A high-throughput distributed messaging system.
--Apache Kafka
Kafka作为时下最流行的开源消息系统,被广泛地应用在数据缓冲、异步通信、汇集日志、系统解耦等方面。相比较于RocketMQ等其他常见消息系统,Kafka在保障了大部分功能特性的同时,还提供了超一流的读写性能。
本文将针对Kafka性能方面进行简单分析,首先简单介绍一下Kafka的架构和涉及到的名词:
-
Topic:用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上。
-
Partition:是Kafka中横向扩展和一切并行化的基础,每个Topic都至少被切分为1个Partition。
-
Offset:消息在Partition中的编号,编号顺序不跨Partition。
-
Consumer:用于从Broker中取出/消费Message。
-
Producer:用于往Broker中发送/生产Message。
-
Replication:Kafka支持以Partition为单位对Message进行冗余备份,每个Partition都可以配置至少1个Replication(当仅1个Replication时即仅该Partition本身)。
-
Leader:每个Replication集合中的Partition都会选出一个唯一的Leader,所有的读写请求都由Leader处理。其他Replicas从Leader处把数据更新同步到本地,过程类似大家熟悉的MySQL中的Binlog同步。
-
Broker:Kafka中使用Broker来接受Producer和Consumer的请求,并把Message持久化到本地磁盘。每个Cluster当中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作。
-
ISR(In-Sync Replica):是Replicas的一个子集,表示目前Alive且与Leader能够“Catch-up”的Replicas集合。由于读写都是首先落到Leader上,所以一般来说通过同步机制从Leader上拉取数据的Replica都会和Leader有一些延迟(包括了延迟时间和延迟条数两个维度),任意一个超过阈值都会把该Replica踢出ISR。每个Partition都有它自己独立的ISR。
以上几乎是我们在使用Kafka的过程中可能遇到的所有名词,同时也无一不是最核心的概念或组件,感觉到从设计本身来说,Kafka还是足够简洁的。这次本文围绕Kafka优异的吞吐性能,逐个介绍一下其设计与实现当中所使用的各项“黑科技”。
Broker
不同于Redis和MemcacheQ等内存消息队列,Kafka的设计是把所有的Message都要写入速度低容量大的硬盘,以此来换取更强的存储能力。实际上,Kafka使用硬盘并没有带来过多的性能损失,“规规矩矩”的抄了一条“近道”。
首先,说“规规矩矩”是因为Kafka在磁盘上只做Sequence I/O,由于消息系统读写的特殊性,这并不存在什么问题。关于磁盘I/O的性能,引用一组Kafka官方给出的测试数据(Raid-5,7200rpm):
Sequence I/O: 600MB/s
Random I/O: 100KB/s
所以通过只做Sequence I/O的限制,规避了磁盘访问速度低下对性能可能造成的影响。
-----------------------------原理:
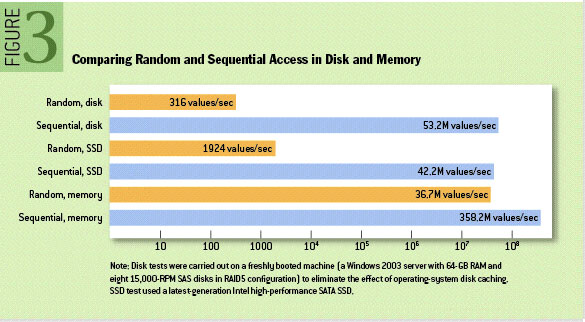
