利用Nutch和Tomcat构建搜索引擎
1. 安装环境及软件版本介绍
本教程是在Linux Ubuntu 12.04 desktop i386操作系统上搭建,结合使用了Nutch-1.2和Apache-Tomcat8.0.0构建搜索引擎(其他版本可能方法于此不同)。其中Apache-Tomcat8.0.0将本地机器配置成小型web服务器,Nutch1.2作为搜索引擎的核心,完成了网页爬取、索引构建和响应查询的的功能。
需要安装的组件:
Ø JDK1.7.0:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
Ø Apache-Tomcat8.0.0: http://tomcat.apache.org/download-80.cgi
Ø Nutch-1.2:http://archive.apache.org/dist/nutch/
2. 安装JDK1.7.0
(1)打开网址http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html,下载相应的JDK文件;

(2)解压文件;

(3)配置环境变量;




(4)检查是否安装正确

3. nutch安装的配置
(1)打开网址http://archive.apache.org/dist/nutch/ 下载nutch-1.2;

(2)解压文件;

(3)修改工作目录和权限;


(4)填写配置文件;



4. Tomcat安装和配置
(1)打开网址http://tomcat.apache.org/download-80.cgi, 下载Tomcat8.0.0;
(2)解压文件;

(3)修改工作目录和权限;

5. 抓取网页内容
(1)修改配置文件crawl-urlfilter.txt,把要爬取的网页url的正则表达式填写到适当的位置;


(2)在nutch根目录下建立种子文件,填写起始的url地址;


(3)输入命令,开始爬取,等待爬取完成;

参数说明:
Crawl 运行爬虫功能
Seed.txt 爬虫种子url保存的文件
-dir 爬虫抓取结果保存的路径
-depth 10 爬取的深度是10
-topN 20 每个网页取前20个url
-threads 5 启用5线程
6. 构建搜索引擎
(1)把nutch根目录下的nutch-1.2.war文件拷贝到tomcat根目录下webapps文件夹内;

(2)运行tomcat服务器;

(3)等待tomcat自动生成文件,然后修改生成的nutch-size.xml文件,把6节中抓取的网页内容的文件夹填写到配置文件中;

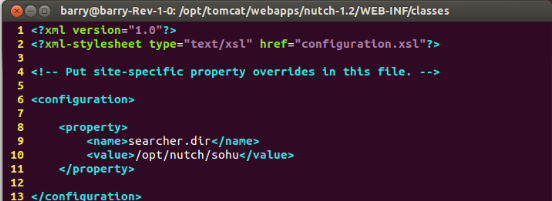
(4)重启tomcat,启用上一步配置;


7. 查看结果
(1)打开任意的浏览器,这里以chrome浏览器为例,在地址栏输入http://localhost:8080/nutch-1.2

(2)在编辑框内填写要搜索的内容,以搜狐为例;
