前言: 这篇文章主要对两篇论文进行综述,一篇是美国一些知名的数据管理领域的专家学者从专业的研究角度出发联合发布的《大数据白皮书》,另一篇是孟晓峰和慈祥的《大数据管理:概念、技术与挑战》[1]。前者介绍了大数据的产生、分析了大数据的处理流程,并提出了大数据所面临的若干挑战,而后者介绍了大数据的基本概念,阐述其同传统数据库的区别,对大数据处理框架进行了详细解析,并展开介绍了大数据时代不可或缺的云计算技术和工具。同样,在论文的最后给出了大数据时代面临的新挑战。由于后者是在前者的基础上完成的,与前者有很多重复的内容,同时又对云计算等方面做出了更进一步的阐述,因此,本篇文章以《大数据白皮书》的结构为主线,将孟的论文中涉及到的其他内容(如大数据的基本概念、云计算等内容)穿插在合适的位置,进行统一综述。
摘要:数据驱动型决策的前景正在获得越来越多人的认可,人们对“大数据”这个概念的热情也越来越高。大数据的发展前景是毋庸置疑的。然而,目前其发展潜力与实现之间仍然存在着巨大的差距。本文介绍了大数据处理的不同流程、处理框架、关键技术和处理工具,最终引出了大数据分析过程中将面临的挑战并给出解决相应问题的部分思路。
Abstract: The prospect of data-driven decision-making is gaining more and more recognition and the passion for the concept of big data is growing rapidly. Big data development prospects are beyond doubt. However, recently there is still a huge gap between its development potential and its realization. This article introduces the different processes of big data pipelines, processing frameworks, key technologies and processing tools, and finally introduces the challenges that big data analysis will face and gives some ideas to solve the corresponding problems.
关键词:大数据;数据分析;云计算;处理流程
key words: big data; data analysis; cloud computing; processing pipelines
1.1 背景
现如今,我们正生活在数据的汹涌浪涛之中,数据正在以前所未有的规模增长着。 在以前,决策的产生或基于猜测,或精心构建的现实模型,但现在人们完全可以依靠数据本身做出合理的决策。这样的大数据分析推动了我们现代社会的几乎所有方面,包括移动服务,零售,制造业,金融服务,生命科学和物理科学。
1.2 大数据的4V定义
虽然大数据的潜在价值巨大且真实,而且已经取得了一些初步的成功,但若要充分发挥这种潜力,仍然有许多技术挑战需要解决。数据的庞大规模是最明显,最主要的挑战。但是,这并不是唯一的挑战。行业分析公司指出,大数据面临的挑战不仅体现在数量(Volume)方面,还在于多样性(Variety)和速度(Velocity)[2],因此我们不应该只关注其中的第一个(Volume)。其中,多样性(Variety)通常意味着数据类型、表示方法和语义解释的异构性。速度(Velocity)是指数据到达的和它必须被处理速度。虽然这三个要素很重要,但却没有包含隐私和可用性等其他要求。
除此3V定义之外,孟[1]的论文中还添加了另外一个V,组成为4V定义。但人们对第4个V说法不一,国际数据公司认为大数据应该有价值性(Value),而IBM[3]公司认为 数据必然具有真实性(Veracity)。不必过度地拘于具体的定义,在把握3V定义的基础上,适当地考虑4V即可。
1.3 传统数据库与大数据的区别
