进程与线程的并发
在讲并发之前,我们需要了解几个概念:什么是串行、并发、并行?
- 串行:完整执行完一个程序再执行下一个
- 并发:程序之间看起来是同时运行的
- 并行:真正做到了同时运行
除此之外,多道技术里有两点需要我们关注一下(括号内的为扩展内容):
- 空间复用:多进程共用内存条(分块->分页->分段+分页),但是都有自己独立的内存空间(基址寄存器、地址的动态重定位),互不干扰,物理隔离。
- 时间复用:共用一个CPU(分时系统)
备用知识:
进程以及线程有五种状态:新建 (New)、就绪(Ready)、运行(Running)、阻塞(Blocked)
和死亡(Dead)
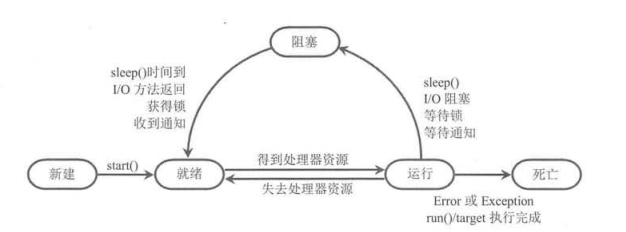
进程
我们把一个正在运行的程序叫做进程,那么我们就正式用代码来学习进程的并发吧!
开启子进程的两种方式:
-
通过指定函数作为target,创建Process对象来生成新进程
from multiprocessing import Process import time def task(): print('进程 start') time.sleep(2) print('进程 end') if __name__ == '__main__': p = Process(target=task) p.start() # 向操作系统发送开子进程请求,具体什么时候开,开多长时间只和操作系统有关。 time.sleep(5) print('主进程/父进程') -
继承Process类,并重写run()方法来创建进程类
from multiprocessing import Process import time class Test(Process): def __init__(self,sex): super().__init__() self.sex = sex def run(self): '''run()方法为进程的执行体,执行start()后就会自动执行,不要直接调用!!!''' print(f'子进程的性别是{self.sex} start') time.sleep(2) print('子进程 end') if __name__ == '__main__': p = Test('女') p.start() # 向操作系统 发送开启子进程的请求 print('主进程')
Process类的方法(概要)
- run():重写该方法可以实现进程的执行体
- start():用于启动进程
- join([timeout]):当前进程必须等待被join的进程执行完成才能向下执行
- name:该属性用于设置或访问进程的名字
- is_alive():判断进程是否还活着
- daemon:该属性用于判断或设置是否为守护进程(后台状态)
- pid:返回进程的ID
- authkey:返回进程的授权key
- terminate():中断该进程(请求),具体什么时候中断由操作系统分配
Process类的方法(详细)
-
join([timeout]):当前进程必须等待被join的进程执行完成才能向下执行
如果不指定timeout,那么后一个进程就会无限地等待join的进程结束,如果给timeout赋值了,那么就会最多等待多少秒,如果join的进程还没结束,则不再等待。
from multiprocessing import Process import time def foo(x): print('进程 start ') time.sleep(x) print('进程 end ') if __name__ == '__main__': p1 = Process(target=foo,args=(1,)) p2 = Process(target=foo,args=(2,)) p3 = Process(target=foo,args=(3,)) start = time.time() p1.start() # p2.start() # p3.start() # # 核心需求就是 p3.join() #1s p1.join() #1s p2.join() #1s # 总时长:按照最长的时间计算多一点。 end = time.time() print(end-start) #3s多 or 6s多 ? 正解:3s多 print('主') -
daemon:该属性用于判断或设置是否为守护进程(后台状态)
守护进程的特征就是:如果前台的进程都死了,那么后台的线程会自动死亡
from multiprocessing import Process import time def foo(): print('守护进程 start') time.sleep(3) print('守护进程 end') def task(): print('子进程 start') time.sleep(5) print('子进程 end') if __name__ == '__main__': p = Process(target=foo) p2 = Process(target=task) p.daemon = True # 把这个子进程定义为了守护进程 p.start() p2.start() time.sleep(1) print('主') -