接下来我们再聊一聊Kafka是如何“抄近道的”。
首先,Kafka重度依赖底层操作系统提供的PageCache功能。当上层有写操作时,操作系统只是将数据写入PageCache,同时标记Page属性为Dirty。当读操作发生时,先从PageCache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用。同时如果有其他进程申请内存,回收PageCache的代价又很小,所以现代的OS都支持PageCache。
使用PageCache功能同时可以避免在JVM内部缓存数据,JVM为我们提供了强大的GC能力,同时也引入了一些问题不适用与Kafka的设计。
• 如果在Heap内管理缓存,JVM的GC线程会频繁扫描Heap空间,带来不必要的开销。如果Heap过大,执行一次Full GC对系统的可用性来说将是极大的挑战。
• 所有在在JVM内的对象都不免带有一个Object Overhead(千万不可小视),内存的有效空间利用率会因此降低。
• 所有的In-Process Cache在OS中都有一份同样的PageCache。所以通过将缓存只放在PageCache,可以至少让可用缓存空间翻倍。
• 如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的PageCache依然可以继续使用。
PageCache还只是第一步,Kafka为了进一步的优化性能还采用了Sendfile技术。在解释Sendfile之前,首先介绍一下传统的网络I/O操作流程,大体上分为以下4步。
-
OS 从硬盘把数据读到内核区的PageCache。
-
用户进程把数据从内核区Copy到用户区。
-
然后用户进程再把数据写入到Socket,数据流入内核区的Socket Buffer上。
-
OS 再把数据从Buffer中Copy到网卡的Buffer上,这样完成一次发送。
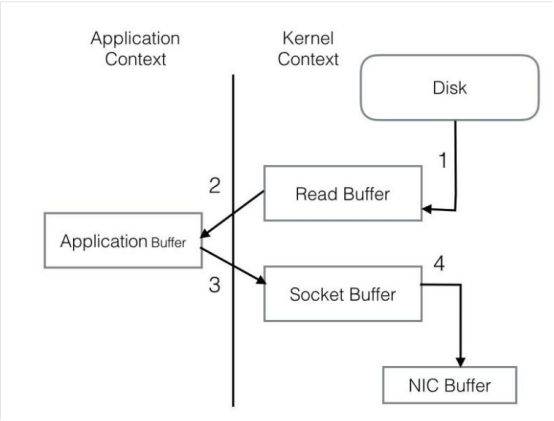
整个过程共经历两次Context Switch,四次System Call。同一份数据在内核Buffer与用户Buffer之间重复拷贝,效率低下。其中2、3两步没有必要,完全可以直接在内核区完成数据拷贝。这也正是Sendfile所解决的问题,经过Sendfile优化后,整个I/O过程就变成了下面这个样子。 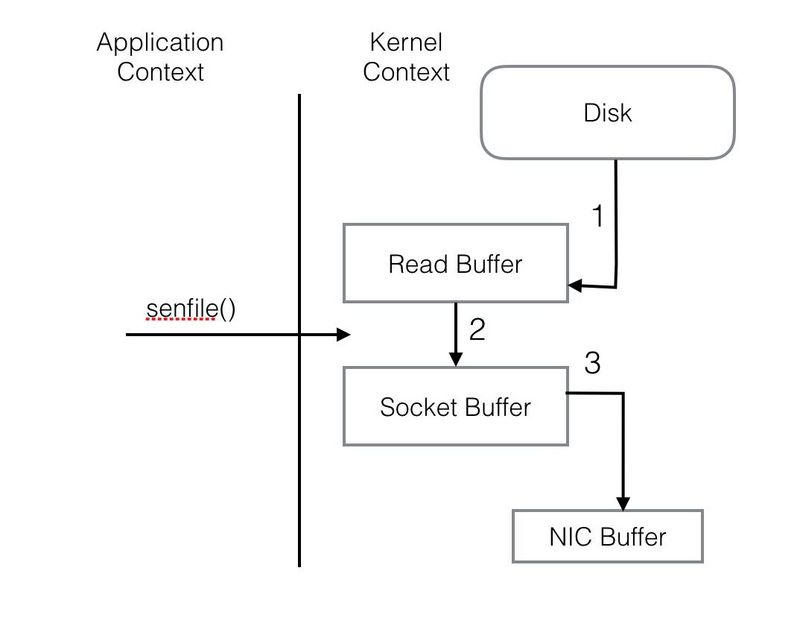
通过以上的介绍不难看出,Kafka的设计初衷是尽一切努力在内存中完成数据交换,无论是对外作为一整个消息系统,或是内部同底层操作系统的交互。如果Producer和Consumer之间生产和消费进度上配合得当,完全可以实现数据交换零I/O。这也就是我为什么说Kafka使用“硬盘”并没有带来过多性能损失的原因。下面是我在生产环境中采到的一些指标。
(20 Brokers, 75 Partitions per Broker, 110k msg/s)
此时的集群只有写,没有读操作。10M/s左右的Send的流量是Partition之间进行Replicate而产生的。从recv和writ的速率比较可以看出,写盘是使用Asynchronous+Batch的方式,底层OS可能还会进行磁盘写顺序优化。而在有Read Request进来的时候分为两种情况,第一种是内存中完成数据交换。
Send流量从平均10M/s增加到了到平均60M/s,而磁盘Read只有不超过50KB/s。PageCache降低磁盘I/O效果非常明显。