a. 数据规模:传统数据库处理对象通常以MB为基本单位,而大数据常常以GB甚至TB,PB为基本处理单位
b. 数据类型:传统数据库仅有一种或几种,且以结构化数据为主。大数据中的数据类型种类繁多,数以千计,不仅包含结构化,还包括半结构化和非结构化数据
c. 模式和数据的关系:传统数据库先有模式再有数据。大数据的模式随着数据量的增长而不断演变。
d. 处理对象:传统数据库的数据仅作为处理对象而存在,而大数据的数据作为资源来辅助解决其他领域的问题。
e. 处理工具:大数据的数据不仅仅只是工程处理的对象,传统的3种范式(实验、理论和计算)无法很好的发挥作用,需要探索第4种范式。4中范式的比较如表1所示:
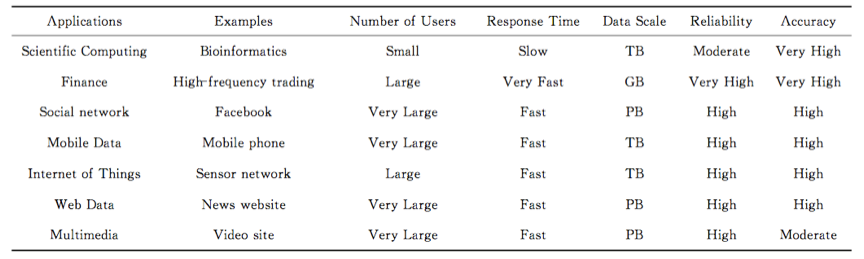
表1 典型大数据应用的比较
1.4 大数据的产生
人类社会的数据产生方式大致经历3个阶段,其中第三个阶段(感知式系统阶段)导致了大数据的产生。这3个阶段分别是:
运营式系统阶段:数据库出现在这个阶段,数据伴随着一定的运营活动产生并记录在数据库中。
用户原创内容阶段:Web 2.0时代,数据呈爆炸式增长。
感知式系统阶段:感知式系统被广泛使用。传感器被大量使用,数据的产生方式是自动的。
总体而言,数据的产生经历了被动、主动到自动的3个阶段。
2. 大数据的处理流程
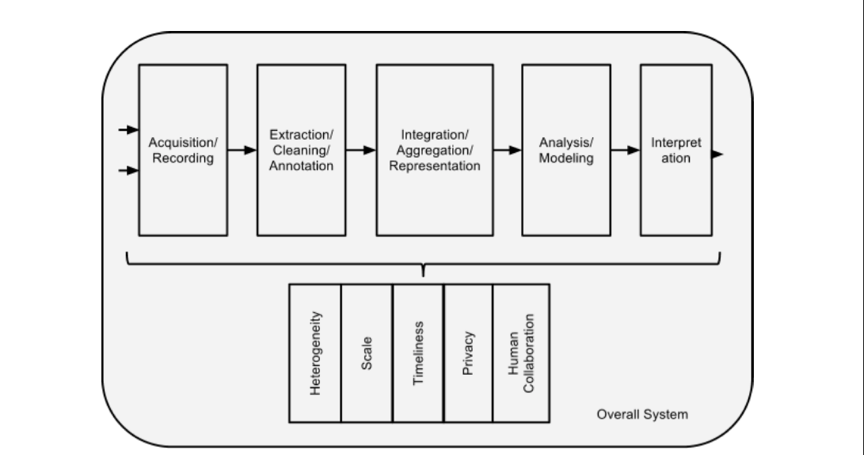
图1 大数据处理流程
大数据分析涉及多个不同的阶段,如图1所示,每个阶段都会带来挑战。不幸的是,许多人只关注分析/建模阶段(虽然这个阶段至关重要,但是如果没有数据分析管道的其他阶段,这个阶段便无用武之地。即使是在分析阶段,我们对在多个用户程序并发运行的多租户集群的情况下的复杂性的了解也很少。许多重大挑战超出了分析阶段。例如,大数据必须在一定情境下进行管理,这可能是嘈杂的,异构的,且不包括前期模型。这样做会增加追踪出处和处理不确定性和错误的需要。这些对于成功至关重要,却很少像大数据一样提及。同样,数据分析阶段的问题通常也不会全部提前摆出来。我们可能需要根据数据找出好的问题。这样做需要更智能的系统,并且更好地支持用户与数据分析处理流程的交互。事实上,我们现在的一个主要的瓶颈就是能够对这些问题提问并分析的人的数量。通过支持对数据的许多层次的参与(并不都需要深入的数据库专业知识),我们可以通过大幅增加这个数字。解决这类问题的方案不是像往常那样逐渐改进业务,这个工业可以自己做。相反,他们要求我们从根本上重新思考我们如何处理数据分析。
2.1 数据获取与记录
大数据不是从天而降的,它产生于一些数据生成源。我们周围的世界,从老年人的心率,我们呼吸的空气中的毒素,到规划的SKA望远镜,这些每天会产生高达100万TB的原始数据。 同样,科学实验和模拟可以很容易地产生PB级的数据。
这些数据大部分是没有意义的,数量级可以被过滤和压缩。 一方面的挑战是如何定义这些过滤器,以避免丢弃有用的信息。另一方面挑战是自动生成正确的元数据来描述哪些数据被记录以及这些数据是如何被记录和测量的。
2.2 信息提取和清洁
通常情况下,不能直接对收集好的信息进行分析。相反,我们需要一个信息提取过程,从底层资源中提取所需信息,并通过一种适合分析的结构化形式来表示。正确而完全地做到这点是一个持续的技术挑战,而这样的提取通常是高度依赖于应用的。
2.3 数据整合,聚合和表示
鉴于数据洪流的异构性,仅记录它并将其放入存储库是不够的。例如,加入我们有一系列科学实验的数据。如果我们在一个数据库中只有一堆数据集,那么任何人都不可能找到任何这些数据,更不用说重复使用这些数据了。如果有足够的元数据,仍然有一些希望,但即便如此,由于实验细节和数据记录结构的差异,挑战依然存在。
2.4 查询处理,数据建模和分析
对大数据进行查询和挖掘的方法与传统的小样本统计分析有着根本的区别。 大数据往往是有噪声,动态,异构,相互关联且不可信的。尽管如此,即使是噪声大的大数据也可能比小样本更有价值。
挖掘需要集成的,清理的,可信赖的,高效可访问的数据,声明式查询和挖掘接口,可扩展挖掘算法和大数据计算环境。同时,数据挖掘本身也可以用来帮助提高数据的质量和可信度,理解其语义,并提供智能查询功能。下一代的大数据还支持实时处理的交互式数据分析。
