我们写好后端的代码,要把数据交给前端的展示的,这个数据以什么类型给前端呢?学到这里,我们已经知道这个数据最好是json字符串才行,因为网络间的传输,只认字符串或者二进制,字符串就是我们的数据,二进制就是流媒体,比如图片,视频,音频之类的
但是我们在后端经过逻辑处理得到的数据并不一定一开始就是个json字符串,所以就需要序列化下
补充:
序列化:将其他类型的数据转为字符串
反序列化:将字符串转回之前的数据类型(通常是字典类型)
在Python中,可用于序列化与反序列化的就是json和pickle模块,但是为了与restful规范相映,我们就用json模块(因为前后端分离后,不能保证以后会做成更多的样子,所以选用通用的json字符串)
创建一个django实例:
我使用的是django2版本
建数据库表:
from django.db import models
# 使用这个可以提前声明表名,在使用外键约束时可以不用考虑表前后顺序
__all__ = ['Book', 'Publisher', 'Author']
# Create your models here.
class Book(models.Model):
title = models.CharField(max_length=32, verbose_name='图书名称')
CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux'))
category = models.IntegerField(choices=CHOICES, verbose_name='图书类别')
pub_time = models.DateField(verbose_name='出版时间')
publisher = models.ForeignKey(to='Publisher', on_delete=None)
author = models.ManyToManyField(to='Author')
def __str__(self):
return self.title
class Meta:
# 自定义数据库表名
verbose_name_plural = 'book'
db_table = verbose_name_plural
class Publisher(models.Model):
title = models.CharField(max_length=32, verbose_name='出版社名称')
def __str__(self):
return self.title
class Meta:
verbose_name_plural = 'publish'
db_table = verbose_name_plural
class Author(models.Model):
name = models.CharField(max_length=32, verbose_name='作者名称')
def __str__(self):
return self.name
class Meta:
verbose_name_plural = 'author'
db_table = verbose_name_plural
迁移数据库后,添加数据:
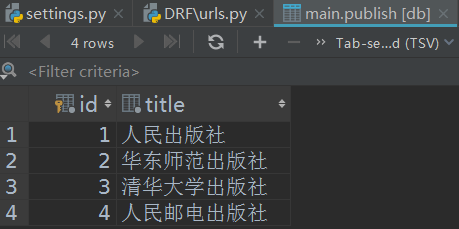
出版社:
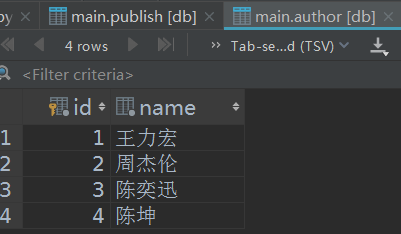
作者表:
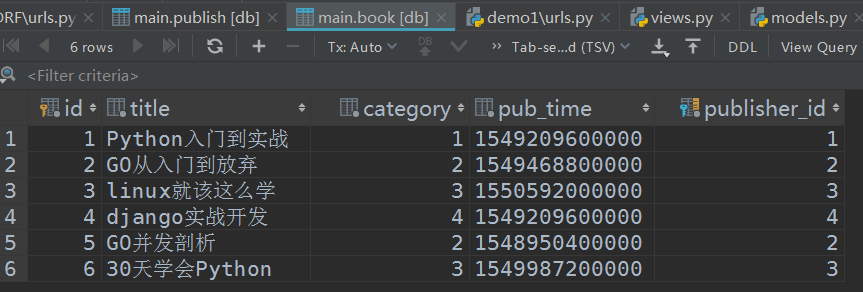
图书表:
为app demo1做路由分发,demo1下创建urls文件,基于CBV式(class-base-view,基于类的视图)的指定url,当然你也可以使用FBV,基于函数的视图函数,不过我建议你使用CBV的,后面你就会体会到了
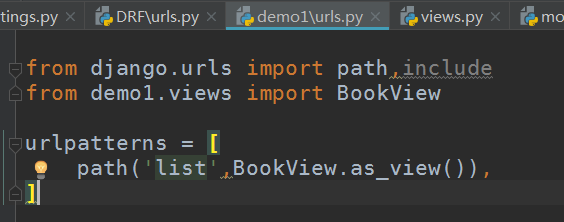
定义视图类对象:
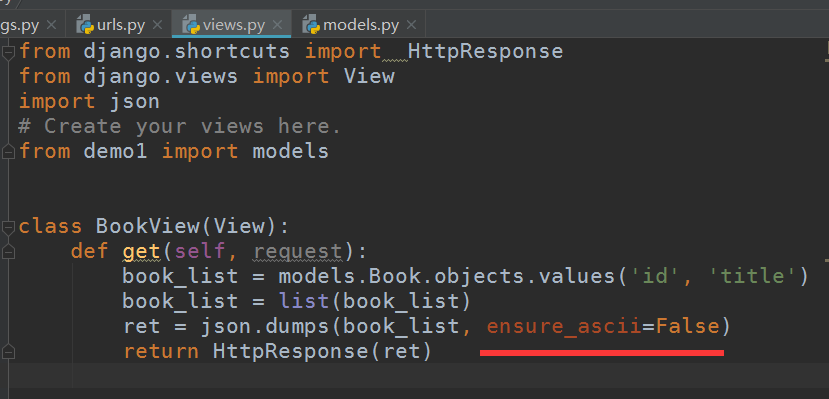
这里注意使用json的dumps时使用ensure_ascii为false,这样在dump序列化时才不会只转为ascii式的数据,导致一些字段不能被ascii表示
启动django,访问/list/:

这样没问题了对吧?
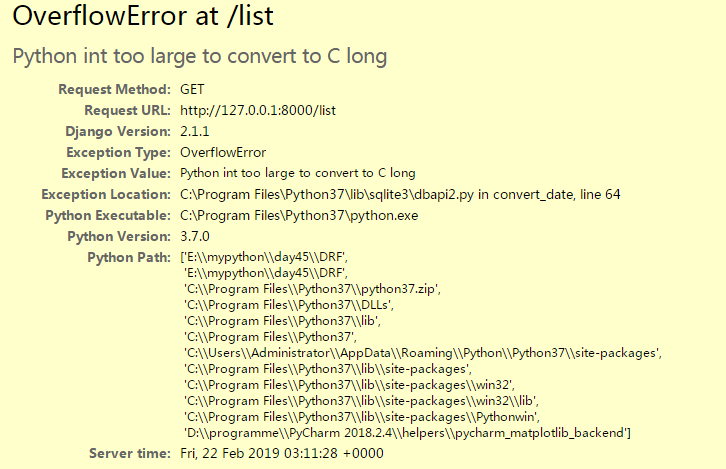
但是如果我取得字段有时间呢?我加一个pub_time字段:
class BookView(View):
def get(self, request):
book_list = models.Book.objects.values('id', 'title','pub_time')
book_list = list(book_list)
ret = json.dumps(book_list, ensure_ascii=False)
return HttpResponse(ret)
再来访问,报错了
好的,这里就要用到 Jsonresponse
Jsonresponse
还是上面的代码,用Jsonresponse返回:
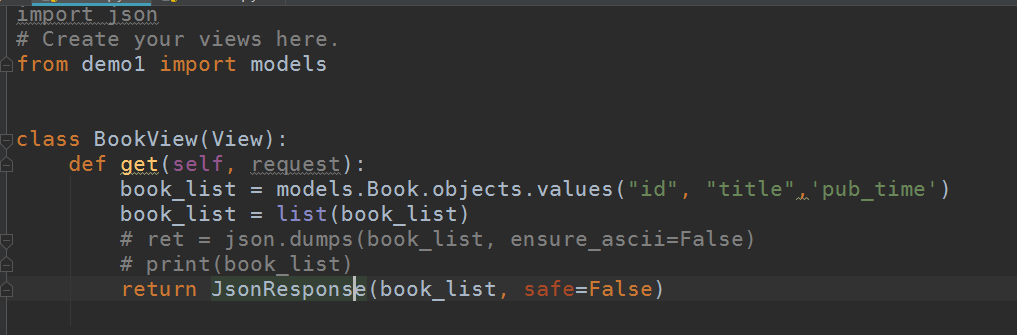
里面加safe参数是因为我们从数据库里取出来的是QuerySet类型,需要转换成list更方便后面的处理。所以传入safe,为什么传入是因为它自己提示的如果是list则传入safe
但是,由于我使用的pycharm,最开始是默认使用的django里带的sqlite3,因为时间显示会默认变成时间戳,在取出数据时会提示:Python int too large to convert to C long,意思就是int类型太长了,也就是说不能被识别为时间类型,所以我做了微调,把数据库改成了mysql,添加的数据有点点不一样,但是不影响
同样的代码,现在再访问,可以了,但是还是有ascii码的问题:

通过Jsonresponse的源码可得,需要再传入一个参数就行:
# coding:utf-8
from django.shortcuts import HttpResponse
from django.http import JsonResponse
from django.views import View
import json
# Create your views here.
from demo1 import models
class BookView(View):
def get(self, request):
book_list = models.Book.objects.values("id", "title", 'pub_time')
book_list = list(book_list)
# ret = json.dumps(book_list, ensure_ascii=False)
# print(book_list)
return JsonResponse(book_list, safe=False, json_dumps_params={'ensure_ascii': False})

如果你打开还是乱码的,你可以考虑换成谷歌浏览器
但是,又来了问题,如果要取出版社publisher字段呢? 图书表中我们只是关联了出版社,此时它就是一个id啊,如果我们要出版社的名字,所以需要再处理:
class BookView(View):
def get(self, request):
book_list = models.Book.objects.values("id", "title", 'pub_time','publisher')
book_list = list(book_list)
ret = []
for field in book_list:
pub_id = field['publisher']
publish_obj = models.Publisher.objects.filter(id=pub_id).first()
field['publisher'] = {
'id':pub_id,
'title':publish_obj.title
}
ret.append(field)
return JsonResponse(ret, safe=False, json_dumps_params={'ensure_ascii': False})

数据是取出来了,但是你应该发现了一个问题,这个太不好维护了,在以后的开发中,肯定是数据很多,外键关联也多,这样一有一个外键关联我们就要重新取处理一次,很麻烦对吧?而且还有choices字段,这个也要处理一下,反正以后遇到任何显示不太符合习惯的都要做下处理,这样是很费时间的,所以聪明的人想到了可以封装一个类或者函数来处理,不过呢,有现成的,django已经给我们封好了一个serializers
django-serializers
代码作适当处理:
# coding:utf-8
from django.shortcuts import HttpResponse
from django.http import JsonResponse
from django.views import View
import json
# Create your views here.
from demo1 import models
from django.core import serializers
class BookView(View):
def get(self,request):
book_list = models.Book.objects.all()
ret = serializers.serialize('json',book_list,ensure_ascii=False)
return HttpResponse(ret)
访问,很直接的就出来了:
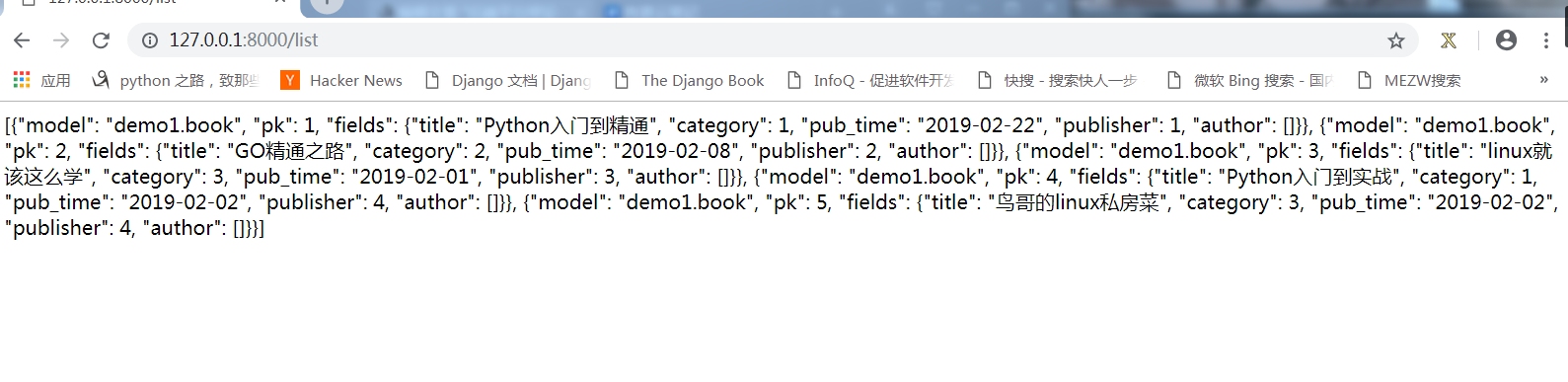
但是还是有点小问题,比如category字段无法显示等的,所以这个serializer相对JSONResponse只是好一点点,还是要再处理,则用DRF
DRF序列化(get)
使用DRF那前提必须得装djagnorestframework

下载完了之后,在django的配置文件settings.py里的app添加此app: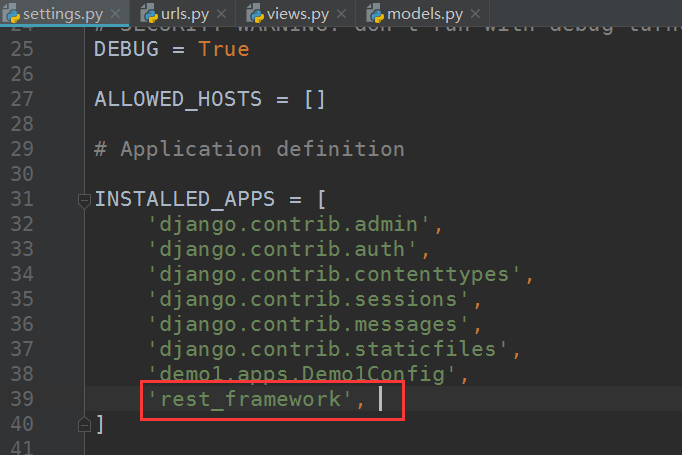
接下来就可以使用rest_framework里的工具模块了
新建一个py文件,名字随意,这里我在demo1的app根目录下新建一个serializers,定义如下的类,对应models表的字段

代码:


from rest_framework import serializers class PublishSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class BookSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES,source='get_category_display') pub_time = serializers.DateField() publisher = PublishSerializer() author = AuthorSerializer(many=True)
视图文件里:
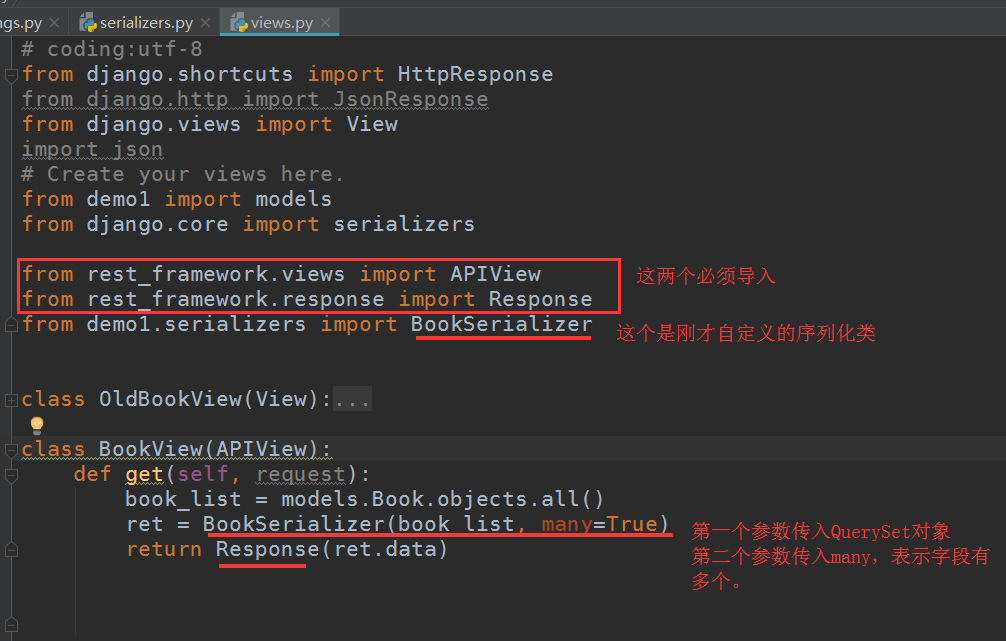
代码:
# coding:utf-8 from django.shortcuts import HttpResponse from django.http import JsonResponse from django.views import View import json # Create your views here. from demo1 import models from django.core import serializers from rest_framework.views import APIView from rest_framework.response import Response from demo1.serializers import BookSerializer class BookView(APIView): def get(self, request): book_list = models.Book.objects.all() ret = BookSerializer(book_list, many=True) return Response(ret.data)
注意视图函数在序列化时用的many和在自定义序列化里用的many属性,两个注意区分,一个代表有多个字段值,一个代表多对多的外键约束
打开浏览器访问: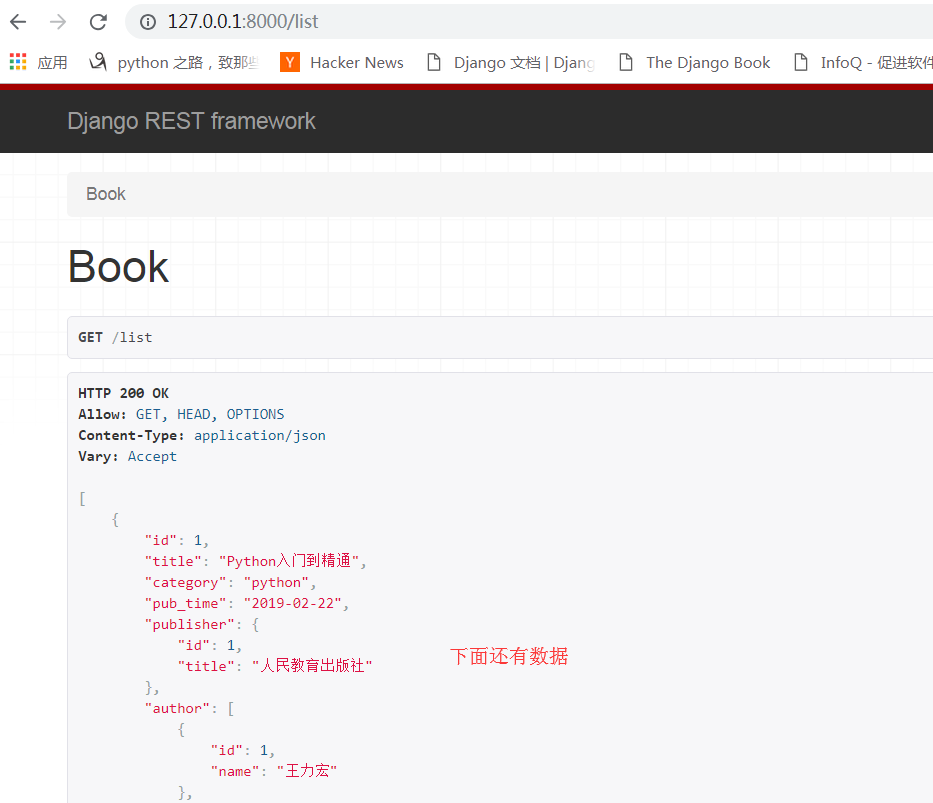
这样就很轻松的取出了相关的值,不需要我们自己再去手动处理了,很方便很实用,以后会经常用到这个序列化类
注:以上的web页面是djangorestframework自己生成的,可以方便的做一些处理
既然有序列化,肯定也还有反序列化的
DRF反序列化(POST)
DRF的serializer不止可以序列化,当然还可以反序列化,这个就和django自己的form和modelform很类似了
对上面的序列化代码进行微调:
序列化类:
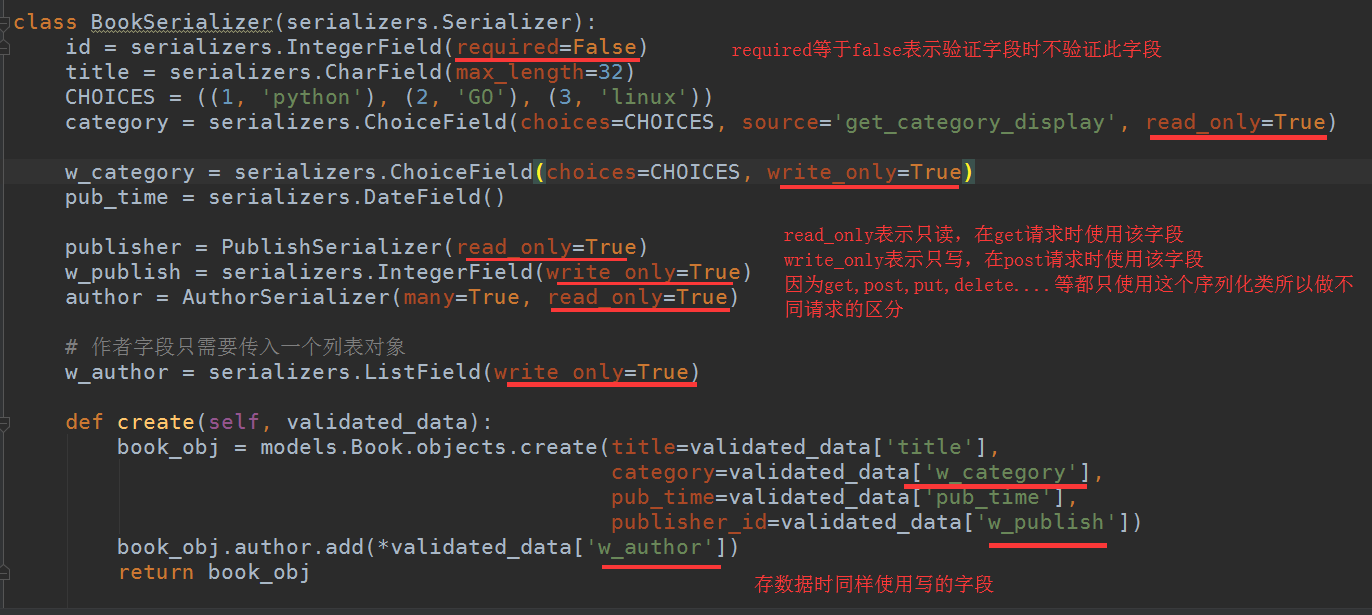
代码:
from rest_framework import serializers from demo1 import models class PublishSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublishSerializer(read_only=True) w_publish = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) # 作者字段只需要传入一个列表对象 w_author = serializers.ListField(write_only=True) def create(self, validated_data): book_obj = models.Book.objects.create(title=validated_data['title'], category=validated_data['w_category'], pub_time=validated_data['pub_time'], publisher_id=validated_data['w_publish']) book_obj.author.add(*validated_data['w_author']) return book_obj
视图函数:
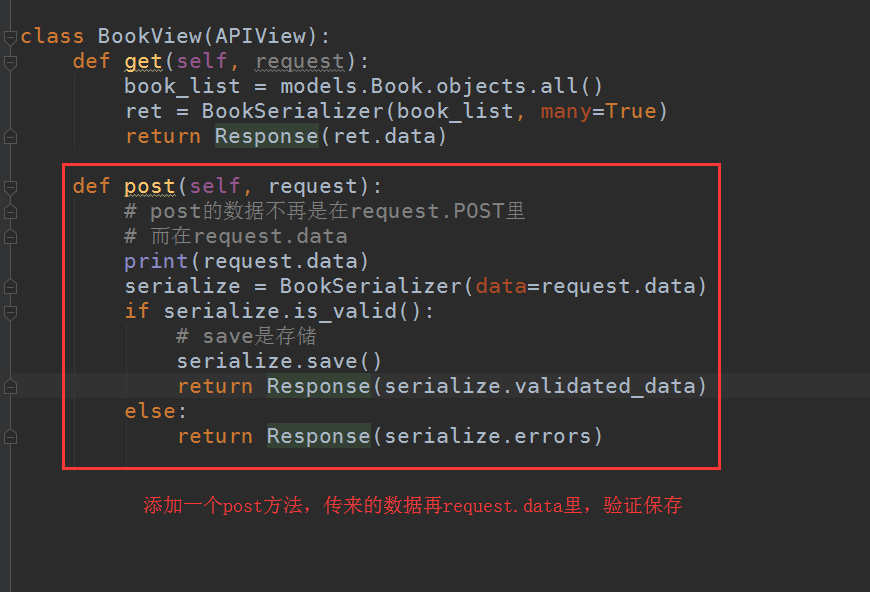
代码:
# coding:utf-8 from django.shortcuts import HttpResponse from django.http import JsonResponse from django.views import View import json # Create your views here. from demo1 import models from django.core import serializers from rest_framework.views import APIView from rest_framework.response import Response from demo1.serializers import BookSerializer class BookView(APIView): def get(self, request): book_list = models.Book.objects.all() ret = BookSerializer(book_list, many=True) return Response(ret.data) def post(self, request): # post的数据不再是在request.POST里 # 而在request.data print(request.data) serialize = BookSerializer(data=request.data) if serialize.is_valid(): # save是存储 serialize.save() return Response(serialize.validated_data) else: return Response(serialize.errors)
当再视图里定义了post之后,页面则多了下面的插入框提交数据:
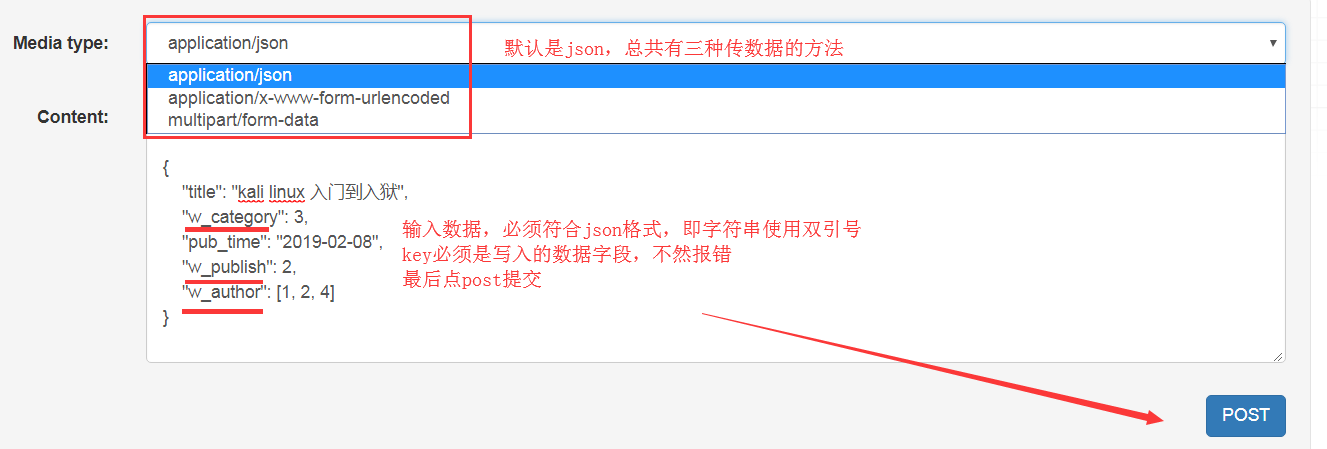
提交后返回结果:
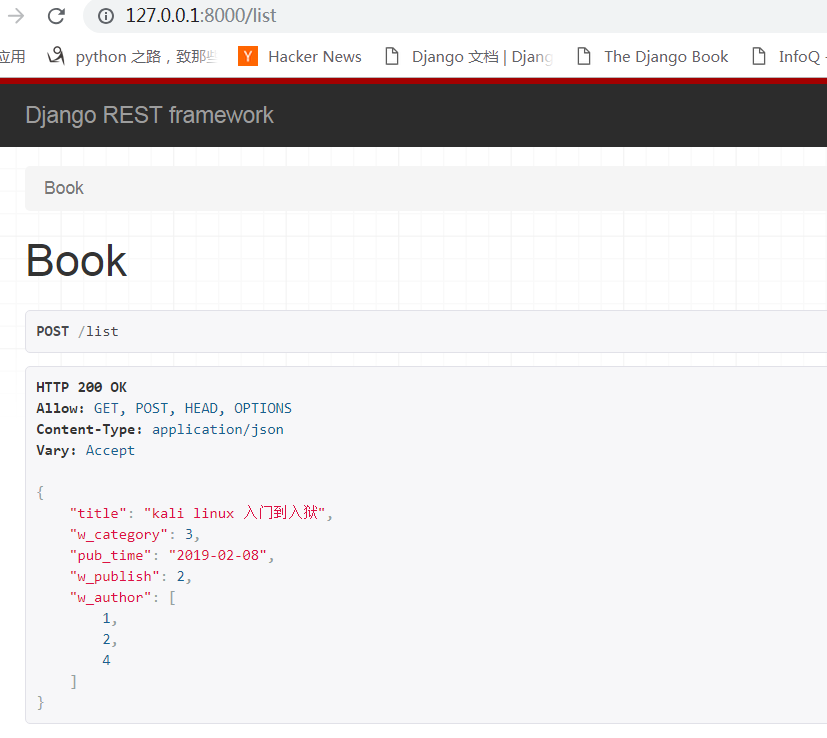
以上步骤就是反序列化
DRF的修改(put)
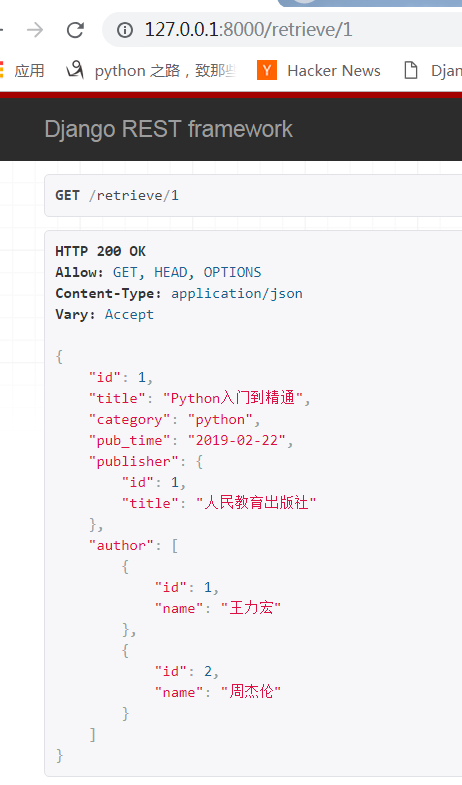
查看单条数据
url:
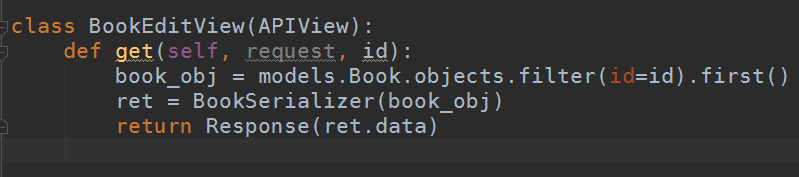
view:
访问:
对单条数据修改
url不变
view,添加一个put方法
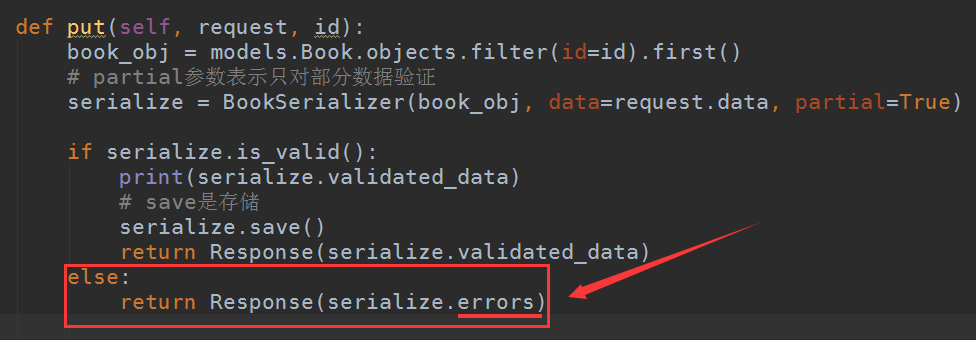
