
一个map task处理一个切片Split,切片是一个范围的数据,和blocksize大小没有必然关系。
1.每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2.写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
3.等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
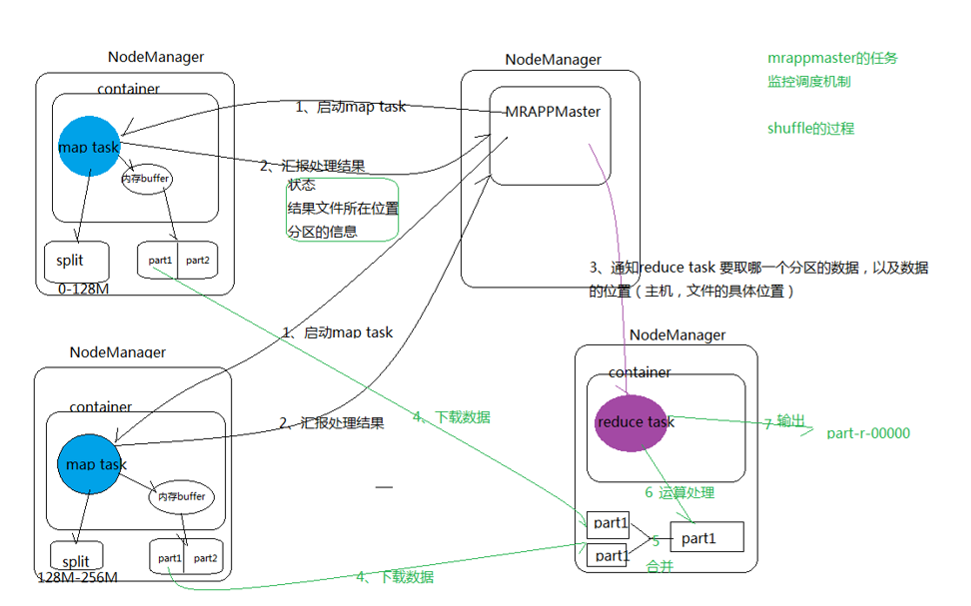
1.Reducer通过Http方式得到输出文件的分区。
2.YarnChild为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内存或磁盘。一个Map任务完成,Reduce就开始复制输出。
3.排序阶段合并map输出。然后走Reduce阶段。


MapReduce的详细过程如图:

MRAppMaster的任务监控调度机制以及Shuffle的过程如图:
最后,将MapReduce的整个处理流程进行一下总结:
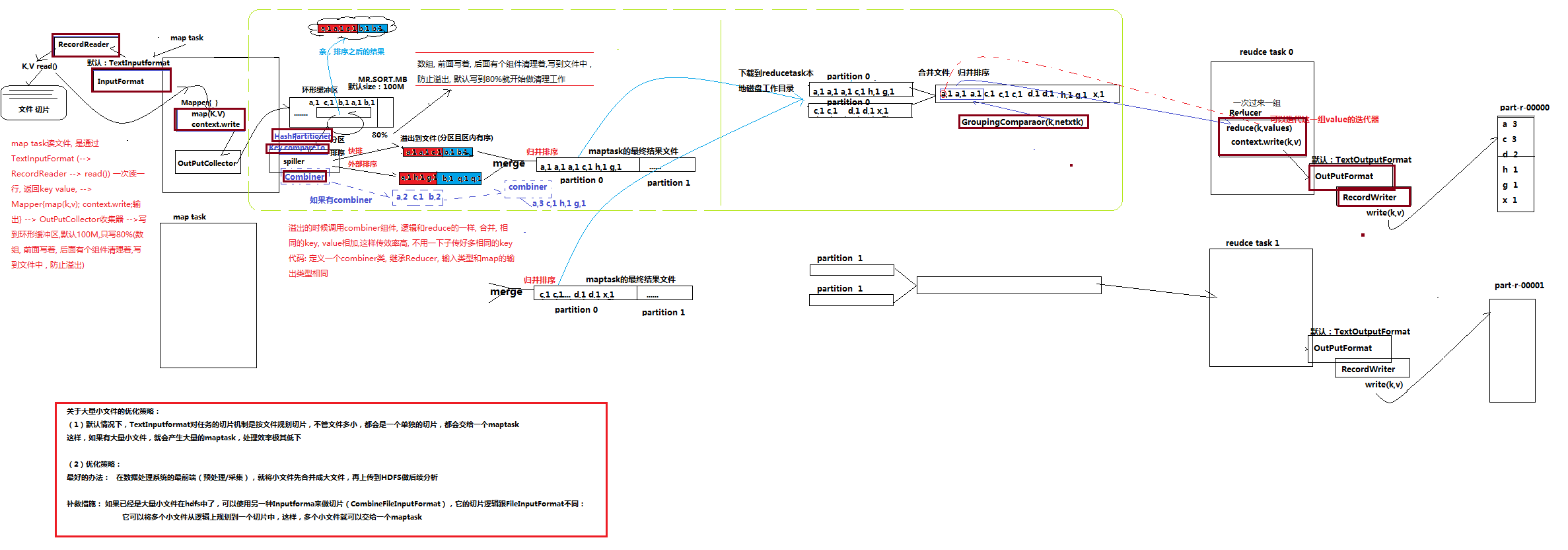
1、 maptask收集我们的map()方法输出的kv对,放到内存缓冲区中
2、 从内存缓冲区不断溢出本地磁盘文件,可能会溢出多个文件
3、 多个溢出文件会被合并成大的溢出文件
4、 在溢出过程中,及合并的过程中,都要调用partitoner进行分组和针对key进行排序
5、 reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据
6、 reducetask会取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)
7、 合并成大文件后,shuffle的过程也就结束了,后面进入reducetask的逻辑运算过程(从文件中取出一个一个的键值对group,调用用户自定义的reduce()方法)
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。
缓冲区的大小可以通过参数调整, 参数:io.sort.mb 默认100M。
对应的部分代码的写法:
// 设置Combiner,Combiner的写法和Reducer完全一样,所以可以直接调用Reducer的类(最好别写) job.setCombiner(FlowSumAreaReducer.class); //如果不设置InputFormat,它默认使用的是TextInputFormat //如果有大量小文件,不管文件多小都会形成一个文件切片,由于一个切片对应一个MapTask,因此会造成好多MapTask //CombineTextInputFormat可以将多个小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个MapTask job.setInputFormatClass(CombineTextInputFormat.class); CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); CombineTextInputFormat.setMinInputSplitSize(job, 2097152);