目前的大数据分析存在的一个问题是,提供SQL查询功能的数据库系统与执行各种形式的非SQL处理的分析包(如数据挖掘和统计分析)之间的协调。如今的分析师需要从数据库中导出数据,然后执行非SQL过程,再将数据带回,这个过程是麻烦而枯燥的。声明性查询语言与这些包的功能之间的紧密耦合将有利于分析的表达性和性能。
2.5 解释
如果用户无法理解结果,那么具有分析大数据的能力是没有意义的。提供分析结果的决策者必须解释这些结果。仅仅提供结果是不够的。相反,必须提供补充信息,说明每个结果是基于哪些输入、如何得出的。这种补充信息被称为(结果)数据的来源。通过研究如何最好地捕获,存储和查询出处,结合捕获足够的元数据的技术,我们可以创建一个基础结构,使用户能解释获得的分析结果,并用不同的假设,参数,或数据集重复分析过程。
3. 大数据处理框架
大数据处理模式主要可以分为两种:流处理模式和批处理模式。
3.1 流处理
流处理处理模式将数据视为流,当数据到来时就立刻处理并返回所需结果。流处理的过程基本在内存中完成,其处理方式更多依赖于在内存中设计巧妙的概要数据结构,主要瓶颈是内存容量。以PCM(相变存储器)为代表的存储级内存设备的出现或许可以打破这个瓶颈。比较有代表性的开源系统有:Twitter的Storm、Yahoo的S4以及Linkedin的Kafka等。
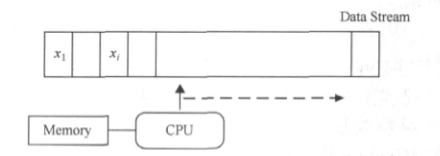
图2 基本的数据流模型
3.2 批处理
以Google的MapReduce为代表,完整的MapReduce过程如图3所示:

图3 MapReduce基本原理
批处理的核心设计思想在于:1. 分而治之 2. 将计算推到数据,而非相反。
在实际场景下,常常不是简单使用某一种,二是将二者结合起来。很多互联网公司将业务划分为在线、近线和离线,可以基于这种划分应用不同的处理模式。
4. 大数据关键技术
大数据需要多种技术的协同。文件系统提供最底层的存储能力的支持。数据库提供数据管理服务。
4.1 云计算
云计算涉及到的技术很多,图4是Google云计算技术的介绍,从中可以对云计算有更清晰的认识。

图4 google技术演化图
4.1.1 文件系统
基于“系统组件失败是一种常态而非异常”的思想,Google研发了GFS。这是一个构建在大量廉价服务器上的可扩展分布式文件系统,采用主从结构,主要针对文件较大,且读远大于写的应用场景。后来在Google对GFS级你醒了重新设计,解决了单点故障、海量小文件等问题。许多其他企业的文件系统都是借鉴了GFS。
4.1.2 数据库系统
由于数据的数量(大)、多样性、设计理念的冲突、数据库事务处理苛刻的ACID要求等原因,大数据不可能直接采用关系型数据库。为了应对这个挑战,产生了NoSQL数据库。NoSQL数据库具有如下特点:模式自由、支持简易备份、简单的应用程序接口、最终一致性、支持海量数据。其与关系型数据看对比如下图所示:

表2 NoSQL数据库和关系数据库对比
4.1.3 索引与查询技术
NoSQL数据库针对逐渐的查询效率一般比较高,因此NoSQL数据库上的查询优化研究主要有两个思路:
- 采用MapReduce秉性技术优化多值查询
- 采用索引技术优化多值查询
总体而言,在NoSQL数据库上的查询优化技术都并不成熟,有很多关键性问题亟待解决。
4.1.4 数据分析技术
实时数据处理是大数据分析的一个核心需求,主要有3个思路:
- 采用流处理模式
- 采用批处理模式
- 二者的融合:主要思路是利用MapReduce模型实现流处理。
4.2 大数据处理工具
Hadoop是当前最为流行的大数据处理平台,它已经成为大数据处理工具事实上的标准。它是包括文件系统(HDFS),数据库(HBase、Cassandra)、数据处理(MapReduce)等功能模块的完整生态系统。下图归纳了现今主流的处理平台和工具。

表3 采用索引加速多只查询的方案对比
5. 大数据分析的挑战
在描述了大数据分析流程中的多个阶段之后,我们现在转向一些共同的挑战,这些挑战存在于以上阶段中的许多阶段(有时是全部阶段)。