class BookEditView(APIView): def get(self, request, id): book_obj = models.Book.objects.filter(id=id).first() ret = BookSerializer(book_obj) return Response(ret.data) def put(self, request, id): book_obj = models.Book.objects.filter(id=id).first() # partial参数表示只对部分数据验证 serialize = BookSerializer(book_obj, data=request.data, partial=True) print(book_obj) if serialize.is_valid(): # save是存储 serialize.save() return Response(serialize.validated_data) else: return Response(serialize.errors)
序列化器,添加一个update方法
from rest_framework import serializers from demo1 import models class PublishSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) bookdata = { "title": "kali linux 入门到入狱", "w_category": 3, "pub_time": "2019-02-08", "w_publish": 2, "w_author": [1, 2, 4] } class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublishSerializer(read_only=True) w_publish = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) # 作者字段只需要传入一个列表对象 w_author = serializers.ListField(write_only=True) def create(self, validated_data): book_obj = models.Book.objects.create(title=validated_data['title'], category=validated_data['w_category'], pub_time=validated_data['pub_time'], publisher_id=validated_data['w_publish']) book_obj.author.add(*validated_data['w_author']) return book_obj def update(self, instance, validated_data): # 次数的instance就是图书表数据库对象 # 以下字段的key值也同样必须使用上面的只写的属性key instance.title = validated_data.get('title',instance.title) instance.category = validated_data.get('w_category',instance.category) instance.pub_time = validated_data.get('pub_time',instance.pub_time) instance.publisher_id = validated_data.get('w_publish',instance.publisher_id) if validated_data.get('w_author'): instance.author.set(validated_data['w_author']) instance.save() return instance
注意以上的字段和前面的只读或者只写那些字段key值非常有关系,在修改时一定要一致
访问页面,并修改:
修改之前数据是这样:
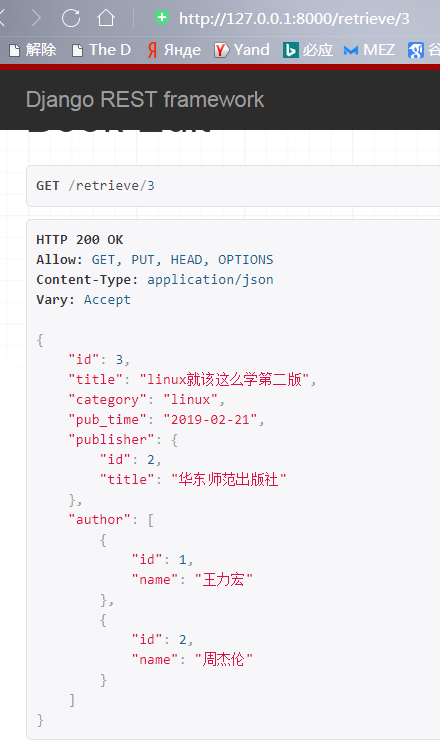
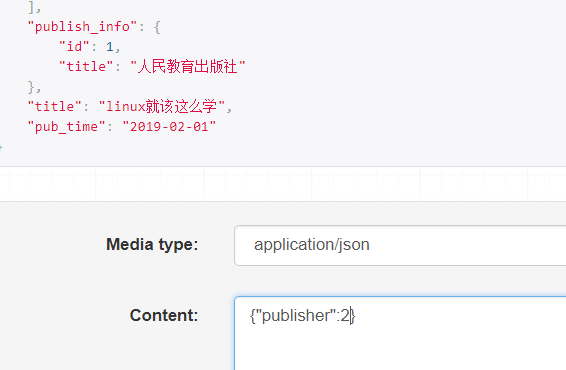
写入以下修改,注意该怎么写怎么写,没有空格缩进之类的,如果数据结尾了,也不要再加逗号分隔,结尾符之类的,不然报json的解析错误(我特么折腾了好半天才反应过来这里的问题):
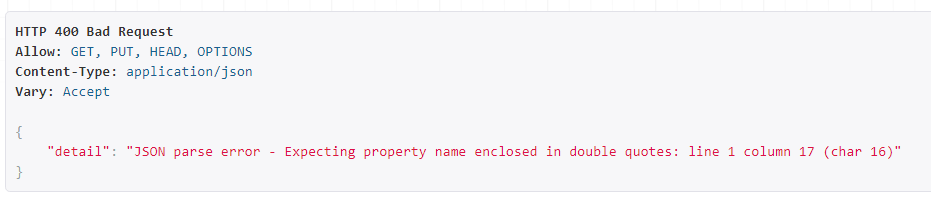
修改字段如下:
{ "title":"linux就该这么学第四版", "pub_time":"2019-02-01", "w_publish":1, "w_author":[3] }
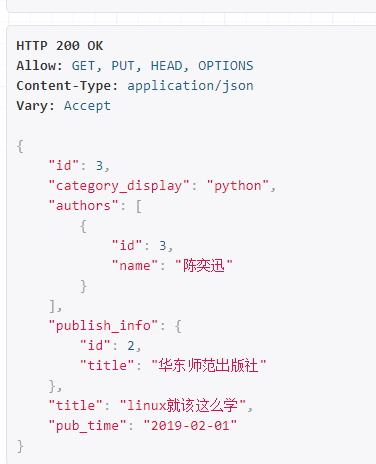
提交得:
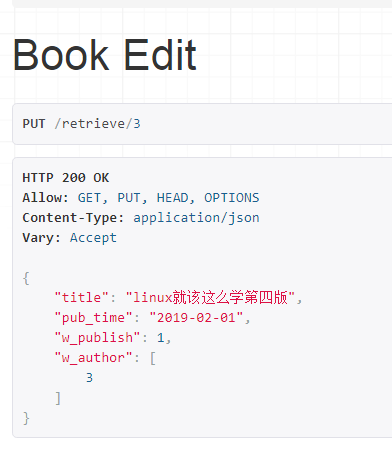
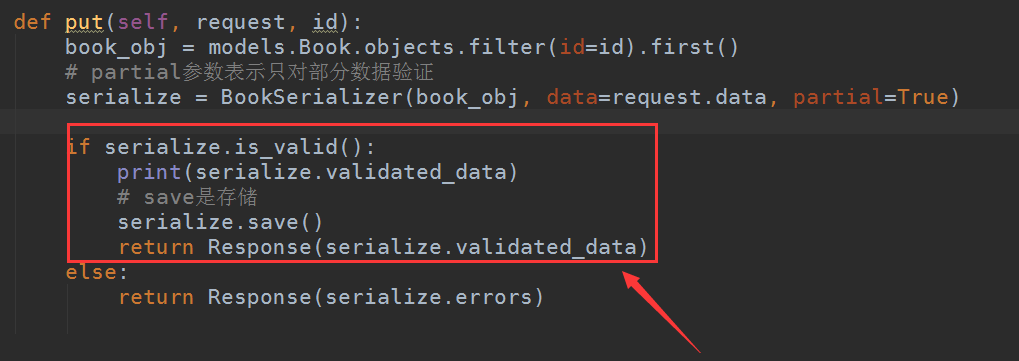
以上返回的结果由这一段代码所得,即已验证后的数据——validated_data
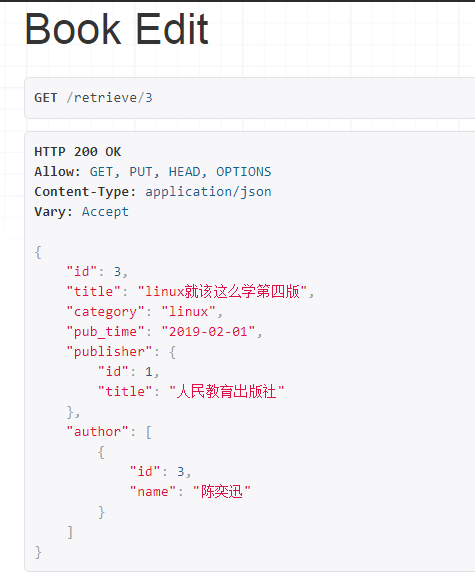
刷新:
注意:在使用rest_framework之后,如果有报错,很多时候rest_framework会把这个报错接管并显示在前端页面,后端页面如果后端逻辑没错的话是不会显示的,导致你根本无法分析错误原因。原因由这一段代码而来:
都说DRF的serializer跟form以及modelform很像,那么自然也有钩子函数验证了
局部验证钩子
例:对title字段做局部验证:
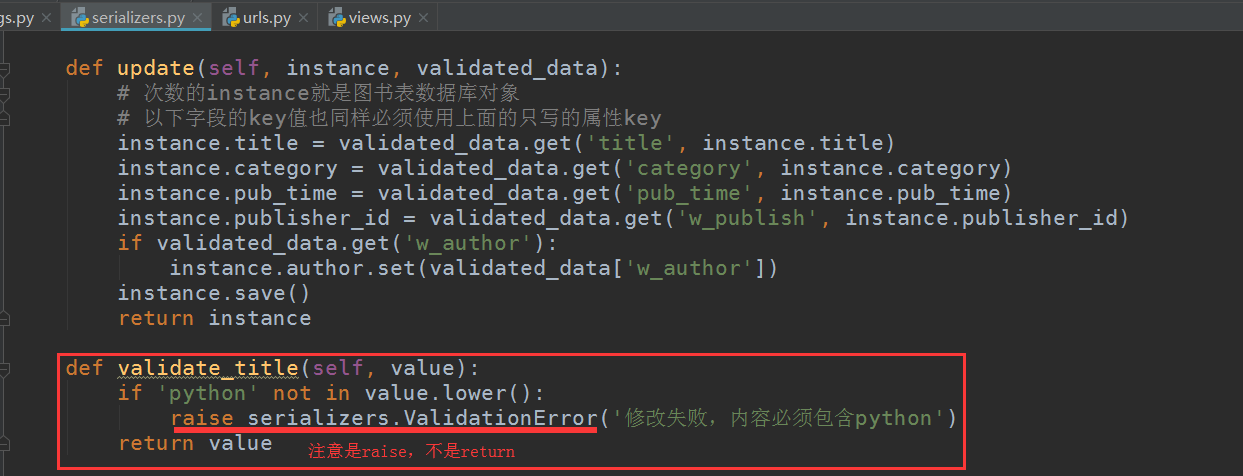
在序列化类添加一个局部钩子方法即可:方法名为validate_XXX(XXX为序列化类定义过的字段名):
代码:
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublishSerializer(read_only=True) w_publish = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) # 作者字段只需要传入一个列表对象 w_author = serializers.ListField(write_only=True) def create(self, validated_data): book_obj = models.Book.objects.create(title=validated_data['title'], category=validated_data['w_category'], pub_time=validated_data['pub_time'], publisher_id=validated_data['w_publish']) book_obj.author.add(*validated_data['w_author']) return book_obj def update(self, instance, validated_data): # 次数的instance就是图书表数据库对象 # 以下字段的key值也同样必须使用上面的只写的属性key instance.title = validated_data.get('title', instance.title) instance.category = validated_data.get('w_category', instance.category) instance.pub_time = validated_data.get('pub_time', instance.pub_time) instance.publisher_id = validated_data.get('w_publish', instance.publisher_id) if validated_data.get('w_author'): instance.author.set(validated_data['w_author']) instance.save() return instance def validate_title(self, value): if 'python' not in value.lower(): raise serializers.ValidationError('修改失败,内容必须包含python') return value
访问页面修改测试:
点击put得:
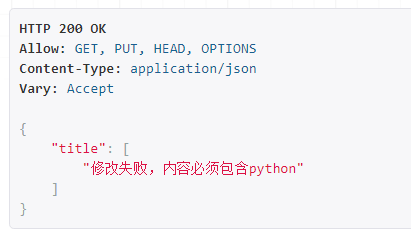
完事儿了。有局部钩子,自然也有全局钩子
全局验证钩子
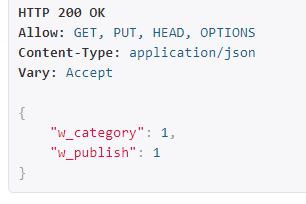
例:验证修改的出版社和作者的id必须都为1,不然报错:
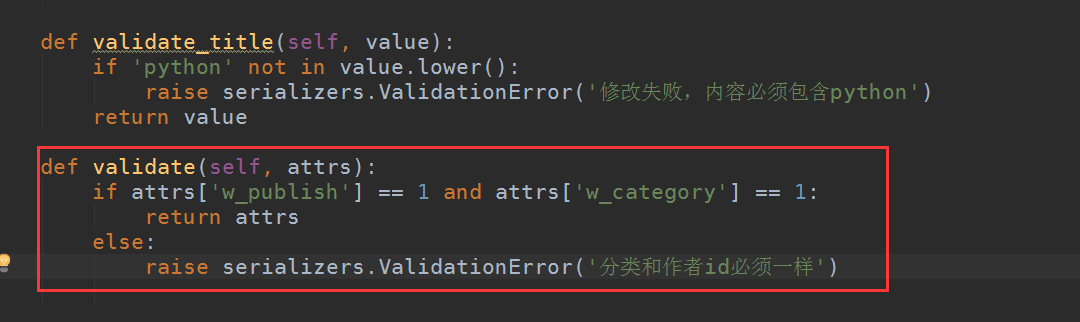
代码:
class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublishSerializer(read_only=True) w_publish = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) # 作者字段只需要传入一个列表对象 w_author = serializers.ListField(write_only=True) def create(self, validated_data): book_obj = models.Book.objects.create(title=validated_data['title'], category=validated_data['w_category'], pub_time=validated_data['pub_time'], publisher_id=validated_data['w_publish']) book_obj.author.add(*validated_data['w_author']) return book_obj def update(self, instance, validated_data): # 次数的instance就是图书表数据库对象 # 以下字段的key值也同样必须使用上面的只写的属性key instance.title = validated_data.get('title', instance.title) instance.category = validated_data.get('w_category', instance.category) instance.pub_time = validated_data.get('pub_time', instance.pub_time) instance.publisher_id = validated_data.get('w_publish', instance.publisher_id) if validated_data.get('w_author'): instance.author.set(validated_data['w_author']) instance.save() return instance def validate_title(self, value): if 'python' not in value.lower(): raise serializers.ValidationError('修改失败,内容必须包含python') return value def validate(self, attrs): if attrs['w_publish'] == 1 and attrs['w_category'] == 1: return attrs else: raise serializers.ValidationError('分类和作者id必须一样')
访问页面提交测试:
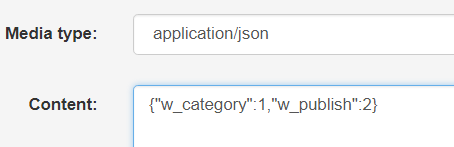
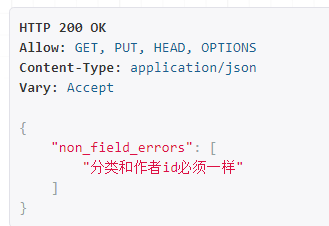
提交得:
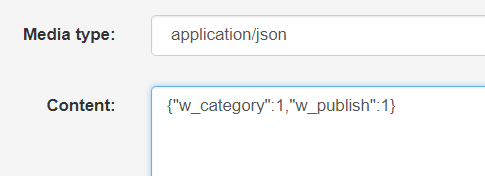
换成都为1的提交测试得:
自定义验证钩子
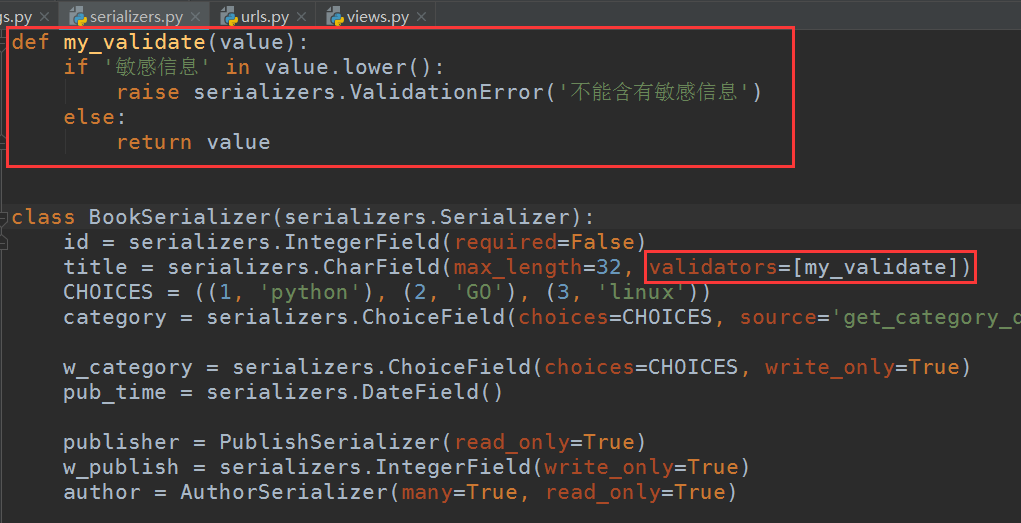
当然还可以自定义一个验证钩子:
代码:
def my_validate(value): if '敏感信息' in value.lower(): raise serializers.ValidationError('不能含有敏感信息') else: return value class BookSerializer(serializers.Serializer): id = serializers.IntegerField(required=False) title = serializers.CharField(max_length=32, validators=[my_validate]) CHOICES = ((1, 'python'), (2, 'GO'), (3, 'linux')) category = serializers.ChoiceField(choices=CHOICES, source='get_category_display', read_only=True) w_category = serializers.ChoiceField(choices=CHOICES, write_only=True) pub_time = serializers.DateField() publisher = PublishSerializer(read_only=True) w_publish = serializers.IntegerField(write_only=True) author = AuthorSerializer(many=True, read_only=True) # 作者字段只需要传入一个列表对象 w_author = serializers.ListField(write_only=True) def create(self, validated_data): book_obj = models.Book.objects.create(title=validated_data['title'], category=validated_data['w_category'], pub_time=validated_data['pub_time'], publisher_id=validated_data['w_publish']) book_obj.author.add(*validated_data['w_author']) return book_obj def update(self, instance, validated_data): # 次数的instance就是图书表数据库对象 # 以下字段的key值也同样必须使用上面的只写的属性key instance.title = validated_data.get('title', instance.title) instance.category = validated_data.get('w_category', instance.category) instance.pub_time = validated_data.get('pub_time', instance.pub_time) instance.publisher_id = validated_data.get('w_publish', instance.publisher_id) if validated_data.get('w_author'): instance.author.set(validated_data['w_author']) instance.save() return instance def validate_title(self, value): if 'python' not in value.lower(): raise serializers.ValidationError('修改失败,内容必须包含python') return value def validate(self, attrs): if attrs['w_publish'] == 1 and attrs['w_category'] == 1: return attrs else: raise serializers.ValidationError('出版社和作者id必须一样')
访问修改测试:
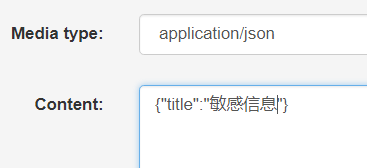
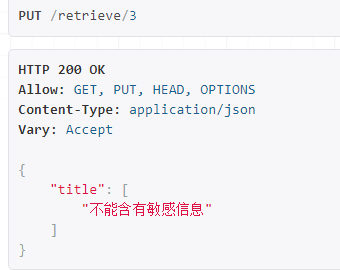
由于我们自定义的验证钩子和局部验证钩子刚好都没通过,都会报错,但是只走了我们自定义的验证钩子,说明自定义验证钩子比默认的局部钩子优先级高
总算问题都解决了,但是感觉还是不太好,我们就这么点功能,序列化类都写了那么多一坨,怎么优化呢?
