#__author : 'liuyang' #date : 2019/3/7 0007 a = ['a' , 'b' , 'c'] b = [] print(a is b ) # 空元组 可以 空列表 不可以 print(tuple(a))
题目:
l1 = [11, 22, 33, 44, 55] #将此列表索引为奇数的对应元素全部删除 # 错误示例 for l in range(len(l1)): print(l) if l % 2==1: #l1.pop(l) # 等同余下 一个是括号 一个是中括号 del l1[l] print(l1) # l1 = [11, 22, 33, 44, 55] # del l1[1::2] # print(l1) dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3', 'name': 'alex'} lis = [] # 循环一个字典时,不能改变 字典的大小,否则会报错
for key in dic.keys():
# if 'k' in key:
# del dic[key]
print(key)
if 'k' in key:
# dic.pop(key)
lis.append(key)
# for li in lis:
# del dic[li]
# 在后面 删除
for li in lis:
del dic[li]
print(dic)
同一类型
小数据池: 理解
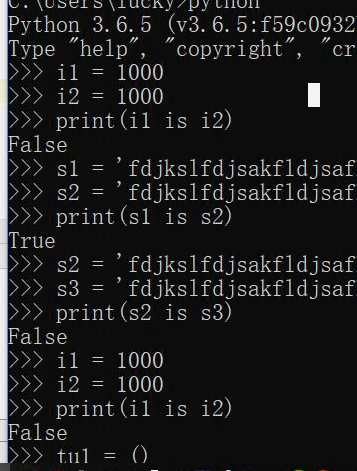
id == is 两者之间的id是否相同 (is 判断内存地址是否一样)(==判断值是否一样)
同一内存地址
获取该对象的内存地址
代码块:
一个文件;
交互式命令:一行代码
同一个代码块下:字符串的缓存机制,驻留机制:
背景:同一代码块下,遇到初始化对象命令,会实现检查字典是否有此对应关系.......
针对的数据类型:int(float) , 大量的str , bool ,(), None
None--------空列表空元组 空字符 统一指向这个内存地址
优点:
节省内存
提高执行性能
小数据池:
不同代码块
在内存中,开辟两个空间.
一个空间:-5~256
一个空间:一定规则的字符串
<20 个位 >-1
针对的数据类型:int str , bool ,(), None
优点:
节省内存
提高执行性能
# 超出范围了
数据类型的补充:
int str bool lis tuple dict set
(1)-------->int (1,)------------->tuple
int str bool 包起来
other ------------> bool
0 '' () [] {} ------> False
list <----> tuple 包起来
list、tuple ------> str sploit
str ---------------> list、tuple ' ',join(str)
用三种方式创建一个字典:
dic ={'name' : 'liuer'}

(2)-----> {1:2, 'name':alex}
(3)-----> {1:alex , 2:alex , 3:alex}
数据类型的补充
(1,)
fromkeys([1,2,3] , [])
循环一个列表 循环一个字典时 ,不能改变他们的大小,否则会报错
明天 : 编码进阶 文件操作 深浅copy
str(dict) --------> {}
inpre () '{}' #程序员用
print() # 美化了
回顾:字典特点:
1.key是唯一的.
2.key必须是可以哈希的(不可变数据类型:字符串,元组,数值)
3.key是无序的.
3.6中dict的元素有序是解释器的特点,不是python源码的特点.
xxx.py
Cpython -> 有序
Jpython -> 无序
集合:set
实际上就是一种特殊的字典.
所有value都是None的字典,就是集合.
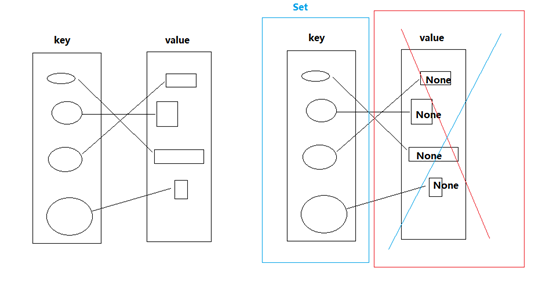
对比字典和集合的特点:
|
字典 |
集合 |
|
Key唯一 |
元素唯一 |
|
Key可以哈希 |
元素可以哈希 |
|
Key无序 |
元素无序 |
如何获取集合?
1.手动创建集合.
1.创建空集合
d = {}
创建空集合,只有一种方式:调用set函数.
S = set()
2.创建带元素集合
S = {1,2,3}
从可迭代对象中(字符串,列表,元组,字典)创建集合.
s = set(‘abc’)
S = set([1,2,3])
S = set((1,2,3))
S = set({‘name’:’Andy’,’age’:10})
2.通过方法调用
-> str
-> list
-> set
集合的操作:
查看集合可用的方法:
[x for x in dir(set) if not x.startswith(‘_’)]
['add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update',
'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
增:
add:如果元素存在,没有做任何动作.
删:
Pop() :依次从集合中弹出一个元素,如果集合为空,报错
Discard(ele) :从集合中删除指定的元素,如果不存在,什么都不执行
Remove(ele) :从集合中删除指定的元素,如果不存在,报错
Clear() :清空
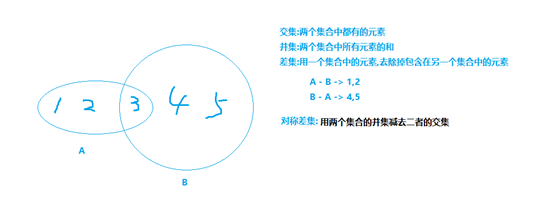
集合的四大常用操作:
并集:union
交集:intersection
差集:difference
对称差:symmetric_difference
改(更新):
Update :用二者的并集更新当前集合
difference_update:用二者的差集更新当前集合
intersection_update:用二者的交集更新当前集合
symmetric_difference_update:用二者的对称差集更新当前集合
判断功能:
Isdisjoint:判断两个集合是否没有交集
Issubset:判断当前集合是否是后者的子集
Issuperset:判断后者是否是当前集合的子集
查
集合基本没有单独取其中元素的需求.
集合的使用场景:
1.判断一个元素是否在指定的范围之内.
2.方便数学上的集合操作.
并,交,差,对称差
有简化写法:
并:|
交:&
差:-
对称差:^
3.对序列数据类型中的重复元素进行去重
如果想遍历集合中的元素.
通常用for循环.
frozenset:冻结的集合
最大的特点:不可变.
['copy', 'difference', 'intersection', 'isdisjoint', 'issubset', 'issuperset', 'symmetric_difference', 'union']
少了添加,更新的方法.
s = frozenset()
s = frozenset('abcabc')
s = frozenset([1,2,3])
s = frozenset((1,2,3))
s = frozenset({'name':'Andy','age':10})
集合的四大方法:并,交,差,对称差.
set,frozenset是否可以混用?
可以!
总结:
如果两种数据类型混用,方法的主调者的类型决定了最终结果的类型.
frozenset应用场景:
凡是使用到不可改变的数据的场景,都是可以使用frozenset的.
set集合的元素:必须是可以哈希的,set本身不是可以哈希.
但是frozenset是不可变的数据.(可以哈希的),它是可以放到集合中.
set和frozenset可以互相转换.
浅 copy 只 copy 第一层元素 :
l1 = [1,2,3,[1,2]]
l2 = l1.copy()
改变列表里的列表(第二层)都变 改变列表里的数字 不变
深 copy
l1 = [1,2,3,[1,2]]
l2 = l1.deepcopy()
改变列表里的列表 不变
不可变得 变化 改值 开辟新的内存空间 ?