Ensemble Learning的基本思想就是将多个基学习器组合在一起,产生泛化能力更强的模型。
组合策略有许多种,包括Voting、平均法和Stacking等,Stacking就是选择某种学习器作为组合基学习器的方式。
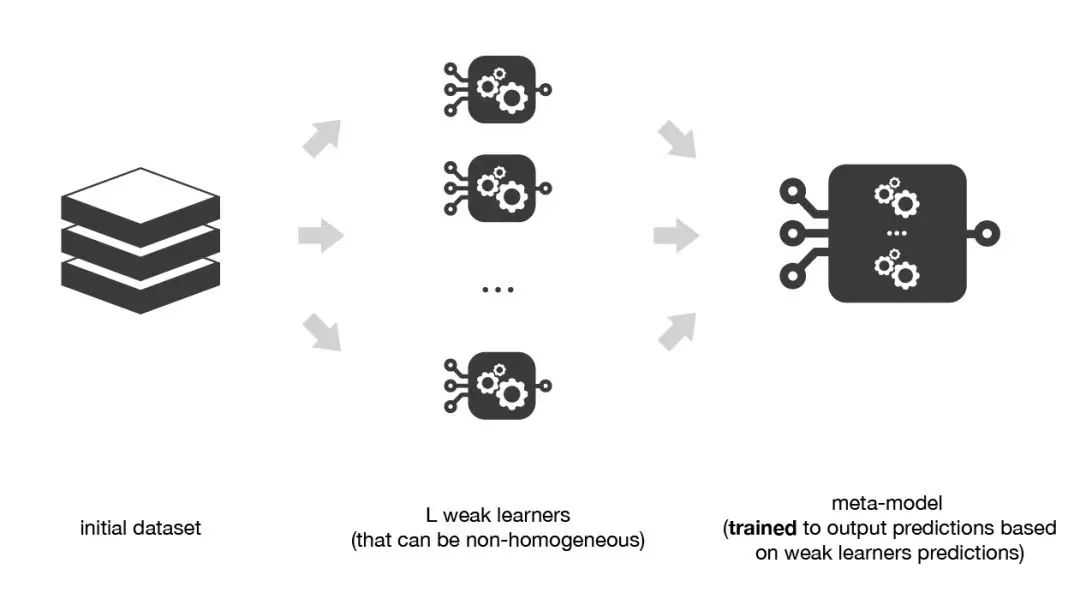
既然要结合多个基学习器的优点,那么基学习器的选择最好是“准而不同”,元学习器一般选择比较简单的模型(如逻辑回归),防止过拟合。
比较简单的想法就是将全部训练集用于训练基学习器,将基学习器的预测结果作为元学习器的训练集,从而得到整个模型。
这样做的问题在于:基学习器最终在训练集上的表现非常好,再用基学习器在该训练集上的预测结果作为次级训练集,同样元学习器在该训练集上表现也会非常好,但是模型的泛化能力不一定很好,有过拟合的风险。
因此,采用K折交叉验证的方式,用训练基学习器未使用的样本来产生次级训练集。
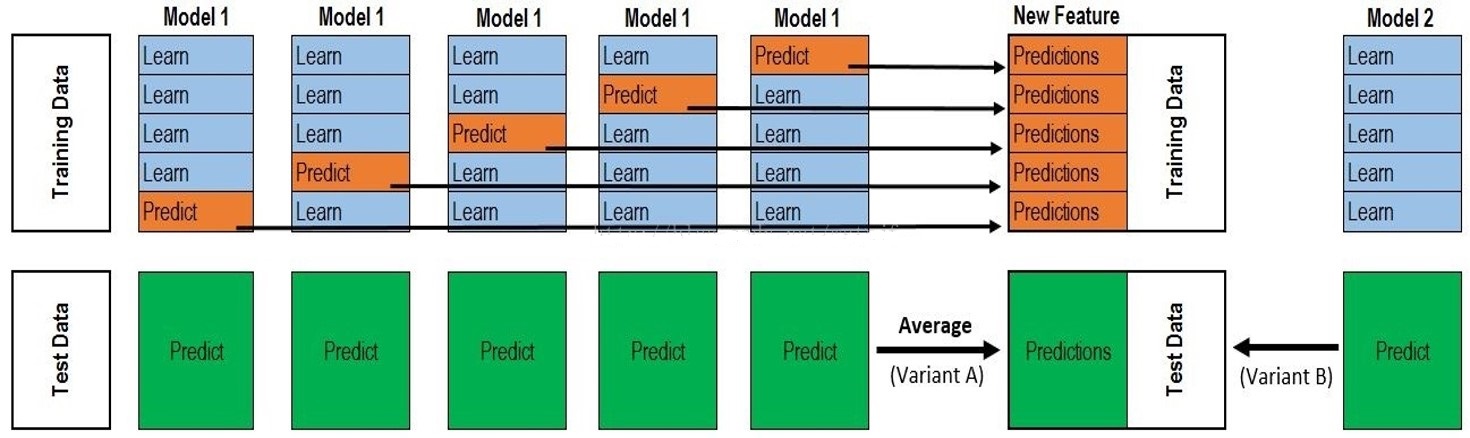
具体来讲:
在训练阶段(假设训练集(400*10)),对于每个基学习器(假设有3个基学习器),进行5次训练与验证,得到(400*1)的验证结果,那么最终次级训练集是(400*3)(类标签还是原始类标签),用这些数据训练次级学习器,完成后再用全部的训练集训练所有的基学习器(可选,提高基学习器性能);
在测试阶段,如果训练阶段选了最后一步,那么每个基学习器直接得到一个结果,就会得到3个测试结果,送入次级学习器,得到最终的预测结果;如果训练时没有选最后一步,那么每个基学习器都有5个小模型,将测试样本用5个小模型分别测试,将5个结果平均得到某个基学习器的预测结果,也会得到3个测试结果。
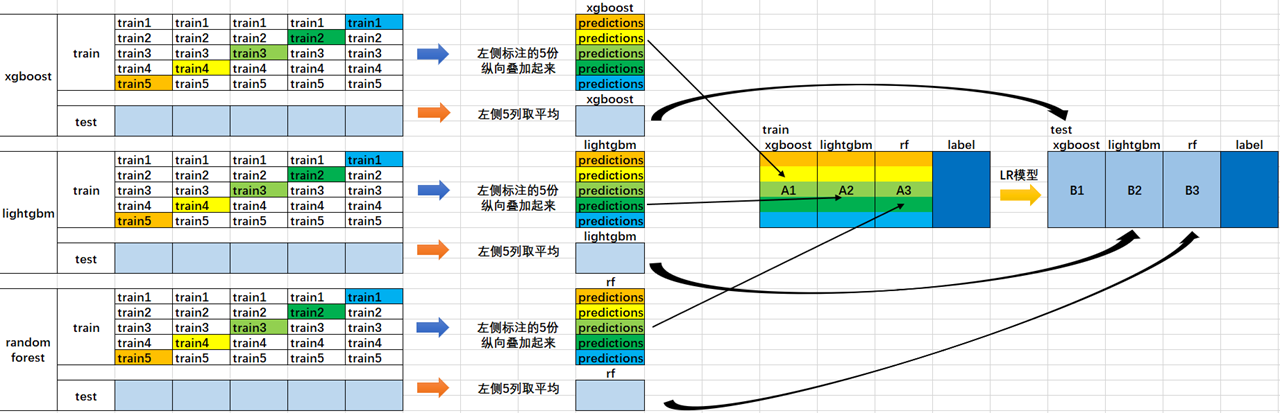
Weka里的实现:
/**
* Buildclassifier selects a classifier from the set of classifiers
* by minimising error on the training data.
*
* @param data the training data to be used for generating the
* boosted classifier.
* @throws Exception if the classifier could not be built successfully
*/
// 建立整个模型
public void buildClassifier(Instances data) throws Exception {
if (m_MetaClassifier == null) {
throw new IllegalArgumentException("No meta classifier has been set");
}
// 判断分类器是否有能力处理该数据集
getCapabilities().testWithFail(data);
// 删除类标签缺失数据
Instances newData = new Instances(data);
m_BaseFormat = new Instances(data, 0);
newData.deleteWithMissingClass();
Random random = new Random(m_Seed);
newData.randomize(random); // 打乱整个数据集
// 如果是分类问题,分层抽样
// 原始数据按照类标签集中在一起,按m_NumFolds为步长重新抽取数据,保持训练集/验证集数据分布一致性, 避免因数据划分引入额外的偏差
if (newData.classAttribute().isNominal()) {
newData.stratify(m_NumFolds);
}
// 处理原始数据得到新的数据,建立meta classifier