5.1 异构性与不完整性
当人类消费信息时,大量的异构性是可以容忍的。事实上,自然语言的细微和丰富可以提供有价值的深度。然而,机器分析算法期望同构数据,并且不能理解细微差别。 因此,数据分析时必须在数据分析之前(或在分析的第一步)仔细地将数据结构化。即使在数据清理和纠错之后,数据中的一些不完整性和一些错误也可能保留下来。数据分析期间必须管理这些不完整性和这些错误,这对我们而言是一项挑战。
5.2 规模
在过去几十年里,管理巨大和迅速增长的数据量一直是一个具有挑战性的问题。 过去,这一挑战已经通过更快的处理器、遵循摩尔定律得到缓解。但现在正在发生一个根本的转变:数据量增长得比计算资源更快,而CPU速度是没有变化。
5.3 时效性
数据量大的另一面是速度慢。要处理的数据集越大,分析所需的时间就越长。 有效处理大数据量的系统也更可能能够更快地处理给定大小的数据集。然而,当大数据所说的速度(Velocity)不仅仅是这个速度。 相反,我们还有获得速度的挑战和时效性挑战。
有很多情况下需要立即得到分析结果。当数据量迅速增长,并且查询响应时间有限时,设计这样的结构变得尤其具有挑战性。
5.4 隐私
数据的隐私是另一个巨大的问题。 公众对个人资料的不当使用,尤其是连接多个来源的资料,恐怕是非常恐惧的。管理隐私既是一个技术问题,也是一个社会问题,必须从两个方面共同解决,才能实现大数据的承诺。
5.5 人的合作
理想情况下,大数据分析不全部是计算,而是将人的角色放在循环当中。在当今这个复杂的世界里,常常需要来自不同领域的多位专家真正理解正在发生的事情。大数据分析系统必须支持来自多个人类专家的输入,并共享对结果的探索。这些专家可能在空间和时间上是分散,因为将整个团队集中在一个房间内太昂贵了,一种流行的新解决方法是通过众包。
5.6 能耗问题
服务器电量的开销是巨大的,而其中只有6%~12%是用于相应用户查询的,绝大多部分的电量用于确保服务器处于闲置状态。可以通过采用新型低功耗硬件和引入可再生能源来应对能耗问题。
5.7 与硬件的协同
硬件的异构性会不可避免给集群整体性能带来“木桶效应”,解决方案是将不同计算强度的任务智能地分配给计算能力不同的服务器。另外,新硬件的给大数据带来了变革。可以通过构建HDD和SSD的混合存储系统来解决大数据处理问题。然而内存的发展一直没有出现革命性的变化,随着PCM为代表的SCM的出现,未来的内存很可能会兼具内存和硬盘的双重功能,给大数据处理带来根本性的变革。
5.8 大数据管理易用性问题
解决这个问题,需要从以下3个方面下手:可视化原则、匹配原则和反馈原则。
5.9 性能的测试基准
构建大数据测试基准面临的主要挑战有:系统复杂性高、用户案例的多样性和数据规模庞大、系统的快速演变、重新构建还是复用现有的测试基准。
6. 系统架构
如今的公司已经在使用商业智能,并重视商业智能的价值。业务数据分析的目的有很多:公司可以执行系统日志分析和社交媒体分析,以进行风险评估,客户保留,品牌管理等等。通常情况下,即使每个系统都包含信息提取,数据清理,关系型处理(联合,分组,聚合),统计和预测建模以及适当的探索和可视化工具。
7. 总结
我们已经进入了一个大数据时代。通过更好地分析大量可用的数据可以提高了企业的盈利能力和成功率。本文详细分析了大数据管理的关键技术,然而,在充分实现数据价值之前,必须解决本文中描述的许多技术挑战。在从数据采集到结果解释的各个阶段中,挑战不仅包括显而易见的规模问题,而且还包括异构性,缺乏结构,错误处理,隐私,时效性,来源、与硬件的协同、能耗问题、管理易用性等等。这些挑战将需要变革性的解决方案。
参考文献:
[1]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(01):146-169.
[2] 大数据白皮书
[3] What is Big Data Analytics? What is Big Data Analytics? https://www.ibm.com/analytics/hadoop/big-data-analytics