1.why look at case study
这周会讲一些典型的cnn模型,通过学习这些,我们能够对于cnn加深自己的理解,并且在实际的应用中有可能应用到这些,或从中获取灵感

2.Classic networks
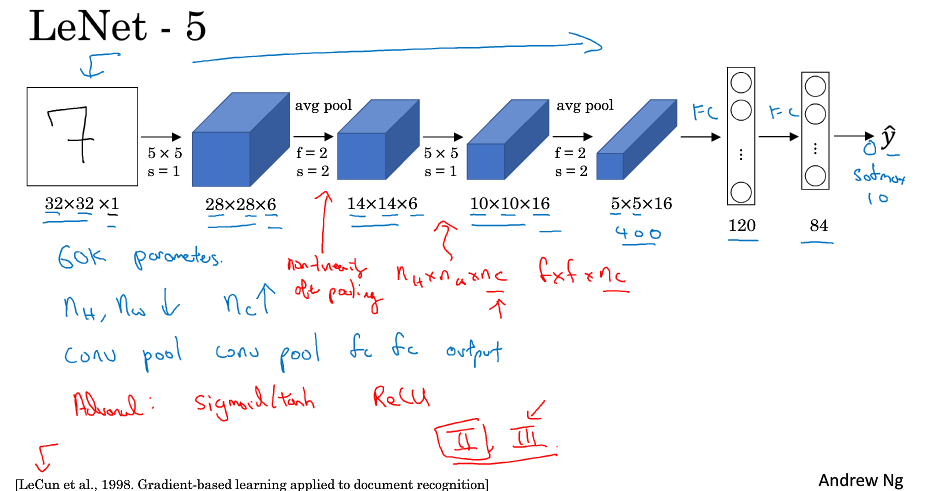
LeNet-5模型是Yann LeCun教授于1998年提出来的,它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据中,它的准确率达到大约99.2%。
它的结构如下:由conv layer - pool layer - conv layer - pool layer -full connected layer -full connected layer -soft max out put lay 组成
特点:只有6w多个参数,那个时候使用的还是sigmoid,tanh激活函数,池化使用的是平均池化,随着层数的增加,nH,nW减少,而nC增加.
AlexNet
AlexNet与LeNet类似,其结构如下图,但是比LeNet更大,而且使用的是relu激活函数,它有6千万多个参数.
AlexNet在细节上使用了更多更复杂的东西,比如多个cpu训练,让这些cpu彼此联系
并且使用了LRN,不过后来被证实并没有多大作用

VCG-16
VCG是一个更加复杂的网络,他多达1.38亿个参数
特点:使用的filter都为3X3,stride=1,使用的是same padding;