接下来是读一些收到了一段时间,已经从内存中被换出刷写到磁盘上的老数据。
其他指标还是老样子,而磁盘Read已经飚高到40+MB/s。此时全部的数据都已经是走硬盘了(对硬盘的顺序读取OS层会进行Prefill PageCache的优化)。依然没有任何性能问题。

Tips
-
Kafka官方并不建议通过Broker端的log.flush.interval.messages和log.flush.interval.ms来强制写盘,认为数据的可靠性应该通过Replica来保证,而强制Flush数据到磁盘会对整体性能产生影响。
-
可以通过调整/proc/sys/vm/dirty_background_ratio和/proc/sys/vm/dirty_ratio来调优性能。
-
脏页率超过第一个指标会启动pdflush开始Flush Dirty PageCache。
-
脏页率超过第二个指标会阻塞所有的写操作来进行Flush。
-
根据不同的业务需求可以适当的降低dirty_background_ratio和提高dirty_ratio。
Partition
Partition是Kafka可以很好的横向扩展和提供高并发处理以及实现Replication的基础。
扩展性方面。首先,Kafka允许Partition在集群内的Broker之间任意移动,以此来均衡可能存在的数据倾斜问题。其次,Partition支持自定义的分区算法,例如可以将同一个Key的所有消息都路由到同一个Partition上去。 同时Leader也可以在In-Sync的Replica中迁移。由于针对某一个Partition的所有读写请求都是只由Leader来处理,所以Kafka会尽量把Leader均匀的分散到集群的各个节点上,以免造成网络流量过于集中。
并发方面。任意Partition在某一个时刻只能被一个Consumer Group内的一个Consumer消费(反过来一个Consumer则可以同时消费多个Partition),Kafka非常简洁的Offset机制最小化了Broker和Consumer之间的交互,这使Kafka并不会像同类其他消息队列一样,随着下游Consumer数目的增加而成比例的降低性能。此外,如果多个Consumer恰巧都是消费时间序上很相近的数据,可以达到很高的PageCache命中率,因而Kafka可以非常高效的支持高并发读操作,实践中基本可以达到单机网卡上限。
不过,Partition的数量并不是越多越好,Partition的数量越多,平均到每一个Broker上的数量也就越多。考虑到Broker宕机(Network Failure, Full GC)的情况下,需要由Controller来为所有宕机的Broker上的所有Partition重新选举Leader,假设每个Partition的选举消耗10ms,如果Broker上有500个Partition,那么在进行选举的5s的时间里,对上述Partition的读写操作都会触发LeaderNotAvailableException。
再进一步,如果挂掉的Broker是整个集群的Controller,那么首先要进行的是重新任命一个Broker作为Controller。新任命的Controller要从Zookeeper上获取所有Partition的Meta信息,获取每个信息大概3-5ms,那么如果有10000个Partition这个时间就会达到30s-50s。而且不要忘记这只是重新启动一个Controller花费的时间,在这基础上还要再加上前面说的选举Leader的时间 -_-!!!!!!