generateMetaLevel(newData, random);
// restart the executor pool because at the end of processing
// a set of classifiers it gets shutdown to prevent the program
// executing as a server
// 创建线程池,为下面的基学习器训练做准备
super.buildClassifier(newData);
// 提高基础模型的准确度,使其在测试数据表现更好,用所有的训练集进行基学习器的训练
// 这里为了节省时间,测试时,可以直接在多个基学习器预测后取平均
// Rebuild all the base classifiers on the full training data
buildClassifiers(newData);
}
/**
* Generates the meta data
*
* @param newData the data to work on
* @param random the random number generator to use for cross-validation
* @throws Exception if generation fails
*/
protected void generateMetaLevel(Instances newData, Random random)
throws Exception {
// 先用newData得到metaData的格式m_MetaFormat
// 确定元分类器需要的属性
Instances metaData = metaFormat(newData);
m_MetaFormat = new Instances(metaData, 0);
for (int j = 0; j < m_NumFolds; j++) {
// 得到训练集
Instances train = newData.trainCV(m_NumFolds, j, random);
// start the executor pool (if necessary)
// has to be done after each set of classifiers as the
// executor pool gets shut down in order to prevent the
// program executing as a server (and not returning to
// the command prompt when run from the command line
// 线程池,多线程并行构建基学习器
super.buildClassifier(train);
// 构建基学习器
buildClassifiers(train);
// Classify test instances and add to meta data
// 将未使用过的原始训练数据通过基学习器预测后加入metadata作为新的训练集
Instances test = newData.testCV(m_NumFolds, j);
for (int i = 0; i < test.numInstances(); i++) {
metaData.add(metaInstance(test.instance(i)));
}
}
// 利用元数据建立元分类器
m_MetaClassifier.buildClassifier(metaData);
}
因为基学习器之间的训练是独立的,所以每次交叉验证划分好数据后,都是利用线程池并行训练。
如果是在分层抽样的基础上划分训练集和验证集,trainCV()抽取数据后,需要将新的训练集Shuffle,保证独立同分布。
/**
* Makes the format for the level-1 data.
