Siamese Network简介
Siamese Network 是一种神经网络的框架,而不是具体的某种网络,就像seq2seq一样,具体实现上可以使用RNN也可以使用CNN。
简单的说,Siamese Network用于评估两个输入样本的相似度。网络的框架如下图所示
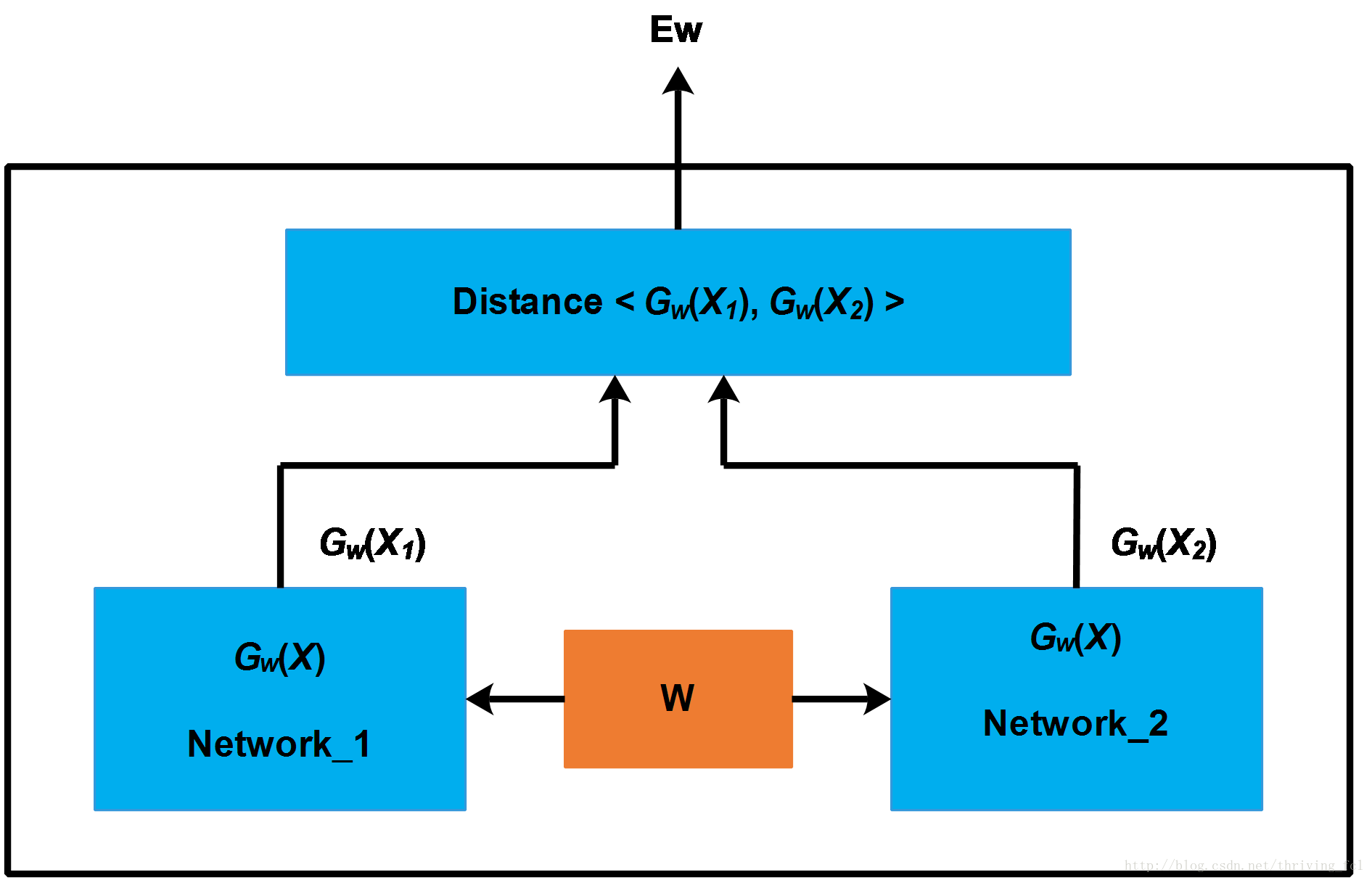
Siamese Network有两个结构相同,且共享权值的子网络。分别接收两个输入X1X1与X2X2,将其转换为向量Gw(X1)Gw(X1)与Gw(X2)Gw(X2),再通过某种距离度量的方式计算两个输出向量的距离EwEw。
训练Siamese Network采用的训练样本是一个tuple (X1,X2,y)(X1,X2,y),标签y=0y=0表示X1X1与X2X2属于不同类型(不相似、不重复、根据应用场景而定)。y=1y=1则表示X2X2与X2X2属于相同类型(相似)。
LOSS函数的设计应该是
1. 当两个输入样本不相似(y=0y=0)时,距离EwEw越大,损失越小,即关于EwEw的单调递减函数。
2. 当两个输入样本相似(y=1y=1)时,距离EwEw越大,损失越大,即关于EwEw的单调递增函数。
用L+(X1,X2)L+(X1,X2)表示y=1y=1时的LOSS, L−(X1,X2)L−(X1,X2)表示y=0y=0时的LOSS,则LOSS函数可以写成如下形式
Siamese Network的基本架构、输入、输出以及LOSS函数的设计原则如上文所述,接下来就说一下在NLP的场景,具体的Siamese Network应该如何设计。
LSTM Siamese Network
在文本方面,需要计算两个文本之间的相似度,或者仅仅判断是否相似,是否重复的场景也很多。简单直接的方法可以直接从字面上判断,使用BOW模型,使用SimHash算法都行。但是有些场景,字面上看可能不相似,但是从语义上看是相似的,这就需要更复杂的模型来捕捉它的语义信息了。
比如Quora就有这方面的需求,问答类型的网站希望同样的问题只有一个就好,但表述问题的方式可以多种多样,因此需要能够捕捉到更多语义上的信息。
将Siamese Network架构中的用于表征X1X1与X2X2的Network更换为LSTM网络,就可以用于判断两个输入文本是否语义上相似。
Learning Text Similarity with Siamese Recurrent Networks这篇文章介绍了这种网络的结构,也给出了具体的参数。网络的结构如下图所示
