OPEN INFOREB SEARCH QUERY LOGSMATION EXTRACTION FROM WEB SEARCH QUERY LOGS
第一章 介绍
搜索引擎日益比传统的关键字输入、文档输出的先进,通过关注面向用户的任务提高用户体验,面向用户的任务包括查询建议、搜索个性化、推荐链接。这些以用户为中心的任务被从search query logs挖掘数据支撑。事实上,查询日志抓住用户对世界的认知,是这项应用的关键。
从查询日志中抽取的语言知识,如实体和关系,对上面的应用来说有很大的价值。然而目前还没有对从查询日志抽取知识付出很多研究。本论文,我们首次调查开放的信息抽取基于查询日志。我们的目标是从查询日志中抽取面向用户的知识,来帮助推理。
传统的信息抽取关注抽取结构化的信息,如实体、关系、事实,从非结构化的文本中,使用两个主要的假设:(1)文本资源是句法和语义良构的文本片段,例如新闻语料、网页文档;(2)抽取处理是从一些先验的知识中自举产生的。
开放的信息抽取(open information extraction, OIE)是刚兴起的信息抽取范式,放宽了假设(2),通过关注领域独立且可扩展的从网页量级的语料中抽取实体和关系,不需要人工输入。
在本文中,我们更进一步,通过避免假设(1),探索search query log对于OIE的实用性。我们阐述放宽假设(1)和(2)允许我们适当得实现我们的目标,抽取面向用户的知识。特别的,我们假设网页文本和查询日志建模两个不同的空间:网页文本建模web space,search query log 建模 user space。
为了使我们对基于search query log的OIE假设建模可计算,一些挑战需要解决。首先,我们需要避免假设(2)从查询日志中挖掘自然发生的信息,我们需要建立完全独立于任何先验知识的抽取方法。第二,查询日志不具有句法结构,我们需要建立鲁棒的抽取方法,不需要关联任何传统的自然语言处理工具,例如POS Tagger。第三,查询日志是简洁的,我们需要设计有效的抽取的实体表示,这个表示能恰当的抓住查询日志的特性。最后,尽管查询日志没有网页语料那么大,但是仍然是大的数据集,因此我们的方法必须可以高效处理大数据集。
我们介绍基于search query log的OIE的两个阶段的方法。第一个阶段(实体抽取),使用无监督的方法从查询日志中抽取实体,应用基于模式的启发式和统计方法。第二阶段(实体聚类),通过使用聚类方法,利用查询日志的多种信息,在这些实体上建立类别。总结起来,我们的主要贡献是:
- 我们为基于search query log的OIE,提出和实现了一个新颖的模型;
- 我们介绍一个非监督的技术,用领域独立方式从非典型的语料中的抽取实体;
- 我们介绍如何特征化每个抽取出的实体,并且从这些实体中建立类别。
- 我们介绍一个基于现实数据集的广阔的评估,显现出查询日志是领域独立的面向用户抽取任务的宝贵资源。我们也显示了我们方法的实用性,通过把它引入到两个实际的应用中:为新闻推荐相关的实体,付费搜索提供建议关键字。
第二章 查询日志实体抽取
实体抽取是在NLP和基于网页应用中具有重要作用的任务。在历史上,实体抽取被定义为抽取预先定义类别的实例。我们介绍一个无监督的方法,从大规模开放领域的查询日志中抽取实体。依照我们的知识,我们是第一个试图提出一个算法,明确为了同时实现以下两个目标:(1)从查询日志中抽取实体,(2)从开放领域型中抽取实体,没有预先定义的类别。
从原始的用户search query logs开始,我们的方法首先标识候选实体,然后,可靠的实体从候选实体中选出来,通过使用两个基于文本证据的信任得分,通过计算包容过滤。
2.1 生成候选实体
开放领域的从查询日志中的实体抽取有一些挑战:首先,现有的基于类别决定的方法被证明是领域限定的。第二,我们从查询日志中抽取实体,查询日志是非典型的语料,查询是短的,并且缺乏句法结构,因此消弱了对传统的基于上下文证据和句法特征的方法的使用。
我们的生成候选实体的方法是基于简单的观察,用户经常通过拷贝网页存在的短语建立他们的查询。由于这个现象,用户的查询通常包含表层级别的属性,例如大写属性和分词属性。我们的方法意识到这个观察,通过从用户查询中标识连续的字母大写词。特别的,给定一个查询Q=q1q2…qn,我们定义一个候选实体E=e1e2…em,E是Q中最大长度的序列,满足在E中的每个词ei首字母大写。
给定自由的查询,我们采取的表层级别的技术距离完美很远。例如,很小部分用户只驶入大写字符。我们需要标识并且抛弃假的实体。方法在下面介绍。
2.2 得到信任得分
给定一个通过刚才步骤生成的候选字符串E=e1e2…em,我们给他分配2个信息得分:一个基于网页的表达得分,一个基于查询日志的独立得分。Representation score抓住这个直觉,在E中大小写敏感的Q,在网页数据中也应该有相同的形式。更形式化的,基于网页的表达得分rw(E)通过下面公式计算:
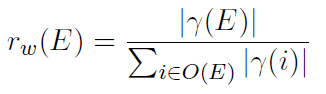
其中,|x|是字符串x在网页语料中出现的次数,r(i)是i的大小写敏感表示,O(E)是字符串E的所有发生集(不是很明白是不是所有大小写情况呢?)。
Standalone score基于观察,一个候选实体E应经常在查询日志中独立出现。事实上,在查询日志中,我们必须找到Q==E的查询,抓住用户想要知道关于中国实体更多信息的事实。更形式化的,我们计算基于查询日志的standalone score sq(E) 通过下面的公式:
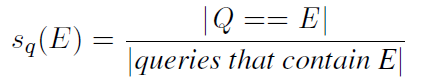
上面得到了得分rw(E)和sq(E),我们保留实体满足rw(E)≥τr并且sq(E) ≥τs。在实验中,我们通过发展集估计了大量的τr和τs,并把τr设置为0.1,τs设置为0.2。
2.3 应用包容过滤器
作为最后的步骤,我们考虑边界检测的问题。通常,我们可能有大量的重叠的候选,他们只是表示概念,不是实体。这些串可能没有被过滤掉。我们采用这样的方法过滤:一个字符串完全包含另一个实体将被遗弃。
第三章 实体聚类
我们介绍在一写领域开放的实体中使用的聚类方法。在这里的目标是把在用户空间具有相似性的实体聚合到一起。为了完成这个目标,我们首先需要把每个实体表示成在这个空间的一个特征集合,然后我们需要使用聚类算法聚合具有相似特征的实体。
3.1 用户空间
上下文特征空间。上下文特征空间的基本假设是,一个实体可以被有效的表示成它在查询日志中所在的上下文特征集。这可以抓住用户对这个实体的观点。
我们的基于查询日志特征可能显著的不同于传统的基于网页语料的特征,因为相同的实体可能在两种语料中表现出不同的表达和观念(也就是说在网页中的用法和在查询中的用法可能不同)。
为了得到我们的上下文表示,我们使用如下的处理。对每个实体e,我们首先找出所有包含实体e的查询日志。然后,我们找到这个实体出现的查询的前缀和后缀(也就是前面的字符串和后面的字符串)。
当所有实体的所有上下文被统计好时,我们忽略出现次数少于τ的上下文,这样可以避免数据稀疏造成的统计偏差(在实验中吧τ设置为200)。我们然后计算校正的点式互信息(corrected pointwise mutual information,cpmi):(具体可以在论文《discovering word senses from text》中找到)
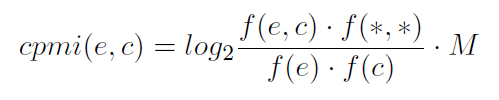