此外,在Broker端,对Producer和Consumer都使用了Buffer机制。其中Buffer的大小是统一配置的,数量则与Partition个数相同。如果Partition个数过多,会导致Producer和Consumer的Buffer内存占用过大。
Tips
-
Partition的数量尽量提前预分配,虽然可以在后期动态增加Partition,但是会冒着可能破坏Message Key和Partition之间对应关系的风险。
-
Replica的数量不要过多,如果条件允许尽量把Replica集合内的Partition分别调整到不同的Rack。
-
尽一切努力保证每次停Broker时都可以Clean Shutdown,否则问题就不仅仅是恢复服务所需时间长,还可能出现数据损坏或其他很诡异的问题。
Producer
Kafka的研发团队表示在0.8版本里用Java重写了整个Producer,据说性能有了很大提升。我还没有亲自对比试用过,这里就不做数据对比了。本文结尾的扩展阅读里提到了一套我认为比较好的对照组,有兴趣的同学可以尝试一下。
其实在Producer端的优化大部分消息系统采取的方式都比较单一,无非也就化零为整、同步变异步这么几种。
Kafka系统默认支持MessageSet,把多条Message自动地打成一个Group后发送出去,均摊后拉低了每次通信的RTT。而且在组织MessageSet的同时,还可以把数据重新排序,从爆发流式的随机写入优化成较为平稳的线性写入。
此外,还要着重介绍的一点是,Producer支持End-to-End的压缩。数据在本地压缩后放到网络上传输,在Broker一般不解压(除非指定要Deep-Iteration),直至消息被Consume之后在客户端解压。
当然用户也可以选择自己在应用层上做压缩和解压的工作(毕竟Kafka目前支持的压缩算法有限,只有GZIP和Snappy),不过这样做反而会意外的降低效率!!!! Kafka的End-to-End压缩与MessageSet配合在一起工作效果最佳,上面的做法直接割裂了两者间联系。至于道理其实很简单,压缩算法中一条基本的原理“重复的数据量越多,压缩比越高”。无关于消息体的内容,无关于消息体的数量,大多数情况下输入数据量大一些会取得更好的压缩比。
不过Kafka采用MessageSet也导致在可用性上一定程度的妥协。每次发送数据时,Producer都是send()之后就认为已经发送出去了,但其实大多数情况下消息还在内存的MessageSet当中,尚未发送到网络,这时候如果Producer挂掉,那就会出现丢数据的情况。
为了解决这个问题,Kafka在0.8版本的设计借鉴了网络当中的ack机制。如果对性能要求较高,又能在一定程度上允许Message的丢失,那就可以设置request.required.acks=0 来关闭ack,以全速发送。如果需要对发送的消息进行确认,就需要设置request.required.acks为1或-1,那么1和-1又有什么区别呢?这里又要提到前面聊的有关Replica数量问题。如果配置为1,表示消息只需要被Leader接收并确认即可,其他的Replica可以进行异步拉取无需立即进行确认,在保证可靠性的同时又不会把效率拉得很低。如果设置为-1,表示消息要Commit到该Partition的ISR集合中的所有Replica后,才可以返回ack,消息的发送会更安全,而整个过程的延迟会随着Replica的数量正比增长,这里就需要根据不同的需求做相应的优化。
Tips
-
Producer的线程不要配置过多,尤其是在Mirror或者Migration中使用的时候,会加剧目标集群Partition消息乱序的情况(如果你的应用场景对消息顺序很敏感的话)。
-
0.8版本的request.required.acks默认是0(同0.7)。
Consumer
Consumer端的设计大体上还算是比较常规的。
• 通过Consumer Group,可以支持生产者消费者和队列访问两种模式。
• Consumer API分为High level和Low level两种。前一种重度依赖Zookeeper,所以性能差一些且不自由,但是超省心。第二种不依赖Zookeeper服务,无论从自由度和性能上都有更好的表现,但是所有的异常(Leader迁移、Offset越界、Broker宕机等)和Offset的维护都需要自行处理。
• 大家可以关注下不日发布的0.9 Release。开发人员又用Java重写了一套Consumer。把两套API合并在一起,同时去掉了对Zookeeper的依赖。据说性能有大幅度提升哦~~
Tips
强烈推荐使用Low level API,虽然繁琐一些,但是目前只有这个API可以对Error数据进行自定义处理,尤其是处理Broker异常或由于Unclean Shutdown导致的Corrupted Data时,否则无法Skip只能等着“坏消息”在Broker上被Rotate掉,在此期间该Replica将会一直处于不可用状态。
扩展阅读
Sendfile: https://www.ibm.com/developerworks/cn/java/j-zerocopy/
So what’s wrong with 1975 programming: https://www.varnish-cache.org/trac/wiki/ArchitectNotes
Benchmarking: https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines