数理统计与参数估计
作者:樱花猪
摘要:
本文为七月算法(julyedu.com)12月机器学习第二次课在线笔记。数理统计与参数估计是机器学习中需要用到的一个非常重要的知识。在机器学习中,我们通常会拥有大量的学习样本,而机器学习则是根据这些样本的数据找到一个通用的模型。数理统计是机器学习的理论保障,而参数估计则是我们实际编程的依据。
引言:
数理统计这一部分在本科学习《概率论与数理统计》这门课的后半段。当时我把更多的经历都放在了概率论上了,因为概率论要想明白的事情太多,而数理统计似乎只用套套公式而已。记得当年研究生考试出题老师似乎在数理统计方面给了我们许多引导性的题目,但是当年的我只是把它当做一门需要考试的课程来学习,并没有在意其真真切切的应用背景。直到读到有关于机器学习相关文献后,才发现当年的学习是本末倒置了。
邹博在机器学习班中提供了许多实际的例子让我充分体会到了当年理论的价值。本文也将按照课程的顺序主要分为两个部分,第一部分介绍了统计量,包括期望、方差、偏度、峰度以及协方差和相关系数。有了这些统计量概念,我们再深入讨论一下独立和不相关的问题。第二部分我们着重讨论如何进行参数估计,包括我们熟知的据矩估计和极大似然估计并介绍相关的理论知识包括大数定律、切比雪夫不等式等等。本次课程没有太多思维上的难度,但是知识点比较多。
预备知识:
概率论,数理统计
概率论:
期望;方差;偏度;峰度协方差;相关系数;独立相关性;
数理统计:
大数定理;切比雪夫不等式;矩估计;极大似然估计
1、统计量概念
1.1 期望
从感情上来讲就是预期的值,数值意义上来讲可以认为是概率加权下的“均值”。
离散型:![]()
连续性:![]()
这两个定义非常的重要,其中E(X)中的X是一个向量。
无条件成立(线性操作):![]()
若X和Y独立:![]()
1.2方差
定义:![]()
无条件成立:
![]()
![]()
当X和Y独立:![]()
1.3协方差
定义:![]()
性质:
![]()
![]()
![]()
![]()
相关性:
![]() ,X,Y的变化趋势相同
,X,Y的变化趋势相同
![]() ,X,Y不相关
,X,Y不相关
协方差上界:
若![]() ,则
,则![]()
当且仅当X和Y之间线性相关时取等号。
1.4相关系数
![]()
1.5协方差矩阵

![]()
去均值后,协方差矩阵为:![]()
协方差矩阵是对称阵。
1.4独立和不相关
独立比不相关性质更强。独立一定不相关,不相关不一定是独立。
二、参数估计
2.1 矩
定义:
对于随机变量X,X的k阶原点矩为![]()
X的k阶中心矩为![]()
总结:
一阶原点矩:期望
二阶中心矩:方差
三阶矩:偏度
四阶距:峰度
2.2 偏度
定义:偏度衡量随机变量概率分布的不对称性,是相对于平均值不对称程度的度量。

公式:
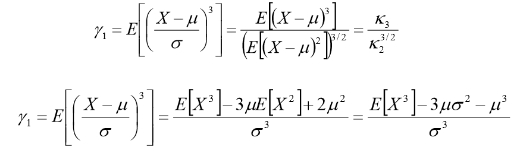
2.3峰度
定义:峰度是概率密度在均值处峰值高低的特征。
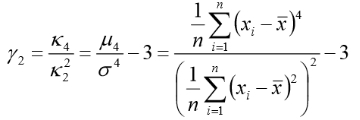
超值峰度(excess kurtosis):![]() ,
,
超值峰度为正,称为尖峰态(leptokurtic); 超值峰度为负,称为低峰态(platykurtic)
2.3切比雪夫不等式
设随机变量X的期望为μ,方差为![]() ,对于 任意正数ε,有,
,对于 任意正数ε,有,
![]() ;
;
表明:X方差越大,时间发生的概率约集中在期望附近。
2.4大数定理
设随机变量X1,X2…Xn…互相独立,并且具有相同的期望μ和方差![]() 。作前n个随机变量的平均 ,则对于任意正数ε,有
。作前n个随机变量的平均 ,则对于任意正数ε,有
![]()
意义:当n很大时,随机变量X1,X2…Xn的平均值Yn 在概率意义下无限接近期望μ。
重要推论(伯努利定理):一次试验中事件A发生的概率为p;重复n次 独立试验中,事件A发生了nA次,则:
![]()
2.5中心极限定理
设随机变量X1,X2…Xn…互相独立,服从同 一分布,并且具有相同的期望μ和方差![]() ,则随机变量:
,则随机变量: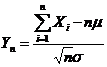 的分布收敛到标准正态分布。
的分布收敛到标准正态分布。
既:![]() 收敛到正态分布
收敛到正态分布![]()
实际问题中,很多随机现象可以看做许多因 素的独立影响的综合反应,往往近似服从正态分布。
2.6样本的统计量
样本均值:![]()
样本方差:![]()
2.7 样本的矩
k阶样本原点矩:![]()
k阶样本中心: (与样本方差对比)
(与样本方差对比)
2.8矩估计
利用样本的矩来估计样本的均值![]() 和方差
和方差![]()
原点表达式:

样本原点矩:

带入求值,得到矩估计结果:

2.9极大似然估计
让所有事件可能同时发生的概率最大。通过总体分布来求出参数![]() 。
。
设总体分布为![]() ,X1,X2…Xn…为该总体采样得 到的样本。因为X1,X2…Xn独立同分布,于是,它 们的联合密度函数为:
,X1,X2…Xn…为该总体采样得 到的样本。因为X1,X2…Xn独立同分布,于是,它 们的联合密度函数为:![]()
3、应用实例
3.1一定接受率下的采样
已知有个rand7()的函数,返回1到7随机自然数,让利用这个rand7()构造rand10()随机1~10。
解:因为rand7仅能返回1~7的数字,少于rand10的数目。因此,多调用一次,从而得到49种组合。超过10的整数倍部分,直接丢弃。
讨论:为什么用乘法组合而不用加法组合。我的理解是,这个题实际上可以认为是用7进制来表示10以内的数,随机出来的十位和个位数字是两个独立的事件,但是如果采用加法则两个rand就不是独立事件了。简单的说就是P(AB)=P(A)*P(B)而不是两个相加。
3.1 期望的应用
从1,2,3,......,98,99,2015这100个数中任意选择若干个数(可能为0个数)求异或,试求异或的期望值。
讨论:求异或可以联想到二进制编码,而取异或则只用看当前位置上的1的个数的奇偶性。分别对每个位置值求期望再求总期望。