其中,f(e,c)表示e和c在同一个查询中共同出现的次数,f(e)和f(c)是实体e和上下文c在查询中出现的次数,f(*,*)表示所有词和所有上下文出现的次数(就是用到的查询的数量,具有e或者具有c)。M是校正因子,作用是减少低频实体和低频上下文造成的统计误差。这样每个实体都能表示成一个pmi值的向量。注意:我们的方法不用任何的NLP parsing,因为查询几乎没有句法结构。这样可以保证算法计算复杂度不高,并且可以容易适应其他语言。
点击特征空间。在一个搜索对话期间,用户发起一个搜索,搜索引擎返回一个url列表。搜索的结果是,用户选择那些可以表达他们意图的url。这种交互行为可以被点击捕捉到,这些点击行为会被多数搜索引擎写入日志,作为click-trough data。
我们基于用户点击行为聚集实体的主要动机是,不同的查询点击相同的url捕获用户相似的意图。因此,聚合用户点击的相同的url的实体可能是相似的。我们观察发现,网址趋向于为每个实体贡献一个url。因此通过点击url聚合实体,可能找出同义词(相同实体的不同表示)和变形体(拼写错误)。为了得到更多的相关聚类,我们使用base url代替click url。
由于百科类网站(如维基百科)的存在,取base url可能导致不相似的实体放入相同的类别。为了解决这个问题,在我们的实验中,使用一个stop-list,通过排除前5个基于逆文档频率的url,其中entity被看做是“document”。
实际上,每个被抽取的实体e被表示为一个大小等同于所有用户点击的base url数量的向量。向量的每一维表示一个url。实体e向量的关于url j的那一维通过如下方法计算:

其中μ是当实体e被作为查询发起,得到的base url集合,w(e,j)是当实体e作为查询发起时,点击url j的次数。
混合特征空间。我们也实验了混合特征空间,使用的是上下文特征空间和点击特征空间的规范化并集。
3.2 聚类算法
聚类阶段使用上面介绍的任意特征空间,通过实体的向量的相似度聚合实体。这个任务的聚类算法需要具备这样的特点:(1)算法必须是高度可扩展的、高效的、可以计算高维度,因为查询的数量和特征向量的维数是很大的;(2)我们事先不知道类别的数目。
任何满足上面两个要求的聚类算法都可以被采用。在现在的实验中,我们采用CBC,最先进的聚类算法,已经被显示在很多语言任务中优于K-means算法。我们使用一个高度可扩展的Map Reduce CBC,可以保证鲁棒的高效的内存使用。CBC介绍略。
第四章 实验评估
先简单介绍一个使用的数据
查询日志:随机选择的100百万,在2009年前3个月,被搜索引擎收集的匿名的查询,和查询的频数。我们使用月来拆分数据集JN,FB,MR。这些数据用来抽取实体、生成上下文和点击特征空间。
网站文档:搜索引擎爬取的500百万网页。这些数据用来实现基于网页的特征。
4.1 实体抽取
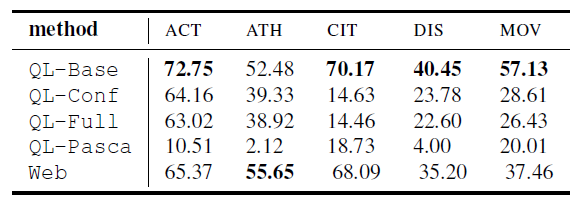
评价方法:我们实现两组实验,一个来评估准确性、一个来评估覆盖性。
对于准确性实验,我们为买个方法随机均匀选择400个实体,把它们分给两个专家级的标主工作者,它们必须裁定一个实体是否正确。
对于覆盖性实验,我们关注在查询日志中频繁出现的5个类别的实体:演员、运动员、城市、疾病和电影。对于每个类别,我们基于维基百科生成一个代表gold set。
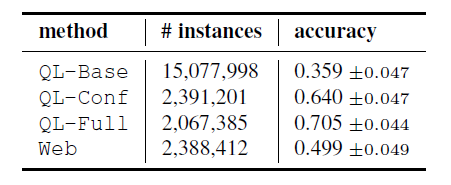
比较方法:我们使用MR数据集来比较下面的实体抽取系统:
-
- QL-Base: 一个base line。只使用候选实体生成。
- QL-Conf: 使用信任得分过滤。
- QL-Full: 使用信任得分过滤和包容过滤。
- QL-Pasca: 其他的系统Pasca.
- Web:一个基于网页的开放领域的实体抽取方法,首先用post-tagger,基于规则的chunker,然后名词chunk选择作为候选实例,最后超过50次的大写字母开始和结束的候选作为最终结果。
4.2 实体聚类
这个实验的目标是双重的:(1)估计聚类算法的内在质量;(2)证实我们开始做的假设是否正确。
评价方法:许多已有的评价标准都需要gold standard data set。因为在我们的情况中,这样的数据集不可用而且难以构造。我们使用一个认证处理。我们首先从QL-FULL中选择一个随机n个实体组成的集合,随机通过它们在日志中的频数产生。对每个在样本集中的实体e,我们推出一个随机的由k个和e属于同一个类别的实体组成的列表。在我们的实验中,n=10,k=20。然后,我们把这些交给雇佣的编辑者,e和与e同类的k和实体。编辑者需要判断每对同类实体是正确的还是错误的。如果实体ei和实体e在用户的视觉上是相似或者相关的。这些编辑者的一致性超过一个阈值0.64。附加的,我们询问编辑者实体e和ei之间的关系。
比较方法:使用下面的方法
- CL-CTX:CBC,基于查询日志上下文特征空间。
- CL-CLK:CBC,基于点击特征空间。
- CL-HYB:CBC,基于混合特征,结合CTX和CLK。
- CL-WEB:先进的开放领域的基于网页文本数据特征。
实验结果
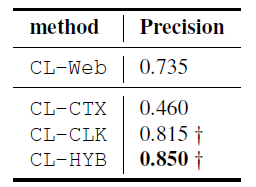
可以看出使用点击特征空间是很有效的。上下文特征空间不如点击空间和网页空间。
第五章 应用
在本章中,我们探索我们提出模型的两个实际的应用。为新闻推荐相关实体和付费搜索提供关键字生成。
5.1 新闻的相关实体
与新闻相关的网站通常通过可能感兴趣的新闻列表帮助用户探索新闻,为了基于当前文章用户的兴趣的深入阅读。特别的,潜在的问题是标识新闻中的主要概念,基于这个概念提供这篇文章中没有提及的相关概念。一些方法被提出来为了(a)有效的在文章中标识主要概念(b)推荐相关概念。我们的目标在这里是检验我们的实体聚类是否能成功解决(a)和(b),并且使用户满足。
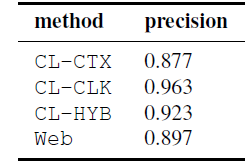
数据集创造:我们从2009年的新闻中随机选取3百万篇文章。对于每种方法,我们生产一个50个新闻文章样本,并保证他们至少含有2个在一个类别中的实体。对每篇文章,我们提出和这两个实体属于同一类别的前10的实体。
评价和测量:我们估计方法是生成相关的实体使用准确率:给定一篇文章和相关的一对实体,我们让两个标注人标记相关的实体。如果一个用户对这篇文章中的实体感兴趣,那么他可能会对推荐的实体感兴趣。标注人的一致性在50个推荐中的kappa值为1.78。准确率是通过相关的推荐除以总的推荐数得到的。
对比:使用CL-CTX, CL-CLK,CL-HYB和Web方法对比。
结论:如图。
5.2 付费搜索的关键字生成
付费搜索占很多搜索公司年收入的大部分。在付费搜索中,在线广告商对明确的关键字(叫做 bidterms)投标,通过一个搜索公司的专用平台的拍卖会。投标的获胜者将被允许把他们的广告链接到搜索公司的搜索结果页面,当bidterms被查询。
类似google和yahoo的公司投入努力和金钱,来提升他们的投标平台,为了吸引更多的广告商来竞拍。Bidterm建议是这些努力的相关例子。在bidterms建议中,广告商键入一个种子关键字,表达他的广告的意图,然后这个工具提供一个建议的关键字列表,列表中的关键字可以竞拍。
对一个种子生成竞拍建议是自动的,并且在搜索公司已经被得到了关注。所有的关键字建议技术可以被分为3个类别:近邻搜索(Proximity search)方法用种子查询一个搜索引擎,并且在结果页面中抽出n-grams在种子的近邻中。查询日志(Query-log)方法,典型的观察过去频繁的包含种子的查询,并且把他们作为建议,此种方法是最常使用的The Google Adwords Tool和Yahoo Search Marketing Tool。Meta-tag spidering(媒体标记爬取)方法使用种子查询一个搜索引擎,并且在最优排名的页面中抽取媒体标签作为建议。
现存的对于关键字生成的工具都是高准确率的。但是都是只探索包含种子的建议,它们趋向于忽略其他的不明显的建议。这些不明显的建议有可能是给广告商不贵的但是仍然是高度相关的建议。
5.2.1 实验设置
这个实验的目标是估计不同方法的建议的质量,对一些大众化的seed bidterm。
数据集构造:为了构建种子集合,我们使用Google skTool database。这个工具提供一个大众的bidterm的列表。我们选择3个话题的列表:旅游业,交通业和电子客户。对每个话题,我们随机选择5个种子,这些种子也在QL-FULL中。
评价和测量:我们使用准确率和不明显度。准确率是通过询问两个有经验的人是否相关,如果一个广告商愿意选择建议竞拍。不明显度简单的计数有多少个建议不包含种子本身,通过简单的字符串匹配和简单的词干来计算。
比较:CL-CTX, CL-CLK, CL-HYB和Web。还有最先进的两个系统Google AdWords (GOO) and Yahoo Search Marketing Tool (YAH)。
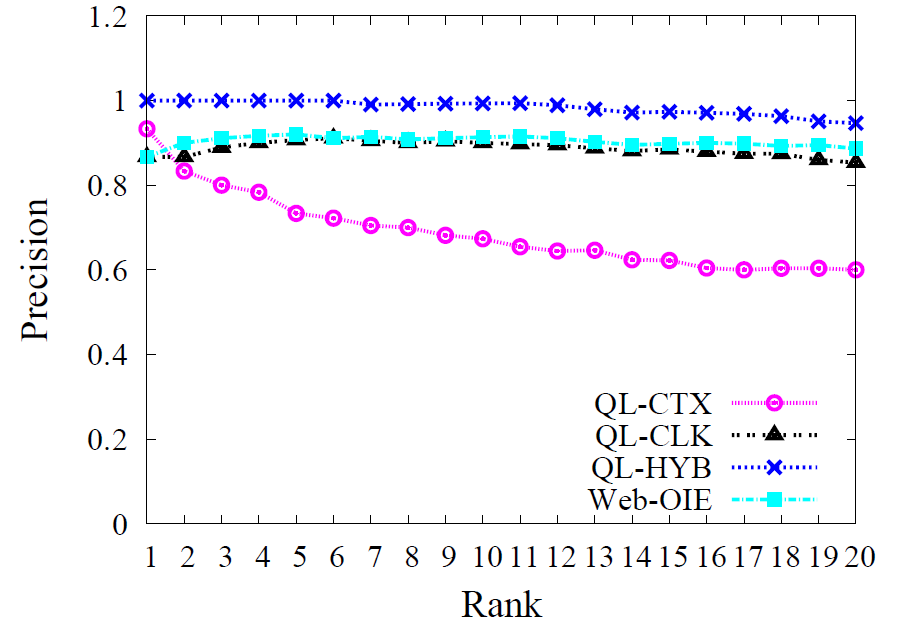
5.2.2 实验结论
略。