pid:返回进程的ID
-
每个进程都会有属于它的ID,一般情况下只有等所有的子进程都执行完,父进程会统一回收(wait())所有子进程的pid,此时已经死了的子进程被称为僵尸进程(Zombie)。大量的僵尸进程会占用系统资源,造成浪费,最简单的方法就是把生产僵尸进程的元凶kill了,那么所有的僵尸进程就变成了孤儿进程,由init进程接管,init会wait()这些孤儿进程,释放它们占用的系统进程表中的资源,这样,已经僵死的孤儿进程 就能瞑目而去了。
-
查看pid的几种方式:
from multiprocessing import Process,current_process import time,os def task(): print('子进程 start') print('在子进程中查看自己的pid',current_process().pid) # 在子进程中查看自己的pid print('在子进程中查看父进程的pid',os.getppid()) # time.sleep(2) print('子进程 end') if __name__ == '__main__': p = Process(target=task) p.start() print('在主进程查看子进程的pid',p.pid) # 一定要写在 start()之后 print('主进程的pid',os.getpid()) print('主进程的父进程pid',os.getppid()) print('主') ''' # 记住这些就ok了 这个是要掌握的 # 角度 站在当前进程的角度 os.getpid()#获取当前进程的pid os.getppid() #获取当前进程的父进程的pid 子进程对象.pid #获取当前进程的子进程pid '''
-
进程安全及同步锁(Lock)
多进程同时运行的时候,很容易会出现错误的情况,比如抢票,很有可能多人搜索到并抢到了同一张票,我们是不希望发生这样的事的,那么我们就需要加锁,multiprocessing模块提供了Lock和RLock两个类,它们都提供了如下两个方法来加锁和释放锁:
-
acquire(blocking = Ture, timeout = -1):请求对Lock或RLock加锁,其中
timeout参数指定加锁多少秒(可解决死锁问题)。 -
release():释放锁
那么Lock和RLock的区别如下:
-
Lock:互斥锁(或称互斥量Mutex),它是一个基本的锁对象,每次只能锁定一次,其余的锁请求,需要等待锁释放后才能获取。
-
RLock:可重入锁(Reentrant Lock) 也叫递归锁(Recursive mutex)。对于可重入锁,在同一进程中可以对它进行多次锁定,也可以多次释放。但是acquire()和release()方法必须成对出现,即调用了n次acquire()加锁,就必须调用n次release()才能释放锁。RLock对象会维持一个计数器来追踪。
那我们试着写一下抢票代码:
from multiprocessing import Process,Lock
import json,time,os
def search():
time.sleep(1) # 模拟网络io
with open('db.txt',mode='rt',encoding='utf-8') as f:
res = json.load(f)
print(f'还剩{res["count"]}')
def get():
with open('db.txt',mode='rt',encoding='utf-8') as f:
res = json.load(f)
# print(f'还剩{res["count"]}')
time.sleep(1) # 模拟网络io
if res['count'] > 0:
res['count'] -= 1
with open('db.txt',mode='wt',encoding='utf-8') as f:
json.dump(res,f)
print(f'进程{os.getpid()} 抢票成功')
time.sleep(1.5) # 模拟网络io
else:
print('票已经售空啦!!!!!!!!!!!')
def task(lock):
search()
lock.acquire() # 锁住
get()
lock.release() # 释放锁头
if __name__ == '__main__':
lock = Lock() # 写在主进程是为了让子进程拿到同一把锁.
for i in range(15):
p = Process(target=task,args=(lock,))
p.start()
# 进程锁 是把锁住的代码变成了串行
补充(了解) 信号量(Semaphore):
from multiprocessing import Process, current_process, Semaphore
import time
def task(sm):
sm.acquire()
print(f'{current_process().name} 在执行')
time.sleep(3)
sm.release()
if __name__ == '__main__':
sm = Semaphore(5) # 指定同时最多有多少个进程在执行
for i in range(15):
t = Process(target=task,args=(sm,))
t.start()
补充(了解) GIL锁:
在Cpython解释器中有一把GIL锁(全局解释器锁),GIl锁本质是一把互斥锁。
导致了同一个进程下,同一时间只能运行一个线程,无法利用多核优势。
同一个进程下多个线程只能实现并发不能实现并行。
原因:因为cpython自带的垃圾回收机制不是线程安全的,所以要有GIL锁。
死锁
讲到锁我们就不得不提一个经典的死锁问题,简单理解就是两个锁同时锁住了对方,都在等对方先释放。
这里分享一个小故事:
面试官:你给我简单明了的说下死锁问题,我就把offer发给你。
应聘者:你把offer给我我就给你讲死锁问题
死锁是不应该在程序中出现的,在编写程序时应该尽量避免出现死锁 。下面有几种常见的方式
用来解决死锁问题:
- 使用可重入锁:使用RLock
- 避免多次锁定:尽量避免同一个进程对多个Lock进行锁定。
- 相同的加锁顺序:让进程之间按照相同的顺序加锁。
- 使用定时锁:在调用acquire()方法时指定timeout参数
使用队列(Queue)控制进程通信
在queue模块下提供了几个阻塞队列,主要有三个队列的类,他们的主要区别就在于进队列、出队列的不同。简单介绍如下:
- queue.Queue(maxsize = 0) :代表FIFO(先进先出)的常规队列,maxsize可以限制队列的大小,如果队列的大小达到队列的上限,就会加锁,再次进入的元素就会被阻塞,直到队列中的元素被消费。如果将maxsize设置为0或负数,该队列的大小就是无限的。
- queue.LifoQueue(maxsize = 0):代表LIFO(先进后出)的队列
- queue.PriorityQueue(maxsize = 0):代表优先级队列,优先级最小的元素先出队列,通常用数字,数字小的先出。
这三个队列的属性和方法基本相同,他们都提供了如下的属性和方法:
- put(item,block = True, timeout = None):向队列中放入元素,如果队列已满,且block参数为True(阻塞),当前进程被阻塞,timeout指定阻塞时间,如果将timeout设置为None,则代表一直阻塞,直到该队列的元素被消费;如果队列已满,且block参数为False(不阻塞),则直接引发异常。
- get(item,block = True, timeout = None):从队列中取出元素(消费元素)。参数与put类似。
- put_nowait(item):相当于把block设置为False。
- get_nowait(item):相当于把block设置为False。
- empty():判断队列是否为空。
- full():判断队列是否已满。
- qsize():返回队列的实际大小(包含几个元素)。
例子:
# 我们也可以导入multiprocessing的Queue
from multiprocessing import Queue
q = Queue(2)
q.put('1')
q.put('2')
# q.put('3', timeout=1) # 等1秒,还放不进去就报错
q.put('4', block=False) # 报错 queue.Full
进程池
进程池的基类是concurrent.futures模块里的Executor,Executor提供了两个子类,即ProcessPoolExecutor和ThreadPoolExecutor,其中ProcessPoolExecutor用于创建进程池,而ThreadPoolExecutor用于创建线程池。
使用进程池/线程池的目的:当并发的任务数量远远大于计算机所能承受的范围,即无法一次性开启过多的任务数量,我们就应该考虑去限制我进程数或线程数,从保证服务器不崩。
如果我们使用池来管理并发编程,那么只要将相应的task函数交给进程池/线程池,剩下的事就由池来解决。
Executor提供了以下常用方法:
-
submit(fn, *args, **kwargs): 将fn函数提交给进程池。后面的是fn的位置参数和关键字参数。
-
shutdown(wait = True):关闭进程池
-
map(func, *iterables, timeout = None, chunksize = 1):(了解)该函数类似于全局函数map(func, *iterables),只是该函数会启动多个进程,以异步的方式对iterables执行map处理。