max-pool尺寸为2X2,stride=2

3.Residual Networks
当训练的神经网络的深度越来越深时,由于存在的梯度消失与梯度爆炸的影响(原因:https://www.cnblogs.com/Dar-/p/9379956.html),加大了模型训练的难度
ResNets 能够解决这一问题,训练非常深层的网络.它使得神经元之间隔层相连,弱化了每层之间的强联系
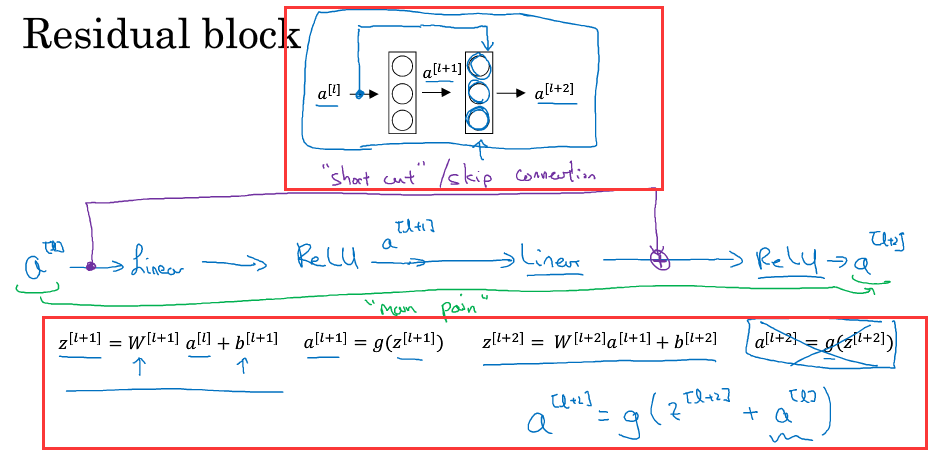
ReNets中使用了残差块(Residual block),有许多跳跃相连的神经元,具体如下:
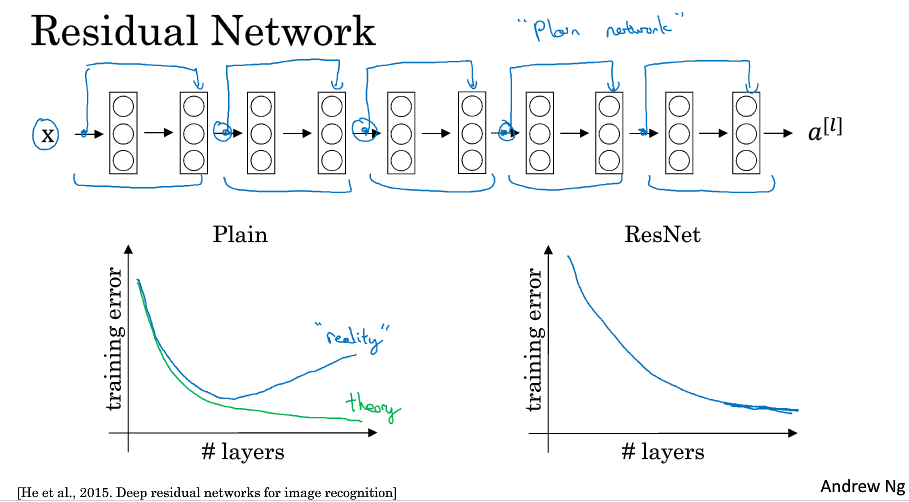
由多个Residual block构成Residual Network,一般的神经网络随着layer的增加,性能可能会发生下降,虽然理论上性能不会下降,但实际上回会下降.
而使用ResNet能够有更好的performance.
4.Why ResNets Work
为什么ResNets 很有用?
假设X为输入,经过多个NN后到达l层,得到a[l],
a[l+2]=g(w[l+2]a[l+2]+b[l+2] +a[l]),假设发生了梯度消失,即w[l+2]与b[l+2]接近0,则a[l+2]=g(a[l]),当a[l]>=0,激活函数为relu时,a[l+2]=a[l],
这弱化削减了神经元层之间的联系,使得隔层相连,从效果上说,忽略了l层后的两层,模型本身便能够容忍更多的NN.
