 64 按照贝叶斯公式,理应还要减去P(w)的那一部分。但由于p1、p0都需要减去这一部分的值, 65 且我们只需要比较p1、p0的大小而不需求求出具体的值,所以可以省去这一部分的计算 66 ''' 67 p1 = sum(vec2Classify * p1Vec) + log(pClass1) # element-wise mult 68 p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1) 69 if p1 > p0: 70 return 1 71 else: 72 return 0 73 74 def textParse(bigString): # 提取、处理、过滤单词 75 import re 76 listOfTokens = re.split(r'W*', bigString) 77 return [tok.lower() for tok in listOfTokens if len(tok) > 2] 78 79 def spamTest(): 80 docList = [] 81 classList = [] 82 fullText = [] 83 for i in range(1, 26): 84 wordList = textParse(open('email/spam/%d.txt' % i).read()) 85 docList.append(wordList) 86 fullText.extend(wordList) 87 classList.append(1) 88 wordList = textParse(open('email/ham/%d.txt' % i).read()) 89 docList.append(wordList) 90 fullText.extend(wordList) 91 classList.append(0) 92 vocabList = createVocabList(docList) # 创建单词表 93 trainingSet = range(50) 94 testSet = [] # 从50条数据中随机选出10个作为测试数据,trainingSet和testSet存的都是下标,对应在docList和classList上 95 for i in range(10): 96 randIndex = int(random.uniform(0, len(trainingSet))) 97 testSet.append(trainingSet[randIndex]) 98 del (trainingSet[randIndex]) 99 trainMat = [] 100 trainClasses = [] 101 for docIndex in trainingSet: # 剩下的的都作为训练数据集 102 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) 103 trainClasses.append(classList[docIndex]) 104 p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses)) #计算出概率P(c1)、P(w|c1)、P(w|c0) 105 errorCount = 0 106 for docIndex in testSet: # 进行测试 107 wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) 108 if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: 109 errorCount += 1 110 print "classification error", docList[docIndex] 111 print 'the error rate is: ', float(errorCount) / len(testSet) 112 # return vocabList,fullText 113 114 if __name__=="__main__": 115 spamTest()
六.补充(个人混淆处)
在学习第四、五节的利用朴素贝叶斯进行文本分类时,自己有一个点想了很久,如下:
1.可知P(c|w) = P(c|w1)*P(c|w1)……P(c|wn),其中w为特征,是一个长度为n的列表。
2.假如一个文档出现了单词a和单词b,问其是分类0的概率? 则P(c0|[a,b]) = P(c0|a)*P(c0|b),即:在单词a出现且单词b出现的条件下(对应于P(c0|a)*P(c0|b)),问文档分类为0的概率。
3.然而,当时我的思维却受到了《实战》源码的一个影响。《实战》中首先是构建一个很长但单词表,假设有[a,b,c,d,e],在训练样本中,每一个单词在特定的分类中都对应有一个出现的概率P(c0|wi),wi为第i个单词。由于上述文档只出现了单词a、b,所以可以先为单词出现的概率乘上相应的系数矩阵,该文档对于的系数矩阵为[1,1,0,0,0],一乘之后就只剩下[P(c0|a), P(c0|b)],所以最后就是P(c0|[a,b]) = P(c0|a)*P(c0|b)。但也就是这个系数矩阵,0代表着没有出现,1代表着出现。于是我就在这里开始兜圈了:c没有出现,按照P(c|w) = P(c|w1)*P(c|w1)……P(c|wn),不是应该还要乘上c没有出现的概率,即(1-P(c0|c))吗?同理d、e?
答:可能是受到了多特征的影响,如“是否好人”作为一个特征,“性别”又作为一个特征。对于“是否好人”这个特征,取值如果不是“好人”,那么就是“坏人”,他们相加的概率为1,即完备组。同理“性别”特征中“男”与“女”也为一个完备组。对于文本处理中的“出现哪些单词”中,“出现单词a”和“出现单词b”可以认为是属于同一个特征,而非不同的特征,因为当所有单词出现的概率相加等于1,构成一个完备组。所以对于没有出现的单词,是不用再乘上其“没有出现的概率”的,而只需乘上“出现的单词的概率”。
4.以上内容词不达意,许多纰漏,但意思能够理会于心中,权且写在这里记录一下,以后能够清晰表达出来了再重新写一遍。