ModelSerializer序列化
其他都不用变,重新定义一个序列化类,把刚才继承serializer类的自定义序列化类改了其他的名字,现在再定义一个继承Modelserializer的序列化类,名为BookSerializer
代码:
from rest_framework import serializers from demo1 import models class BookSerializer(serializers.ModelSerializer): class Meta: model = models.Book fields = '__all__' depth = 1 # 表示外键查找层级
访问页面:

但是choices字段没有显示,做下稍微的调整
class BookSerializer(serializers.ModelSerializer): category = serializers.CharField(source="get_category_display") # 注意这里是CharField不是ChoicesField class Meta: model = models.Book fields = '__all__' depth = 1 # 表示外键查找层级
访问页面,已显示choices字段:
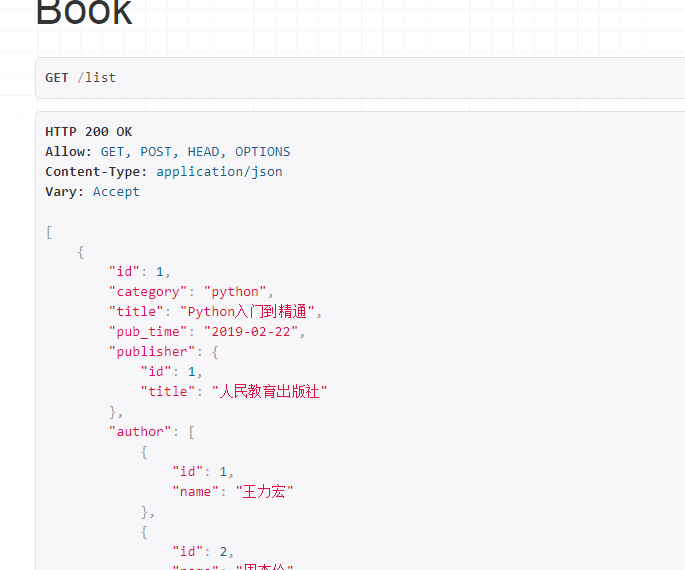
显示部分数据
由于上面的用的field = "__all__",所以默认会把所有字段显示出来
部分显示:
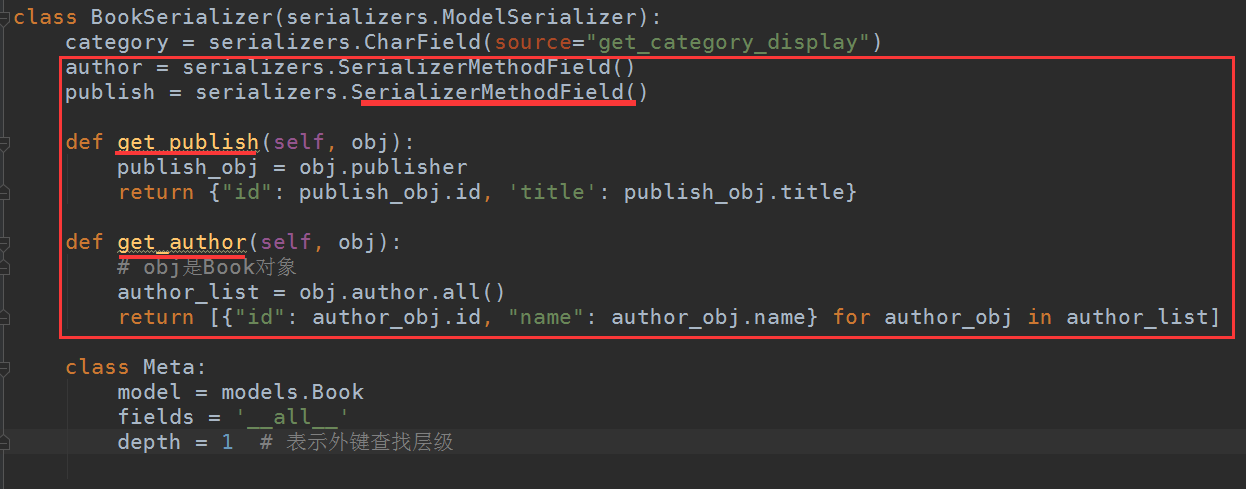
SerializerMethodField意思就是这个字段要通过方法获取,下面的get_XXX是钩子函数,使用了SerializerMethodField都得用钩子函数来获取,XXX字段名必须和定义的一致
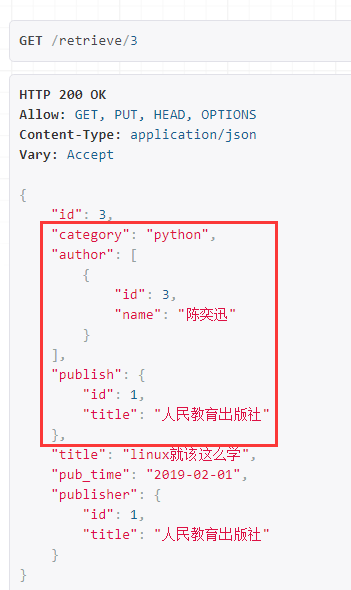
访问显示,会靠前显示我们自定义显示的字段:
ModelSerializer反序列化
那么我们要对其进行修改怎么办呢,想比Serializer,简单很多:
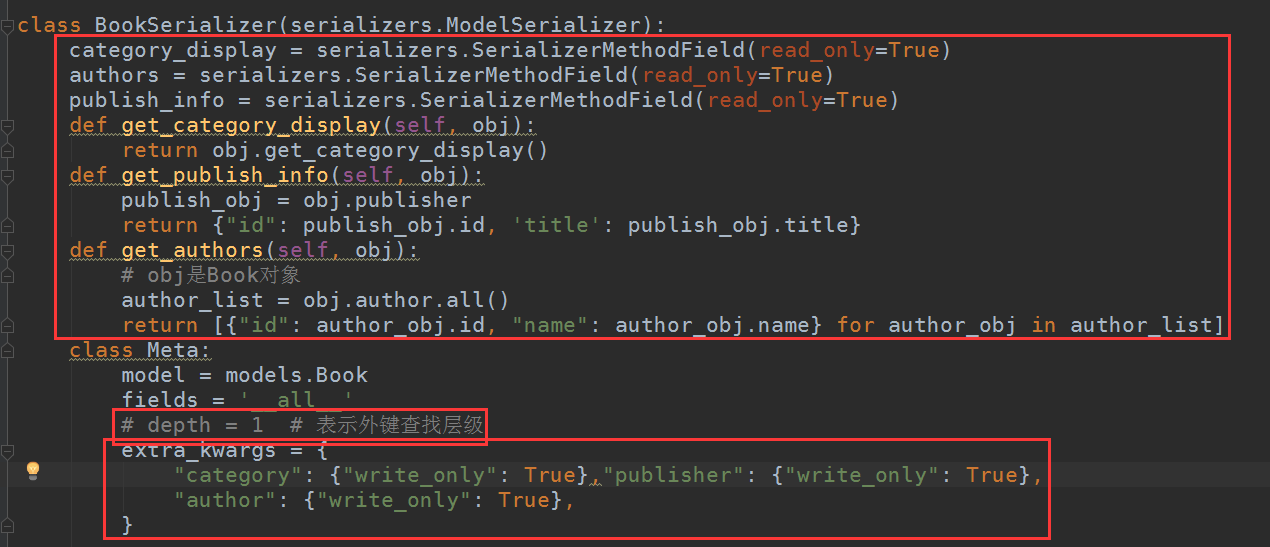
在既有read_only又有write_only时,记得把depth字段注释掉,不然报错,extra_kwargs表示只读访问时不显示,在修改(只写write_only)时才有效
代码:
class BookSerializer(serializers.ModelSerializer): category_display = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) publish_info = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj): return obj.get_category_display() def get_publish_info(self, obj): publish_obj = obj.publisher return {"id": publish_obj.id, 'title': publish_obj.title} def get_authors(self, obj): # obj是Book对象 author_list = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in author_list] class Meta: model = models.Book fields = '__all__' # depth = 1 # 表示外键查找层级 extra_kwargs = { "category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}, }
访问查看:标注字段就是read_only时显示的字段

修改测试一下:
好的,完事儿
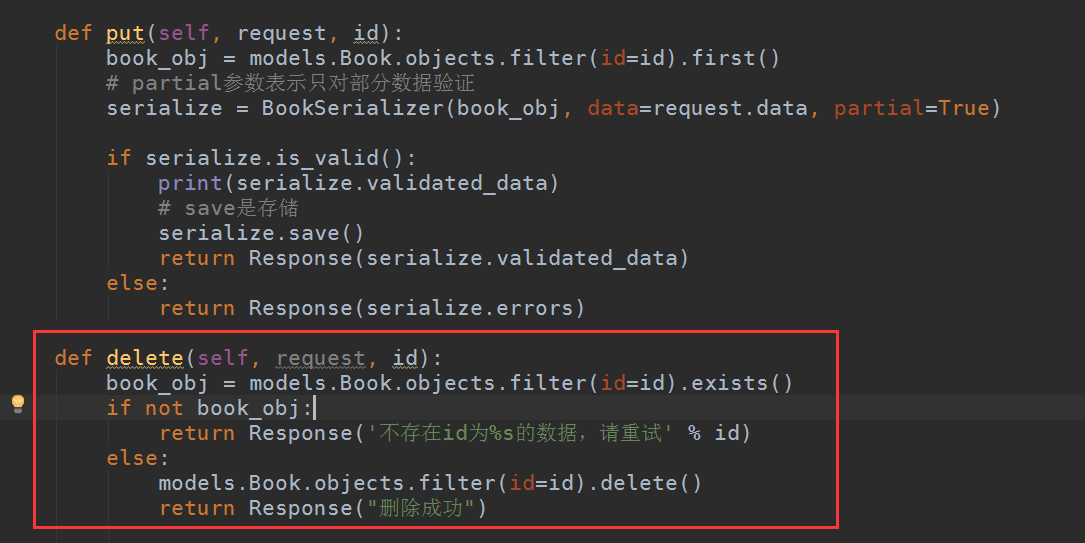
DRF的删除
这个根本上其实与DRF无关,就用django字典的View也可以事先,不过还是在DRF下删除下,增删改查才齐了