*
* @param instances the level-0 format
* @return the format for the meta data
* @throws Exception if the format generation fails
*/
// 生成元数据格式
protected Instances metaFormat(Instances instances) throws Exception {
// 如果m_BaseFormat属性连续,就加入m_Classifiers.length个属性
// 如果是离散的,每次要加入level 0类别属性取值个数个属性
ArrayList<Attribute> attributes = new ArrayList<Attribute>();
Instances metaFormat;
// 遍历基学习器
for (int k = 0; k < m_Classifiers.length; k++) {
Classifier classifier = (Classifier) getClassifier(k);
String name = classifier.getClass().getName() + "-" + (k+1);
if (m_BaseFormat.classAttribute().isNumeric()) {
attributes.add(new Attribute(name));
} else {
// 如果离散,后续会通过每个取值的概率来判断,比如杂色、圆花,这2种特性不能用一个属性表示,所以每个取值都要独立成单独的属性
// 来保存概率值
for (int j = 0; j < m_BaseFormat.classAttribute().numValues(); j++) {
attributes.add(
new Attribute(
name + ":" + m_BaseFormat.classAttribute().value(j)));
}
}
}
// 加上原始类标签
attributes.add((Attribute) m_BaseFormat.classAttribute().copy());
// 形成元数据格式
metaFormat = new Instances("Meta format", attributes, 0);
metaFormat.setClassIndex(metaFormat.numAttributes() - 1);
return metaFormat;
}
生成元数据格式时,如果是分类问题,类标签的每个属性都被作为一个新的属性:
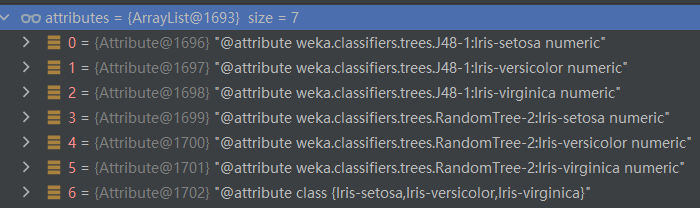
这里我个人这样理解:有的基分类器可以输出属于某个类的概率(如逻辑回归),将概率作为元属性而不是直接将基学习器的分类结果作为元属性,这样做能够减小基学习器的分类误差带给元学习器的影响,模型整体更加精确:

/**
* Makes a level-1 instance from the given instance.
*
* @param instance the instance to be transformed
* @return the level-1 instance
* @throws Exception if the instance generation fails
*/
// 产生元数据
protected Instance metaInstance(Instance instance) throws Exception {
// values保存分类结果,连续属性直接保存,离散属性则先求得分布,将每种取值的分布加入values,设置为m_MetaFormat格式返回
double[] values = new double[m_MetaFormat.numAttributes()];
Instance metaInstance;
int i = 0;
for (int k = 0; k < m_Classifiers.length; k++) {
Classifier classifier = getClassifier(k);
if (m_BaseFormat.classAttribute().isNumeric()) {
values[i++] = classifier.classifyInstance(instance);
} else {
// 基学习器对该实例的分类的概率分布, sum(dist)=1
double[] dist = classifier.distributionForInstance(instance);
// 将该基学习器对该实例的预测概率输出到对应的元属性
for (int j = 0; j < dist.length; j++) {
values[i++] = dist[j];
}
}
}
// 标签值对应最后一个元属性
values[i] = instance.classValue();
metaInstance = new DenseInstance(1, values);
metaInstance.setDataset(m_MetaFormat);
return metaInstance;
}
在实际数据集上的结果其实不一定比其他模型效果好,可能是我参数调的不好吧(雾)~