1,Application
application(应用)其实就是用spark-submit提交的程序。比方说spark examples中的计算pi的SparkPi。一个application通常包含三部分:从数据源(比方说HDFS)取数据形成RDD,通过RDD的transformation和action进行计算,将结果输出到console或者外部存储(比方说collect收集输出到console)。
2,Driver
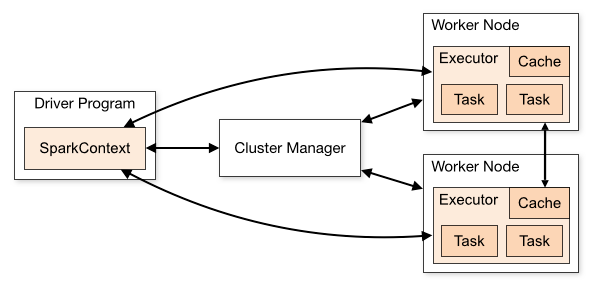
Spark中的driver感觉其实和yarn中Application Master的功能相类似。主要完成任务的调度以及和executor和cluster manager进行协调。有client和cluster两种模式。client模式driver在任务提交的机器上运行,而cluster模式会随机选择集群中的一台机器启动driver。从spark官网截图的一张图可以大致了解driver的功能。
3,Job
Spark中的Job和MR中Job不一样不一样。MR中Job主要是Map或者Reduce Job。而Spark的Job其实很好区别,一个action算子就算一个Job,比方说count,first等。
4, Task
Task是Spark中最新的执行单元。RDD一般是带有partitions的,每个partition的在一个executor上的执行可以任务是一个Task。
5, Stage
Stage概念是spark中独有的。一般而言一个Job会切换成一定数量的stage。各个stage之间按照顺序执行。至于stage是怎么切分的,首选得知道spark论文中提到的narrow dependency(窄依赖)和wide dependency( 宽依赖)的概念。其实很好区分,看一下父RDD中的数据是否进入不同的子RDD,如果只进入到一个子RDD则是窄依赖,否则就是宽依赖。宽依赖和窄依赖的边界就是stage的划分点。从spark的论文中的两张截图,可以清楚的理解宽窄依赖以及stage的划分。
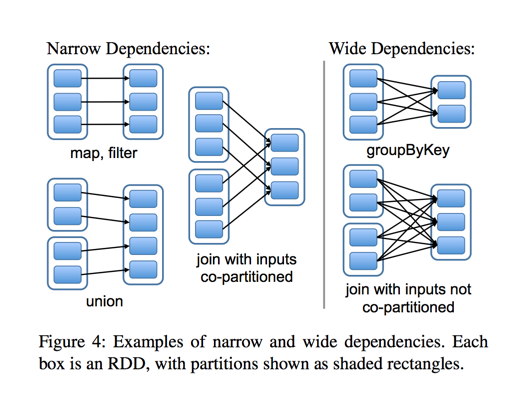
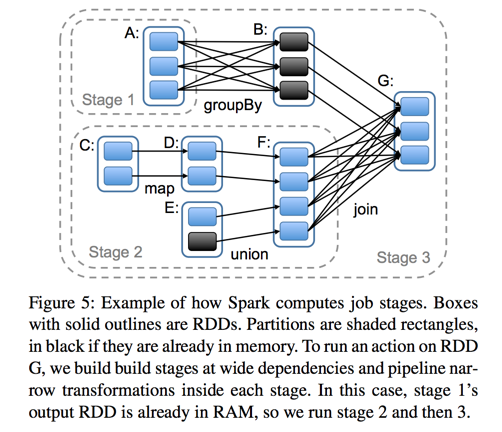
至于为什么这么划分,主要是宽窄依赖在容错恢复以及处理性能上的差异(宽依赖需要进行shuffer)导致的。