没有任何特别的,就在BookEditView视图类里加了下面这段:
访问测试:
这个自动生成的页面就是这样,你写了一个不同的类型的请求方法就会多个请求的按钮
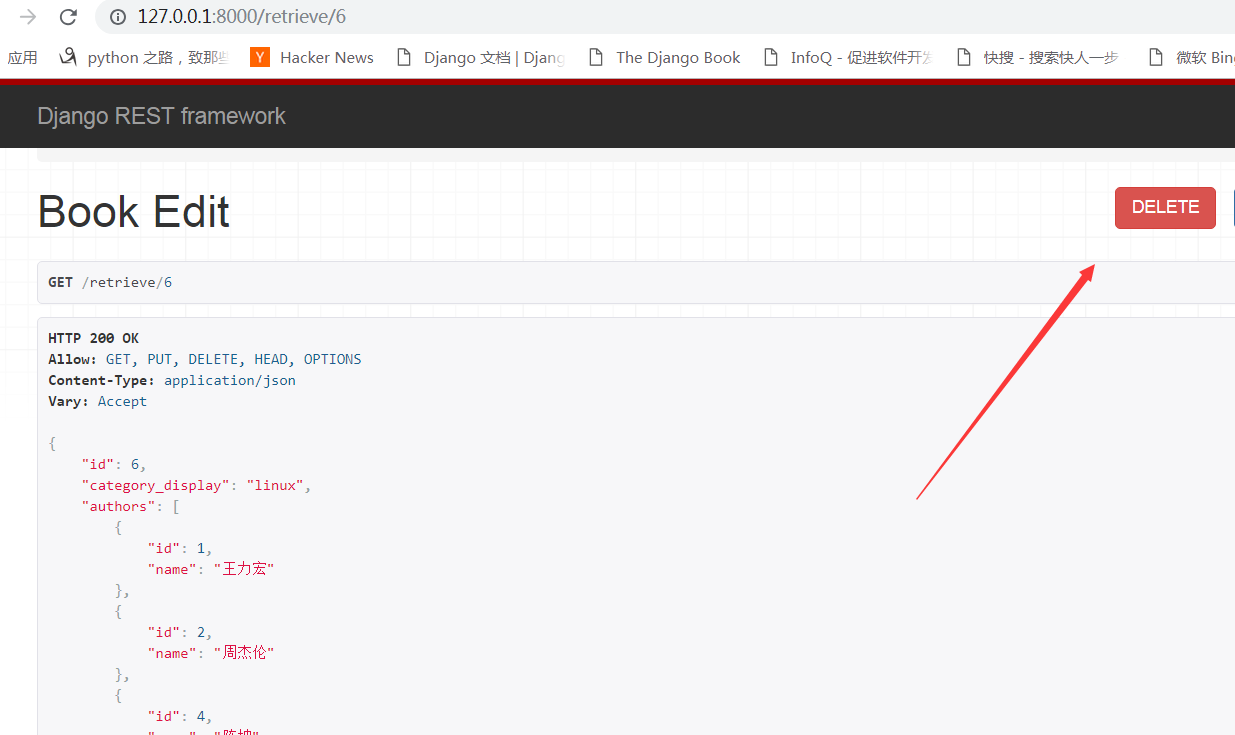
点击delete,删除成功
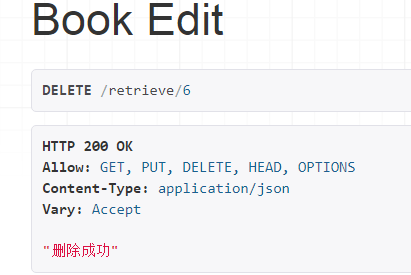
然后再在整个视图组件里稍微的改下,就是把那些增删改操作正确时返回,就返回下正常的数据,而不是返回验证通过的数据:
例:
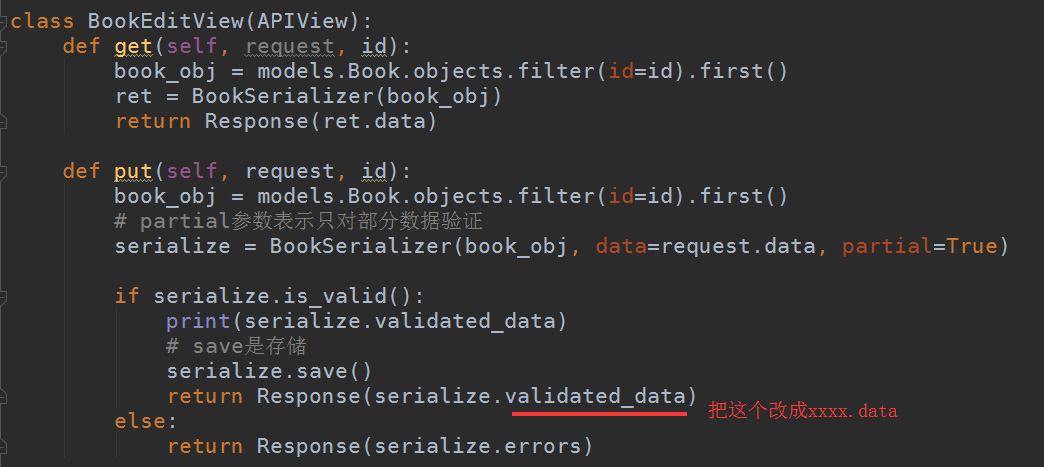
代码:
# coding:utf-8 from django.shortcuts import HttpResponse from django.http import JsonResponse from django.views import View import json # Create your views here. from demo1 import models from django.core import serializers from rest_framework.views import APIView from rest_framework.response import Response from demo1.serializers import BookSerializer class BookView(APIView): def get(self, request): book_list = models.Book.objects.all() ret = BookSerializer(book_list, many=True) return Response(ret.data) def post(self, request): # post的数据不再是在request.POST里 # 而在request.data print(request.data) serialize = BookSerializer(data=request.data) if serialize.is_valid(): # save是存储 serialize.save() return Response(serialize.data) else: return Response(serialize.errors) class BookEditView(APIView): def get(self, request, id): book_obj = models.Book.objects.filter(id=id).first() ret = BookSerializer(book_obj) return Response(ret.data) def put(self, request, id): book_obj = models.Book.objects.filter(id=id).first() # partial参数表示只对部分数据验证 serialize = BookSerializer(book_obj, data=request.data, partial=True) if serialize.is_valid(): # print(serialize.validated_data) # save是存储 serialize.save() return Response(serialize.data) else: return Response(serialize.errors) def delete(self, request, id): book_obj = models.Book.objects.filter(id=id).exists() if not book_obj: return Response('不存在id为%s的数据,请重试' % id) else: models.Book.objects.filter(id=id).delete() return Response("删除成功")
序列化相关的还有很多,以上是主要的,更多的可以查看DRF的官方文档:传送门
好了,关于前后端分离,后端开发的序列化数据部分就到这