且对于ResNets来说学习上面的恒等函数(a[l+2]=a[l])非常容易,所以尽管提升了网络的深度,但也不会影响性能
如果增加的网络结构学到了新的东西,就能提高网络性能.
当然,如果Residual blocks确实能训练得到非线性关系,那么也会忽略short cut,跟Plain Network起到同样的效果。
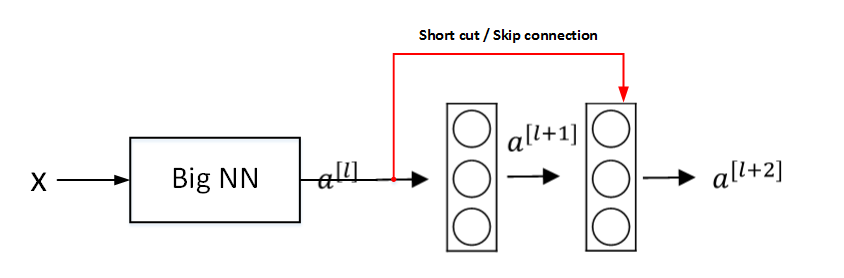
如果a[l+2]的维度与a[l]的维度不相同,就会引入一个Ws,让a[l]与Ws相乘得到一个维度与a[l+2]相同的维度,Ws可以通过训练得到,也可以直接固定

上图只在相同卷基层之间增加了skip connection,如上图实现部分的skip connection都是相同卷积层(前三个skip connection加在了 (3x3 conv, 64)上面,经过3x3 conv 128的时候,变为虚线(即没有添加),而后在后面连着都是3x3 conv 128的地方又连着做了三个skip connection,这样做的原因就是 保持 z(l+2) 与 a(l) 维度相同。
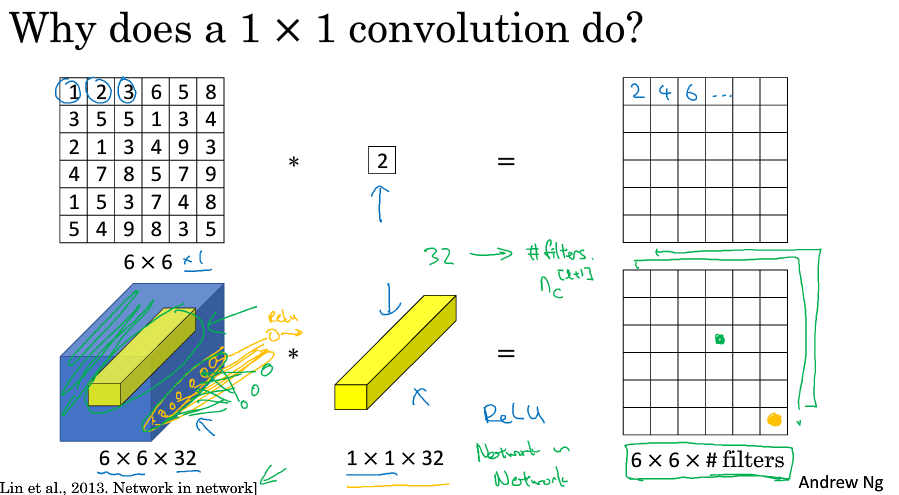
5.Network in Network and 1x1 Convolutions
1X1 convolutions即filter为1x1,类似一个乘积操作,可以起到一个降低channels数目的效果,(这个不是很理解,只要改变filter的个数不就可以对channels的数目进行一个调整吗)