程序将task函数提交(submit)给进程池后,submit方法会返回一个Future对象,Future类主要用于获取进程任务函数的返回值。进程任务异步执行。由于进程执行的函数相当于一个“将来完成“的任务,所以用Future来表示。
Future主要的方法:
-
result(timeout = None):获取该Future代表的进程任务最后返回的结果。如果。如果Future代表的进程任务还未完成,该方法会阻塞当前进程,其中timeout参数指定最多阻塞多少秒。
-
add_ done_ callback(fn):为 future 代表的线程任务注册 个“回调函数”,当该任务成功完成时,程序会自动触发该fn 函数。
在用完一个进程池后,应该调用该进程池的shutdown()方法,该方法将启动进程池的关闭序列。调用shutdown()方法后的进程池不再接收新任务,但会将以前所有的己提交任务执行完成。当进程池中的所有任务都执行成后,该进程池中的所有进程都会死亡。
示例:
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time
def task(i):
# print(f'{currentThread().name} 在执行任务 {i}')
print(f'进程 {current_process().name} 在执行任务 {i}')
time.sleep(1)
return i * 2
if __name__ == '__main__':
# pool = ThreadPoolExecutor(4) # 池子里只有4个线程
pool = ProcessPoolExecutor(4) # 池子里只有4个线程
fu_list = []
for i in range(20):
future = pool.submit(task, i) # task任务要做20次,4个进程负责做这个事
# print(future.result()) # 如果没有结果一直等待拿到结果,导致了所有的任务都在串行
fu_list.append(future)
pool.shutdown() # 关闭了池的入口,会等待所有的任务执行完,结束阻塞.
for fu in fu_list:
print(fu.result())
前面的程序调用了Future的result()方法来获取线程任务的返回值,但该方法会阻塞当前进程,只有等到进程任务完成后,result()方法的阻塞才会被解除。
如果我们不希望直接调用result()方法阻塞进程,则可以通过Future的add_ done_ callback()方法来添加回调函数,该回调函数形如fn(future)。当进程任务完成后,程序会自动触发该回调函数,并将对应的Future对象作为参数传给该回调函数。
接下来的程序使用add_ done_ callback()方法来获取线程任务的返回值。
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
from threading import currentThread
from multiprocessing import current_process
import time
def task(i):
# print(f'{currentThread().name} 在执行任务 {i}')
print(f'进程 {current_process().name} 在执行任务 {i}')
time.sleep(1)
return i ** 2
def parse(future):
# 处理拿到的结果
print(future.result())
if __name__ == '__main__':
# with ThreadPoolExecutor(4) as pool: # 池子里只有4个线程
with ProcessPoolExecutor(4) as pool: # 池子里只有4个线程
fu_list = []
for i in range(20):
future = pool.submit(task, i) # task任务要做20次,4个进程负责做这个事
future.add_done_callback(parse)
# 为当前任务绑定了一个函数,在当前任务执行结束的时候会触发这个函数,
# 会把future对象作为参数传给函数
# 这个称之为回调函数,处理完了回来就调用这个函数.
提示:进程池/线程池实现了上下文管理协议,因此,程序可以使用with语句来管理进程池,这样就可以避免手动关闭进程池。
补充:我们也可以通过from multiprocessing.pool import Pool来表示进程池。
线程
线程的方法基本上和进程类似,那么线程和进程的主要区别就是:
操作系统可以同时执行多个任务,每个任务就是一个进程;进程可以同时执行多个任务,每一个任务就是一个线程。
线程里我们还需要在了解两点:
- 定时器(Timer)
- 协程:单线程下实现并发,协程实际是程序员抽象出来的,操作系统根本不知道协程存在,也就说一个线程遇到io 线程内部直接切到别的任务上,操作系统跟本发现不了,实现了单线程下的最高效率。
- 优点:自己控制切换要比操作系统切换快的多。
- 缺点:自己要检测所有的io,但凡有一个阻塞整体都跟着阻塞;且无法运用多核优势。