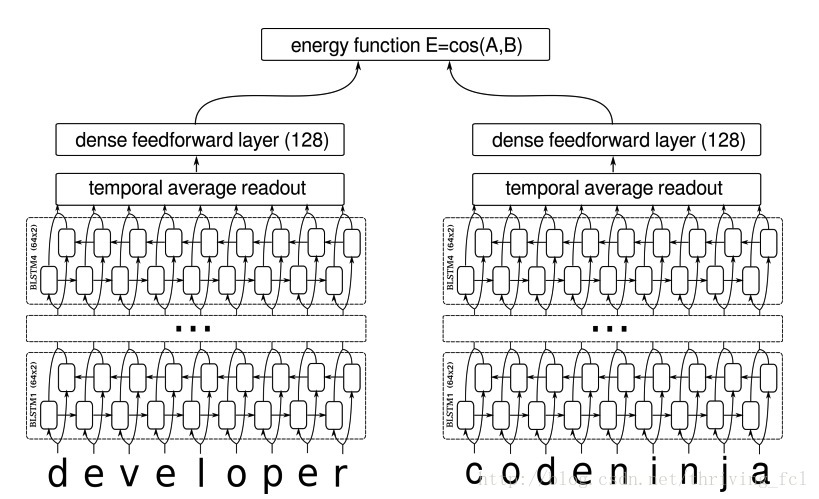
这是论文中的截图,在文本输入与BILSTM之间还有一个embedding层。
论文中的LSTM Siamese Network用了4层hidden unit size为64的BILSTM,再将每一时刻的输出取平均作为输入XX的表征向量,后面再接dim=128的全连接层,得到的两个向量f(X1)f(X1)与f(X2)f(X2)对应的就是第一部分介绍Siamese Network基本框架中的Gw(X1)Gw(X1)与Gw(X2)Gw(X2)。
这里的相似度EE使用的是余弦相似度,即
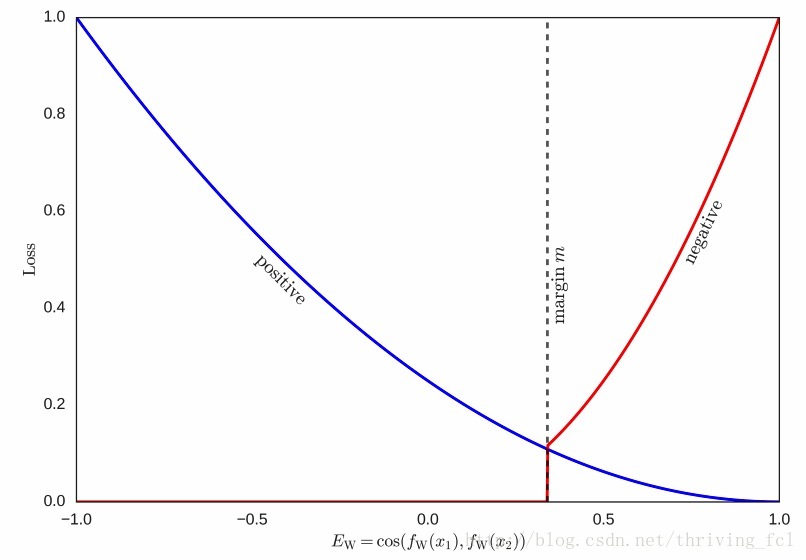
所以−1≤E(X1,X2)≤1−1≤E(X1,X2)≤1,与欧氏距离不一样的是,EcosEcos的值越大,代表距离越近,值越小距离越远,所以LOSS函数的设计也要与上文所说的相反。即
y=0y=0时,LOSS函数随着EE单调递增
y=1y=1时,LOSS函数随着EE单调递减
具体的有
总的LOSS函数不变 。mm是设定的阈值,可视化LOSS函数如下
LSTM Siamese Network总结起来就是
1. 将Siamese Network中的Encoder换成BILSTM
2. 将距离的计算改成余弦距离
3. 修改相应的LOSS函数
这个设计上还是有一些可以改进的,比如在BILSTM输出后,加一个attention,而不是直接average每个时刻的输出,这样可以更好的表征输入的文本。
代码实现
目前github上有一个开源实现,deep-siamese-text-similarity,但是代码稍微有点乱,并且有些地方实现的不对。
比如BILSTM模型的定义中
outputs, _, _ = tf.nn.bidirectional_rnn(lstm_fw_cell_m, lstm_bw_cell_m, x, dtype=tf.float32)
return outputs[-1]- 1
- 2
- 3
将最后一个时刻的输出作为表征向量,这样就忽略了其它时刻的输出。
还有定义两个孪生网络的时候,使用了不同的权值,根据Siamese Network的设计,在这里应该是要reuse_variable来共享权值的。
自己实现了一个,也放到github上:https://github.com/THTBSE/siamese-lstm-network。