1X1 convolution还可以起到一个类似全连接的效果,它对原图片进行了一个切片操作,然后与1x1xnc 中的nc个参数卷积,乘以权重之后,在relu后得到输出结果
1x1卷积应用:
- 维度压缩:使用目标维度的1×1 1×1 的卷积核个数。
- 增加非线性:保持与原维度相同的1×1 1×1 的卷积核个数。
6.Inception network motivation
在之前我们所学习的CNN中,filter的个数,size, pool的各种参数都是要由我们自己指定的, Inception能学习参数来帮助我们自动的去选择最好的filter,pool组合
如下图所示:我们可以将多个filter,pool组合进行一个same convolution
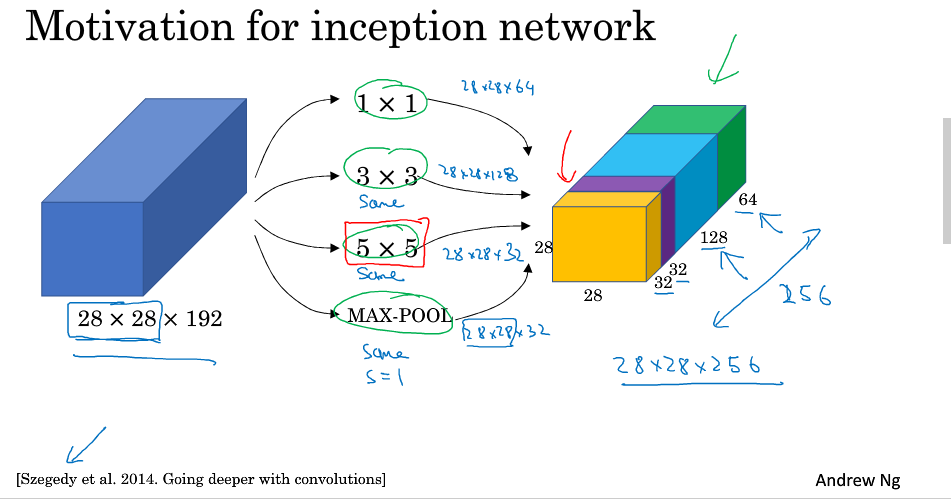
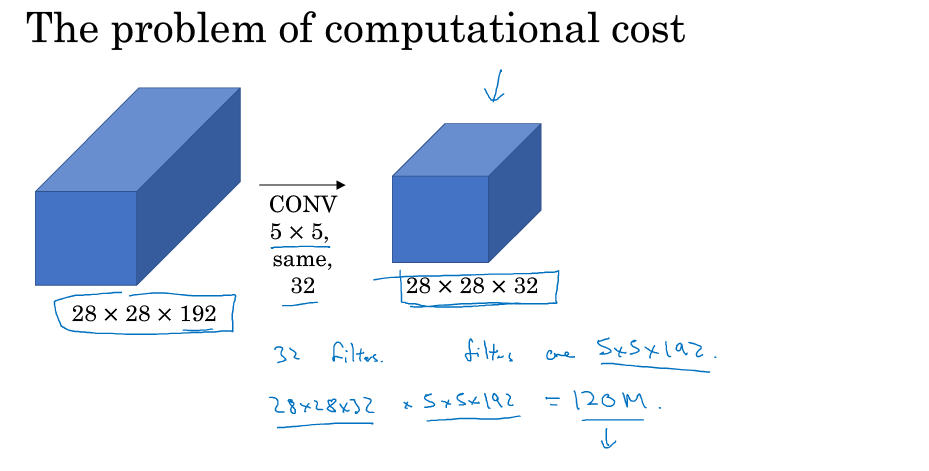
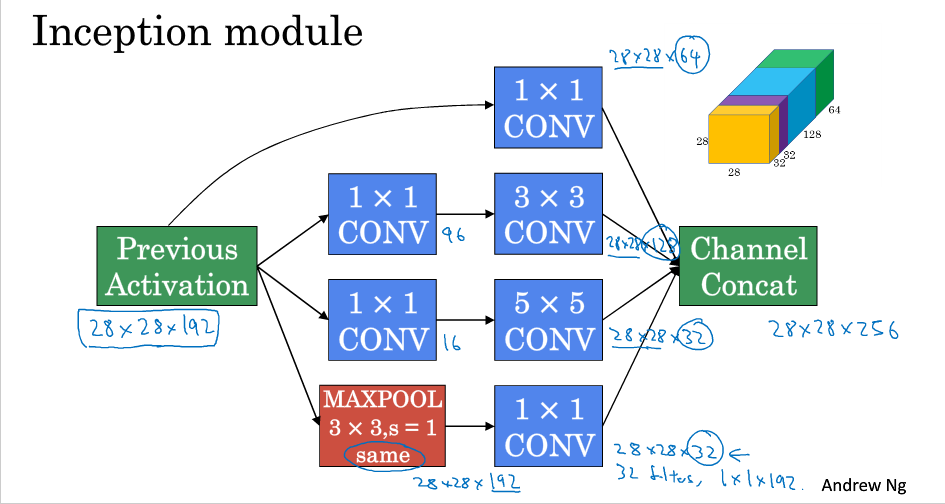
Inception也存在着一个问题:运算成本比较大,如下图,我们的运算量为5x5x192x28x28x32=1.2亿,为了解决这个问题,我们引入了之前所讲到的1x1 convolution
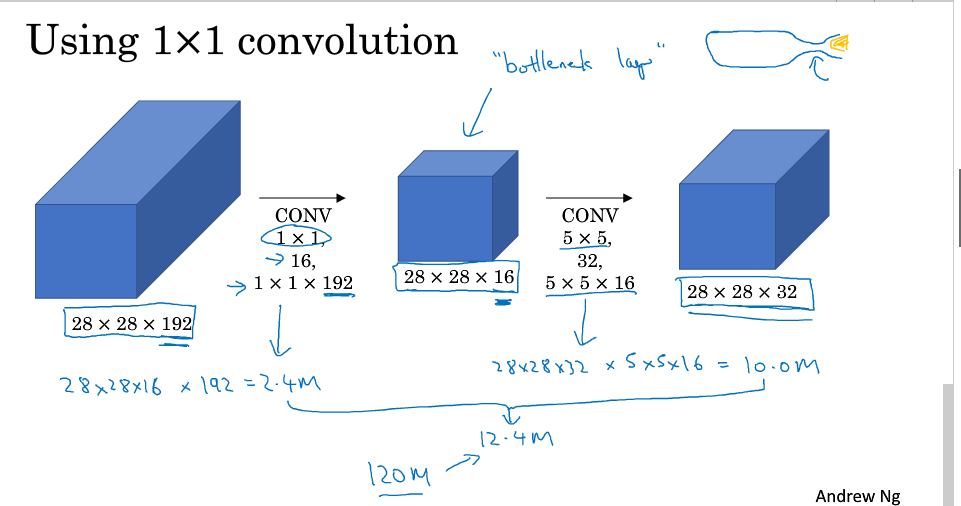
引入1x1 convolution之后运算量计算如下,结果为12.4百万,运算量比之前减少了接近1/10
具体看下其过程,第一步进行了一个1x1的convoltuion的得到的中间那一层叫做bottleneck layer(瓶颈层)
