写在前面的话
对于企业而言,在互联网这一块其实最重要的是数据。保证数据的安全性,稳定性是作为运维人的基本工作职责。于是为了数据安全性,引进了数据备份,bin log 等。但这并不意味着有这些就足够了。试想一下,假设我们的数据库服务器宕机了,原因可能是机器炸了,硬件故障,而数据量又特别大。如果新建数据库再恢复可能需要半天乃至于一天的时间。那么在这段时间,所有服务的都是无法使用的。这样一天下来,很难想象对于公司造成的损失到底有多大,特别是上市公司,股票可能暴跌。那么有没有一种方法,能够帮助我们在遇到这种事故的时候实现快速切换?保证服务不中断?有的。这节就主要来说说最简单最基础的方式,主从复制。
关于主从复制
对于主从复制,需要知道一些它的基本原理:
1. 主从复制的服务器包含两个角色:Master 和 Slave。
2. 主从复制是基于二进制日志(bin log)的,这意味主节点(Master)必须开启二进制日志。
3. 从库(Slave)通过特定的线程获取到主库(Master)的二进制日志,并在从库中执行,从而实现和主库数据保持一致。
由此可以得出,出从更多的解决是主库一键故障,系统故障,而不是例如删库这样的操作,因为删库操作会在从库也执行。
主从复制的前提:
1. 两台 MySQL,配置不同的 server_id。
2. 主库开启了 bin log。
3. 拥有用于主从复制的专有用户。
4. 从库数据是主库数据的某个时间点的。
搭建最基础的主从复制
1. 主库中开启 bin log,配置不同 server_id:
主库 /etc/my.cnf:
server_id=111 log_bin=/data/logs/mysql/binlog/mysql-bin binlog_format=row
从库 /etc/my.cnf:
server_id=112 log_bin=/data/logs/mysql/binlog/mysql-bin binlog_format=row
2. 主库新建同步用户,并备份主库:
创建同步授权用户:
grant replication slave on *.* to 'repl'@'192.168.100.112' identified by '123';
同步用户只需要授权:replication slave 权限即可
备份主库:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -E -R -A --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF >/tmp/data.sql
查看备份中的指针(Position),并记录:
head -30 /tmp/data.sql
结果:

关键:MASTER_LOG_FILE='mysql-bin.000002',MASTER_LOG_POS=971592
3. 从库中导入备份:
source /tmp/data.sql
4. 从库中配置主库连接信息:
help change master to;
查看用法:

根据这个帮助文档中示例就行修改,然后执行:
CHANGE MASTER TO MASTER_HOST='192.168.100.111', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=971592;
5. 从库中启动 slave:
start slave;
show slave statusG
查看结果:
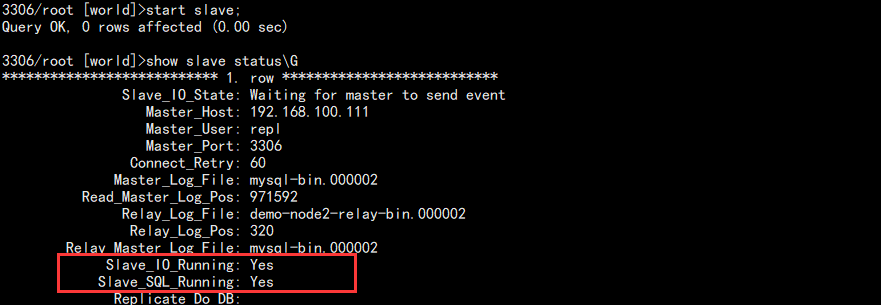
主要看这两个 Yes,表示开启主从复制成功。
6. 主库测试:在主库新家数据库在从库查看结果:
create database testdb3;
从库查看:

至此,最基本的主从复制完成!
主从复制分析
在主从复制搭建完成后,可以对其进行分析:
线程方面:
主库:dump 线程
从库:IO 线程,SQL 线程
文件方面:
主库:mysql-bin.00000x(二进制日志文件)
从库:
demo-node2-relay-bin.000001(中继日志)
master.info(主库信息)
relay-log.info(中继日志应用情况)
主从复制原理:

整个主从复制过程:
1. 从库执行 CHANGE MASTER TO 以后,关于主库的 IP,端口,同步账户等信息就被保存到了 master.info 文件中。
2. 从库执行 START SLAVE; 之后,从库开启两个线程:IO 和 SQL。
3. IO 线程读取 master.info 的信息连接主库,主库创建 DUMP 线程来响应从库。
4. IO 线程根据 master.info 中的指针(Position)和 bin log 文件向 DUMP 请求最新的日志。
5. DUMP 线程根据收到的 IO 线程的指针信息查看 bin log,如果有更新,则传递给从库 IO 线程。
6. IO 线程将收到的日志保存在 TCP/IP 缓存中,并向主库 DUMP 线程应答,至此主库的工作完成。
7. IO 线程将缓存中的数据存储到 relay-log 日志文件中,并更新 master.info 中的指针。至此,IO 线程工作完成。
8. SQL 线程读取 relay-log.info,获取到上次的起点,然后将日志中新增的在从库执行,完成后更新 relay-log.info。
至此,整个同步过程完成,需要知道的是,每次主库产生新数据都会发信号给 DUMP 线程,IO 线程再度发起请求。
查看主库:

查看从库:

Slave 状态说明:
show slave statusG
1. 主库相关的信息:
Master_Host: 192.168.100.111 Master_User: repl Master_Port: 3306 Master_Log_File: mysql-bin.000002 Read_Master_Log_Pos: 971760
2. 中继日志信息:
Relay_Log_File: demo-node2-relay-bin.000002
Relay_Log_Pos: 488
3. 从库线程:
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
4. 过滤复制相关:
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
5. 从库延时:(因系统原因导致)
Seconds_Behind_Master: 0
6. 人为设置的主从延时:
SQL_Delay: 0
SQL_Remaining_Delay: NULL
7. GTID 复制相关:
Retrieved_Gtid_Set: Executed_Gtid_Set: Auto_Position: 0
一般故障总结
在主从配置的时候,一般如果从库无法连接上主库的原因大致有以下几个:
1. 用户名,密码,端口,地址错误导致无法连接。
2. 主库达到连接数量上限,主库繁忙导致无法连接。
3. 防火墙,Selinux,网络问题导致无法连接。
这类问题有一个统一的排查方法,就是使用同步用户在从库上面直接远程测试连接主库看能否连接上。
主从同步失败故障原因:
1. 主库未开启二进制或者从库配置的二进制指针错误导致同步失败。
2. relay-log 缺失或者损坏,导致 SQL 线程无法执行。
3. 主从数据库版本差异,导致某些语法在另外一个库上面不同,从而无法执行。
4. 直接修改了从库,导致和主库已经不一致,再去同步操作某些可能不存在的数据出错。
这类问题的终极处理办法都是推荐重新创建主从环境,并确保两边的配置。
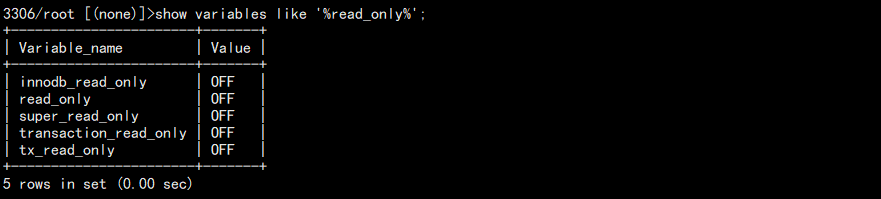
为了避免误操作从库导致主从同步失败,可以将从库配置为只读,当时是针对普通用户:
show variables like '%read_only%';
结果:
当然对于同步中出现同步某个同步失败的情况,可以跳过该事务:(生产环境坚决不允许,不然可能出现大坑)
方法1:
stop slave; -- 将同步指针向下移动一个,如果多次不同步,可以重复操作。 set global sql_slave_skip_counter = 1; start slave;
方法2:配置文件中添加(虽然可以解决,但是坚决不允许)
slave-skip-errors = 1032,1062,1007
错误代码说明:
1007:对象已存在
1032:无法执行DML
1062:主键冲突,或约束冲突
主从同步延时故障分析
在同步过程中,可能会出现主库执行的 SQL 在从库结果一段时间后才会执行的情况,针对于该类问题,可以将原因归咎于以下几个方面:
1. 外在因素:
外在因素有很多,可能是网络传输性能差,服务器性能差,参数版本问题等。
2. 主库因素:
二进制写入不及时,二进制日志写入策略为延时写入(sync_binlog),因为从库是根据二进制日志同步的。
在 5.6 之前版本,DUMP 线程是串行传输二进制日志。主库事务大,可以并行执行,但是从库只能串行(类似多线程和单线程)。
解决办法为开启 GTID 功能,实现 GC(group commit),并行传输日志给从库。对于大事务建议拆分成小事务。
3. 从库因素:
在传统的主从同步中,只有一个 SQL 线程,所以日志到从库还是串行执行,所以慢。
解决办法:5.6 版本开启 GTID 后,从库就能实现 SQL 线程的多线程执行,但只能针对不同库并发。
5.7 以后的版本开启 GTID 以后针对逻辑时钟实现 SQL 多线程,这才是正在多线程(MTS)。另外就是事务不应该太大。
总而言之,版本 5.7 以上,开启 GTID 能够解决很多问题。
人为实现主从延时
在某些特殊时候,并不一定需要主库执行之后从库立即执行。之前说过,主从能够解决因为系统或者硬件故障引起的主库挂掉的问题。但是无法解决类似 drop database 这类问题。因为从库也会跟着 drop,所以这个时候就有了主从延时发挥作用了。
假设这样一个场景,配置了主从延时 3 小时,如果主库执行了 drop database,那么在这 3 个小时内我们有 99% 的可能性发现问题。所以此时我们只需要去从库 stop slave,从库就不会执行 drop database 操作,而我们恢复的数据也就变成最近 3 个小时以内的即可。大大减少了我们恢复的时间。
具体配置方式:
从库执行:
stop slave; CHANGE MASTER TO MASTER_DELAY=300; start slave;
在主库上面删除测试库可以在从库查看:
show slave statusG
结果:

上面是配置的延时时间,下面是距离执行还需要的时间,我们配置的 300 秒。
延时从库故障恢复模拟
准备工作:
特别提示:生产环境出现问题,先备份,再操作。
一个主从环境,为了便于观察,配置主从延时为 3000 秒。
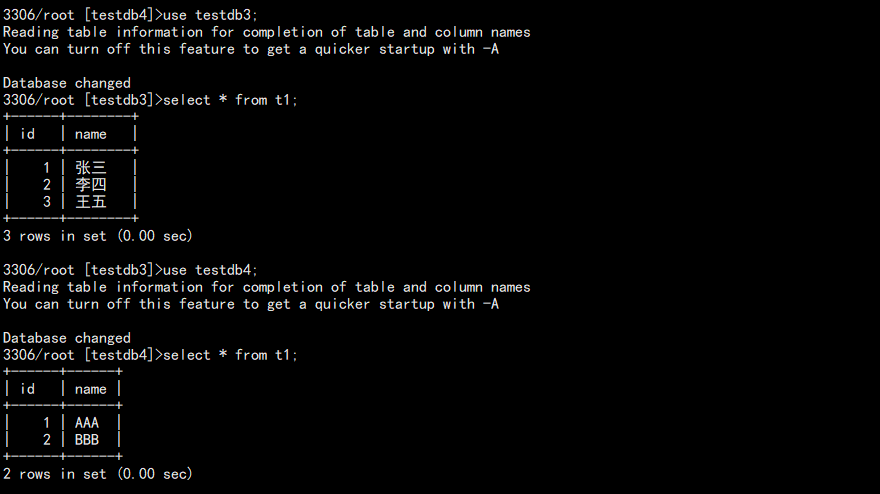
在主库上面执行一系列的操作,并删库,期间还有其它写入:
create database testdb3 charset utf8; use testdb3; create table t1(id int(4),name char(10)); insert into t1 values(1, "张三"); insert into t1 values(2, "李四"); commit; insert into t1 values(3, "王五"); commit; drop database testdb3; create database testdb4; use testdb4; create table t1(id int(4),name char(10)); insert into t1 values(1, "AAA"); insert into t1 values(2, "BBB"); commit;
从库查看:
show slave statusG
还没有执行:

此时我们主库已经删库了,并且 DUMP 线程已经将这些步骤都传输给了从库,从库只是等待时间执行而已。
同时我们需要记录当前的 relay-log 执行到的指针:

1. 关闭主库,避免再度有新数据写入,然后停止同步,这样从库的 SQL 线程就不会再去执行 relay-log:
stop slave;
2. 处理 relay-log:因为 relay-log 说到底还是 binlog 的一种,所以个之前的恢复方式一样:
mysqlbinlog --no-defaults --base64-output=decode-rows -vvv "demo-node2-relay-bin.000002" >/tmp/relay.sql
先将所有的 relay-log 导出为我们看的懂的 SQL 文件,这样便于我们寻找 drop 命令。
通过 vim 打开,可以找到对于的指针:

所以,本次截取的 relay-log 中的 SQL 我们期望的是 320 - 最后,但是要剔除 1558:
mysqlbinlog --no-defaults --start-position=320 "/data/data/mysql/demo-node2-relay-bin.000002" >/tmp/relay-1.sql
再次 vim 新的 SQL 文件,然后删除掉 drop 命令所在的 GTID 整个事务:

3. 在从库执行这个 SQL:
为了避免 GTID 问题,可以先执行重置,因为最终我们会将该库数据作为准确数据。
reset master;
然后导入 SQL:
source /tmp/relay-1.sql
完成后查看:
此时数据已经有了,并且还需要清理从库身份:
reset slave all;
现在去查看 relay-log 中的内容就已经没有了,被清除干净:
show relaylog events in 'demo-node2-relay-bin.000002';
结果:

这样最终实现了在从库恢复了所有数据,这个时候再把从库当作主库重新搭建主从也好,还是将数据导出再导入主库重新搭建主从也好。都不至于删库跑路了。
半同步复制(了解即可)
在之前介绍主从同步原理的时候,DUMP 线程将二进制日志发送给 IO 线程,IO 线程将日志存在缓存中然后恢复给主库一个 ACK 信号。那么主库的工作就完成了。
然而这个过程中有一个问题,就是主库其实是根本不知道从库有没有执行成功的。或许从库正准备执行,然后就宕机了呢?
于是,为了提高主从数据的一致性,便有了半同步复制。
工作原理:
1. 主库提交事务,发送信号给 DUMP 线程,DUMP 线程发信号给从库 IO 线程。
2. IO 线程向主库请求新的二进制日志。
3. DUMP 线程发送二进制日志给 IO 线程,IO 线程接受后,当日志被写到 relay-log 后,返回给主库 ACK_reciver 线程一个信号。
4. ACK_reciver 线程收到信号后告知主库同步成功。
5. 如果 ACK 线程超多预设的时间还没有收到信号,则切换回原始的异步复制。
这里配置就不再做阐述,该同步存在一定的问题,现在很少使用。
过滤复制
在某些特殊情况下,可能存在一些特殊的需求,比如只需要同步某一单独的库,而其它不需要同步,这时候便需要用到过滤。
看一个简单的示例架构,一个项目,有三个数据库,但是该项目主要还是查询居多,于是做了读写分类,从库读,主库写:
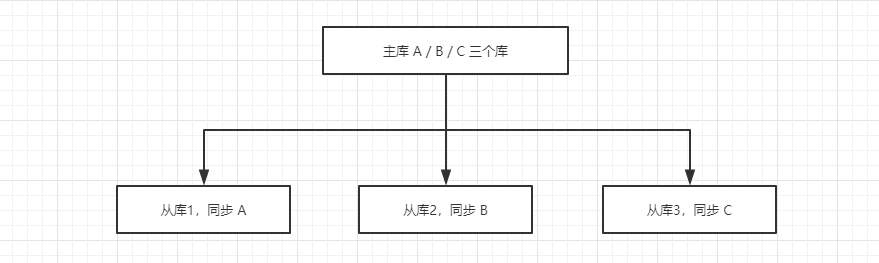
在查看从库状态的时候,有几个参数:
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
这就是同步过滤的关键,而在这 6 个参数中,用的最多的是:
Replicate_Do_DB:数据库过滤白名单
Replicate_Ignore_DB:数据库过滤黑名单
实现库的过滤方式有两种:
1. 主库配置:
Binlog_Do_DB:
Binlog_Ignore_DB:
也就是指定哪些库能够记录 binlog,因为同步就是基于 binlog 的。但是这种方法及其不推荐,这样数据丢了无法没有 binlog 的就无法恢复。
2. 从库配置:
Replicate_Do_DB:
Replicate_Ignore_DB:
配置需要同步的库,获取配置不同步的库。
过滤复制示例
准备工作:搭建完成的基本主从复制环境
1. 修改从库配置文件,添加需要同步的数据库:
replicate_do_db=testdb1 replicate_do_db=testdb2
有多少个就添加多少个,不能用逗号隔开。完成后重启数据库查看:
show slave statusG
结果:
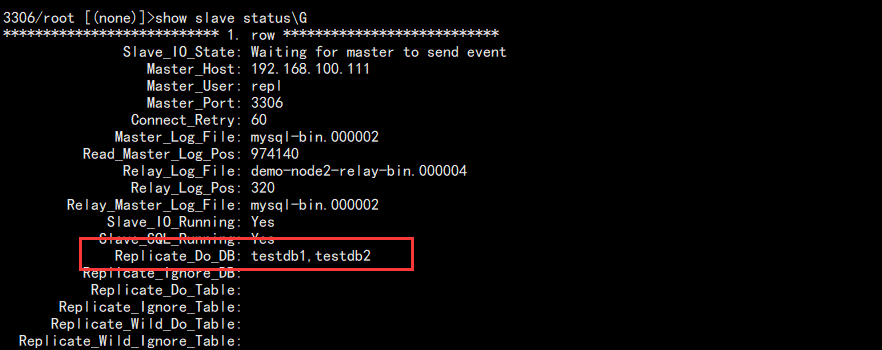
2. 修改主库测试同步效果:
use testdb1; drop table t3; use testdb2; drop table t1; use testdb4; drop table t1;
查看从库:
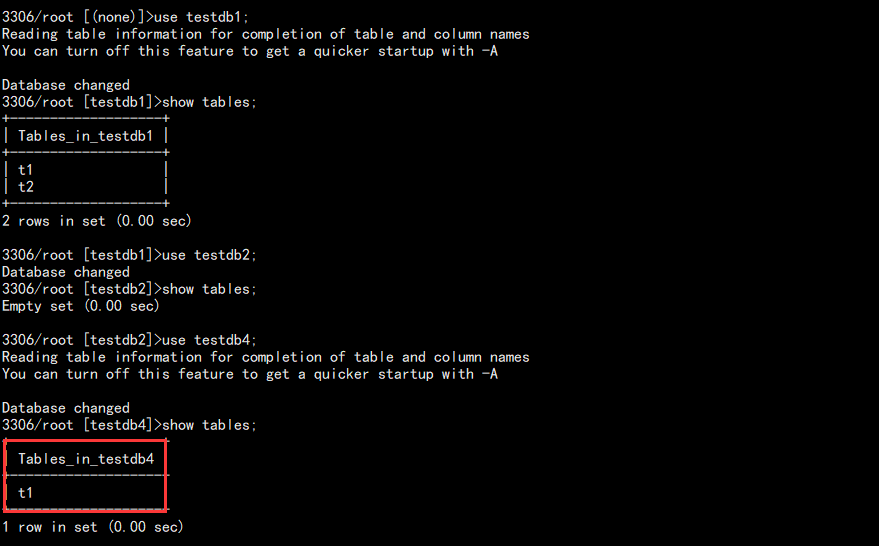
此时同步的库已经同步了,没同步的不变。
GTID 复制
准备工作:准备两台虚拟机,都安装了数据库。一台已经有数据,另外一台初始化完成的状态。
可以删掉其他库,然后执行:
stop slave; reset slave all; reset master;
1. 修改主库和从库的配置文件,增加 GTID 配置:
# 开启 GTID gtid-mode=on # 强制 GTID 一致性 enforce-gtid-consistency=true # Slave 更新写入日志 log-slave-updates=1
2. 备份主库导入从库:
mysqldump -uroot -p -S /data/logs/mysql/mysql.sock -E -R -A --triggers --master-data=2 --single-transaction >/tmp/data.sql
值得注意的是,千万不能有 --set-gtid-pureged=OFF 参数,因为我们需要 GTID。
从库导入:
source /tmp/data.sql
3. 由于同步用户已经存在,所以直接配置同步,启动同步:
CHANGE MASTER TO MASTER_HOST='192.168.100.111', MASTER_USER='repl', MASTER_PASSWORD='123', MASTER_PORT=3306, MASTER_AUTO_POSITION=1;
相比于传统的主从同步需要指定指针,GTID 由于在备份中已经存在,所以直接 AUTO。
start slave;
查看结果:
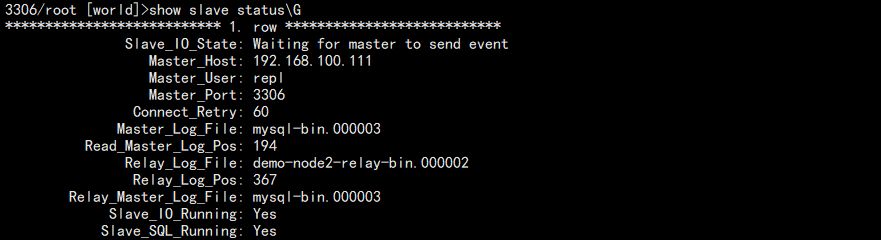
如果同步失败,会在下面配置的地方显示错误的 GTID 编号:

注意:解决主从同步失败最好的办法就是重新构建主从环境,而不是想办法绕开错误的点。
GTID 复制的优点:
1. 无论你多少从,它们的 GTID 都是一致的,这样有助于以后跨主机恢复。
2. 备份导入后不需要再度指定指针,直接 auto 即可。
3. 复制过程中,从库不在需要 master.info 文件,直接读取 relay-log 的 GTID。
4. 备份中会包含 GTID 的值,所以请求 binlog 就直接根据该值查询下一个事务,不会重复执行了。
小结
主从复制在实际生产中应用非常广,如果你的数据库连最简单的主从都没有,无异于在走钢丝。最终我们推荐主从的基础模式都想 GTID 复制靠拢,能够大大的提升性能。