7.Inception network
Inception module如下:
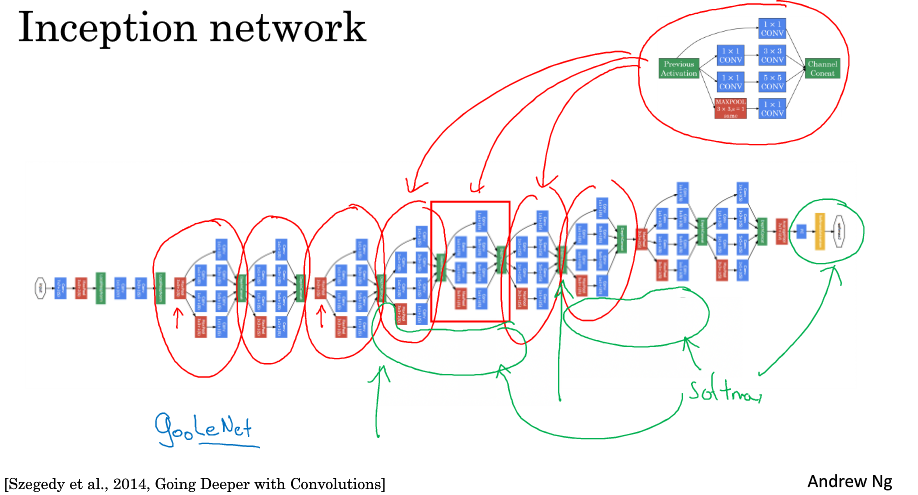
由多个Inception module组合得到Inception network
值得一提的是,中间层添加了很多的softmax分类器,用于防止过拟合,即:当进行inception network时候,各分支同样输出结果,旨在充分利用神经网络结构,在中间层即输出结果,最后对比各输出结果,从而寻找最佳输出结果对应的结构。
8.Using open-source Implementation
在训练所需要的模型过程中,我们可以从github上寻找已有的开源文件.....
9.Transfer Learning
之前以详细讲过,再补充一些:
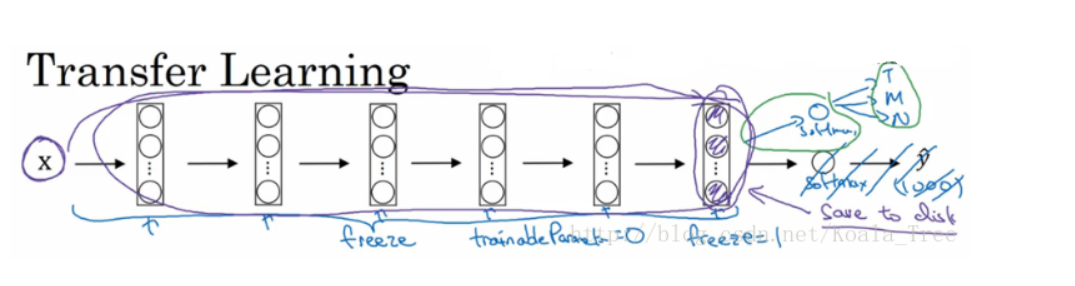
我们可以freeze部分所需要的结构
然后将前面需要freeze的部分权重结构等保存到本地,然后对输入先走一遍这些部分,将最后层神经元输出结果作为训练集,来训练自己新架构的层。
10.Data augamentation
数据增强
深度学习在计算机视觉上所存在的问题往往是不能获取足够的样本,为此,我们可以对所存在的样本进行一个处理来得到更多的样本
最常用的:可以对已经搜集到的样本进行一个mirroring,和random croping
用的很少基本不同的:对图片进行旋转,局部弯曲,修剪

还有一种比较常见的处理是Color shifting:即对图片的RGB通道数值进行随意增加或者减少,改变图片色调。
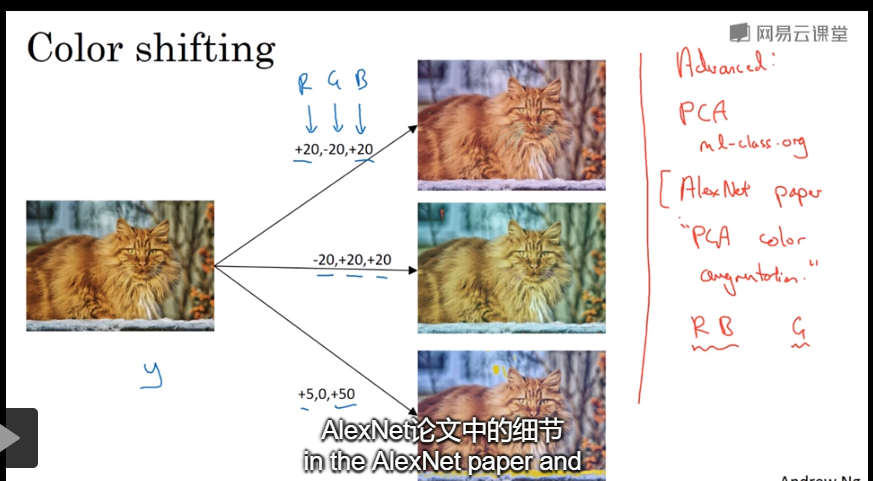
除了随意改变RGB通道数值外,还可以更有针对性地对图片的RGB通道进行PCA color augmentation,也就是对图片颜色进行主成分分析,
- PCA颜色增强:对图片的主色的变化较大,图片的次色变化较小,使总体的颜色保持一致。
。具体的PCA color augmentation做法可以查阅AlexNet的相关论文。
在训练模型的时候我们可以分2个线程分别进行data argumentation和training

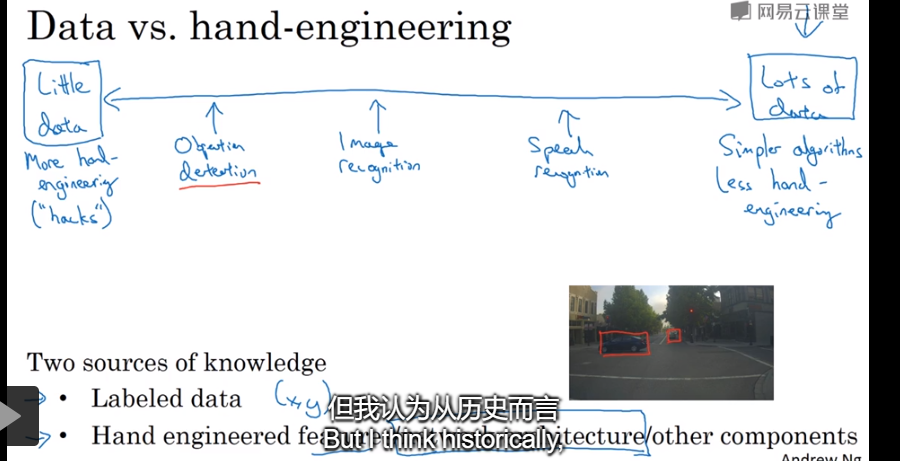
11.The state of computer vsion
构建不同的模型需要的数据量一般也不同,一般来说是Objection detection ,Image recognization, speech recognization所需要的数据量越来越多
当我们拥有的数据越少,我们可能需要更多的手工工程,而当我们拥有的数据越多,我们可以用更加简单的算法以及更少的手工工程
一些有帮助你提高模型的性能的小技巧(可用与比赛):
Ensembling :训练几个独立的网络,然后用他们的平均输出来做一个预测,但这占用的内存比较多
Multi-crop at test time:裁取图片并镜像给分类器作为输入,计算结过的平均值作为预测.
但是由于这两种方法计算成本较大,一般不适用于实际项目开发。

我们还可以使用开源代码来帮助我们的项目:
