一,前期说明
什么是selenium grid,它就是selenium的三大控件之一,三大控件就是selenium WebDriver,selenium Grid,selenium IDE
selenium IDE:负责录制,回放脚本,模拟用户对页面的真是操作
selenium WebDriver:提供强大的浏览器APi操作,覆盖浏览器有:chrome,firefox, microsoft edage,safari,ie等
selenium Grid:用于分布式自动化测试,通过控制多台机器,多个浏览器并行执行测试用例的
说白了就是selenium grid就是用来做selenium 分布式集群的,方便控制,不用每个项目或者每个浏览器操作脚本就重写一套selenium代码,然后各自执行,到后面把项目部署到服务器上,一个一个部署,那确实有点累
二,环境部署准备
没什么好准备的,直接用docker镜像,当然你要想在本地搭建一个或者不喜欢用docker,也可以,去selenium官网下载工具:点我
我这里就还是用docker了,安装docker过程就省略了
拉取镜像:
1.拉取hub镜像
docker pull selenium/hub
这里的hub你可以理解为master或者server端,它自己不会作为执行端,而是调度端,用于调度各个node节点
2.拉取node镜像
docker pull selenium/node-chrome
这里的node你可以理解为salve或者client端,作为执行端
然后,因为目前的话,node镜像有很多种:
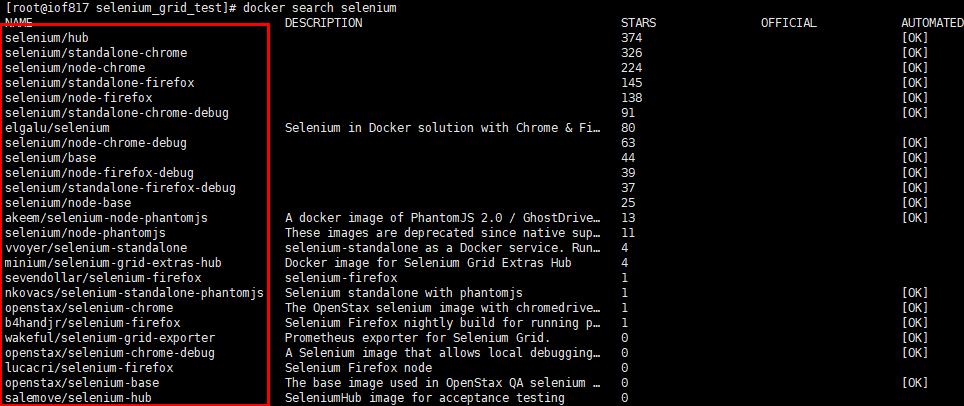
我这里就选用chrome版了,看你们个人喜好选用,另外,由于我喜欢实时的看到操作界面,所以我选用了selenium/node-chrome-debug,带有debug字眼的
docker pull selenium/node-chrome-debug
3.查看开启可用端口
查看当前开启的端口:
firewall-cmd --list-ports
涉及安全隐私,我就不给图了
再看dokcer里有多少已经用过的端口:
docker ps
涉及安全隐私,也不给图了
看到都用到35005上了,那么我们就从35006开始用,先开启端口:
firewall-cmd --add-port=35000-35010/tcp --permanent
ok,后面就开始部署了
开始部署
1.启动hub节点
如果你选用的不是docker而是之前在官网下载的jar包的话,要这么启动,前提需要安装好java的jdk包才行:
java -jar selenium-server-standalone-3.141.59.jar -role hub -port 5566
docker启动hub节点:
docker run -p 35006:4444 -p 35007:5900 -d --name hub selenium/hub
2.启动node节点:
用jar包文件启动在本地
java -jar selenium-server-standalone-3.141.59.jar -role node -hub http://localhost:5566/grid/register/ -port 5577
在docker里启动:
docker run -d -p 35008:5900 --link hub:hub --name selenium-node1 -e "NODE_APPLICATION_NAME=test1" selenium/node-chrome-debug
说明下:
- -d意思就是在后台启动,
- -p就是指定端口映射,
- –link就是连接到hub,如果连接远程的话,就是 --link hub:远程地址
- --name 为启动的容器取名
- -e 就是指为这个镜像设置的参数(每个镜像所需参数不一样),然后这里设置下node节点的名字为test1
- 最后的selenium/node-chrome-debug就是指我要指定这个镜像来启动
然后再启动一个节点,容器名为selenium-node2,节点名为test2
docker run -d -p 35009:5900 --link hub:hub --name selenium-node2 -e "NODE_APPLICATION_NAME=test2" selenium/node-chrome-debug
当然,你如果不指定以上的参数就是用的默认的设置
以上启动完了之后,查看:docker ps:

三:访问测试
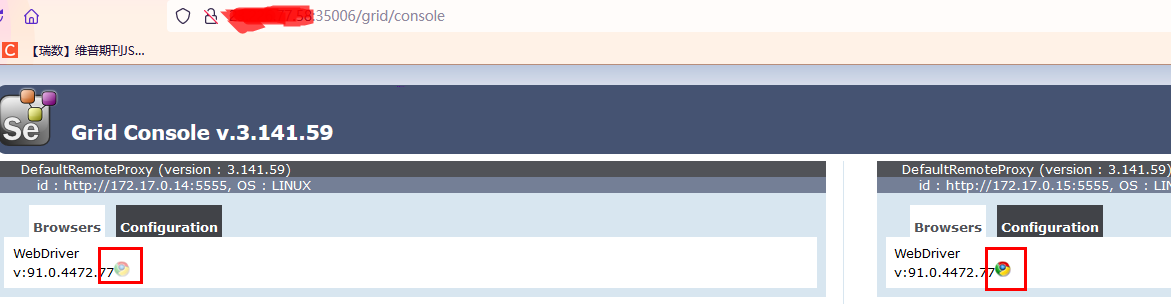
打开web地址: <你的服务器ip>:<port>/grid/console 用浏览器打开看看:

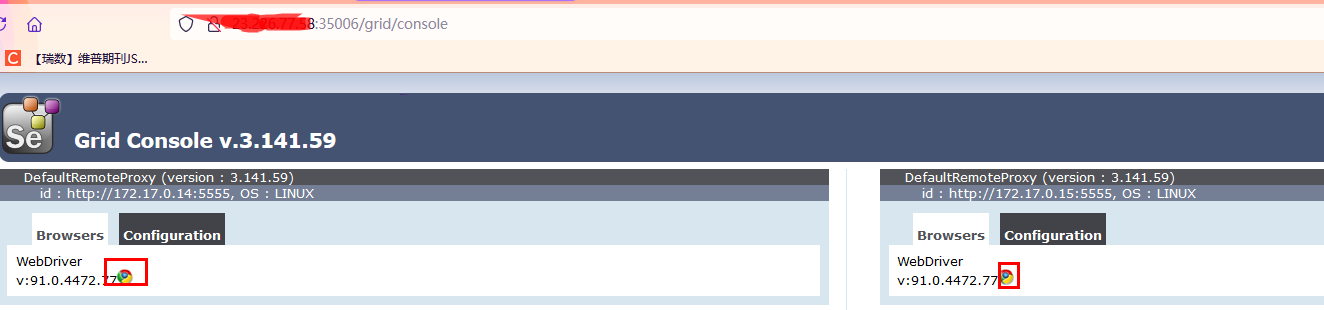
查看配置信息:
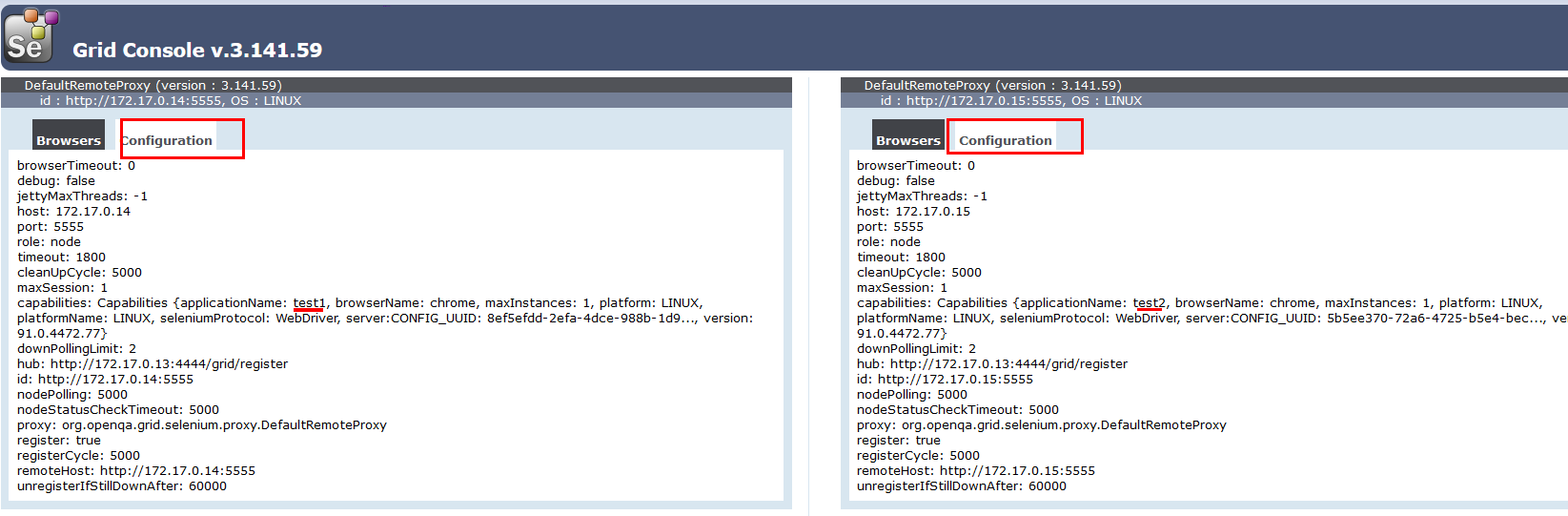
上面的test1和test2就是我们刚才启动node节点时设置的名字了,说明是设置上了的,然后看到默认的额timeout是1800秒,即30分钟
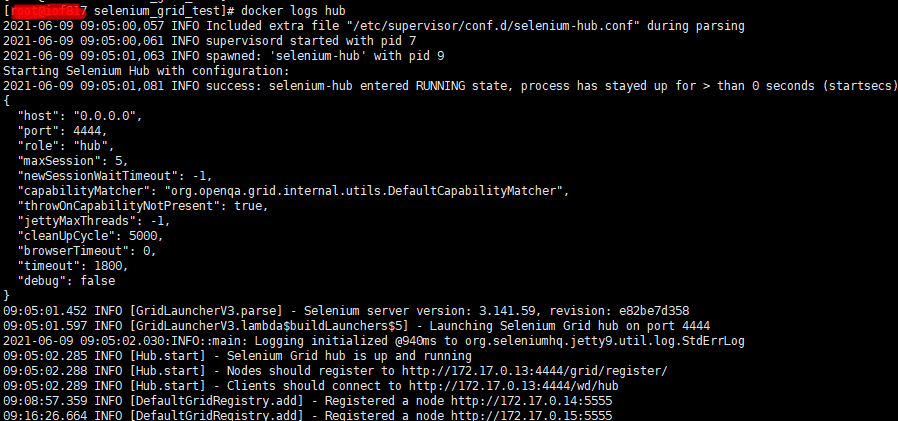
同时可以看看docker的日志:
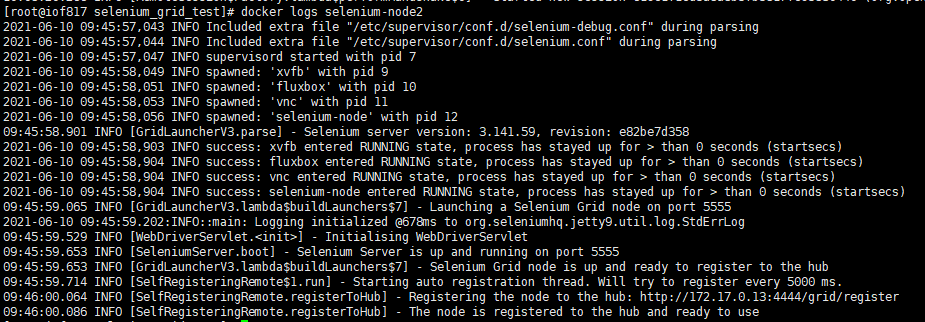
docker logs hub:(这里的hub是容器名)
同时,你也可以用vnc查看,但是我用的vnc viewer老是连不上,最后用了novnc连接成功:
这个,打开的时候会让你输入密码,这个密码是docker的镜像默认的,也就是【secret】,输入之后就会展示下面的界面
然后node2也是一样的,就不展示了,现在我们要用代码控制了:
# coding=utf-8
import time
from selenium import webdriver
chrome_capabilities = {
"browserName": "chrome",
"version": "",
"platform": "ANY",
"javascriptEnabled": True,
'applicationName': 'test1' # 这里指定节点名启动,如果不指定hub则随机选择空闲的node启动
}
browser = webdriver.Remote("http://<你的服务端ip>:<你刚才映射的端口>/wd/hub", desired_capabilities=chrome_capabilities)
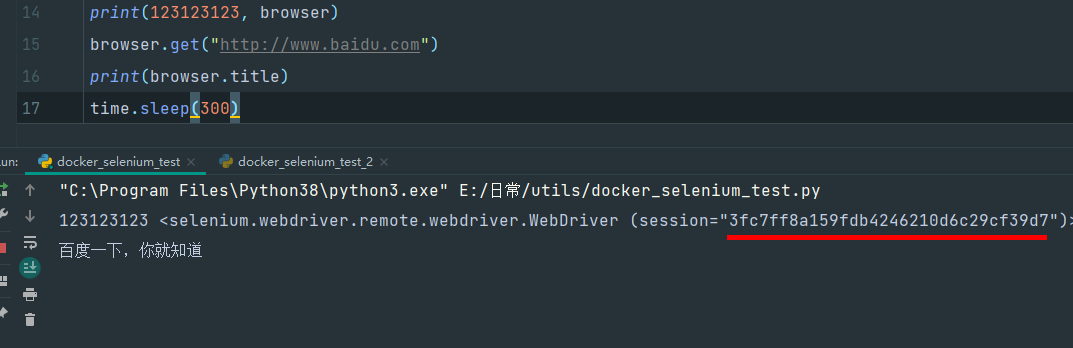
print(123123123, browser)
browser.get("http://www.baidu.com")
print(browser.title)
time.sleep(5)
browser.get_screenshot_as_file("8.png")
browser.quit()
注意后面的/wd/hub这个是固定的啊,然后desired_capabilities可以设置的东西不多,也就上面那几个比较主流点
执行,

同时看到vnc端已经自动展示了:
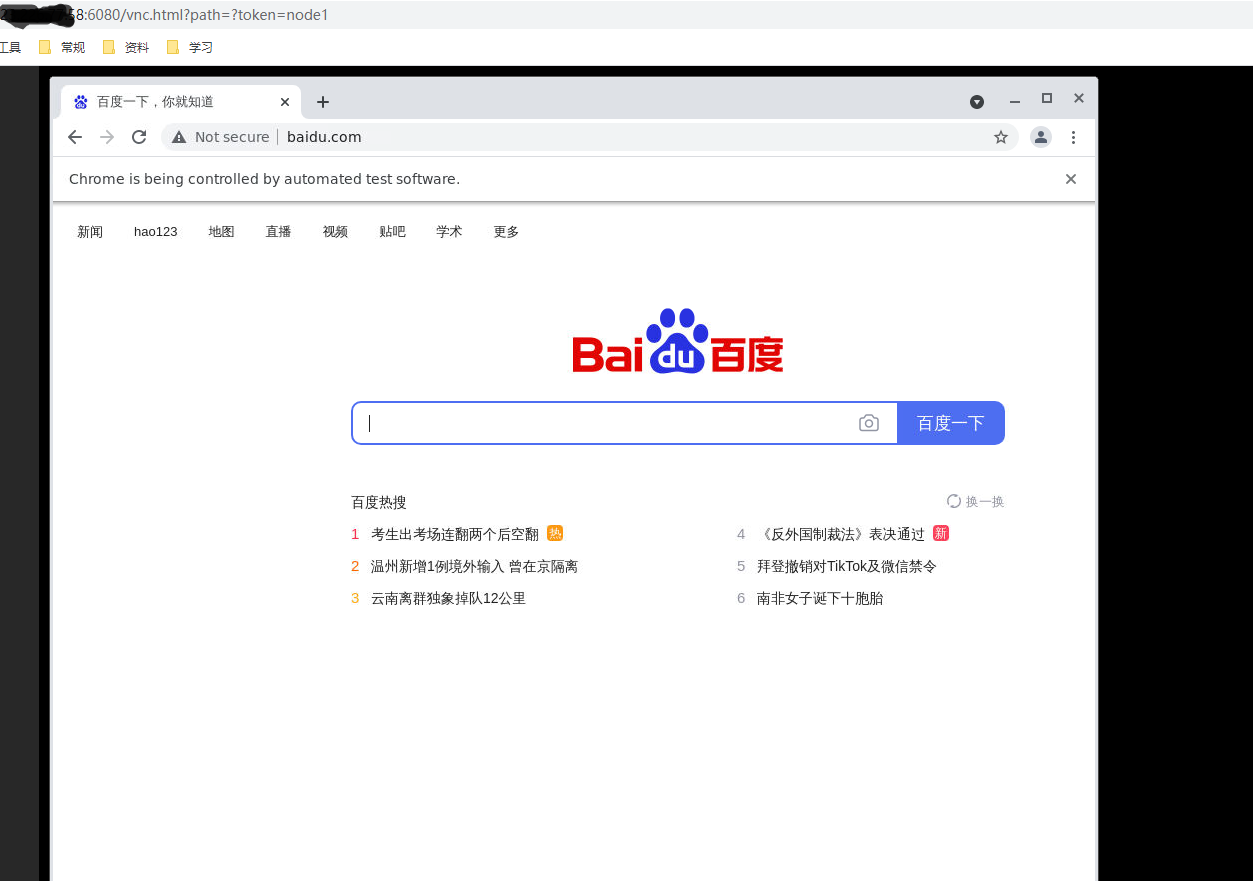
然后也按照设定的5秒自动关闭退出
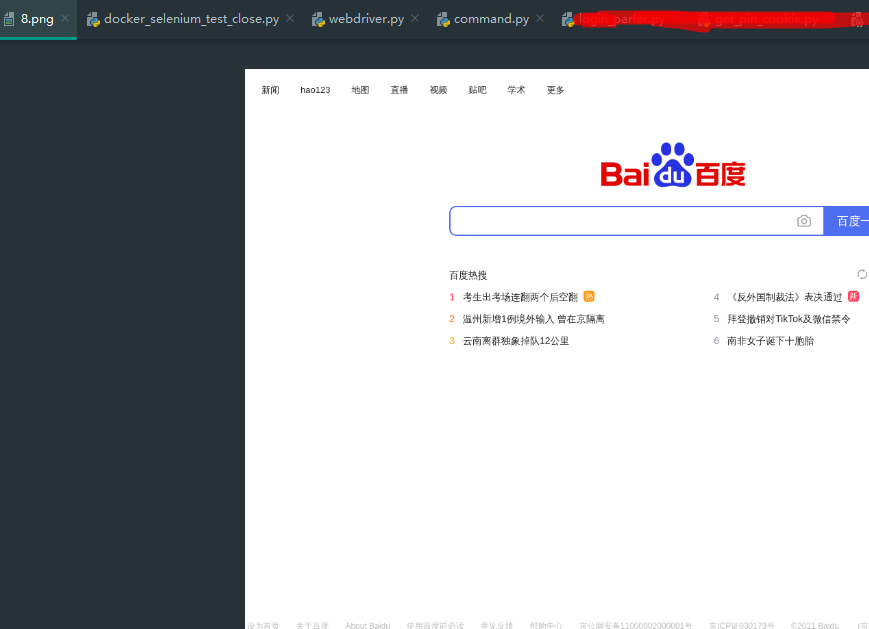
截图的图片也确实是有的:
然后启动test2的node也相同的,就把desired_capabilities里的applicationName的值改成test2就可以指定名为test2的node执行了,就不展示了
四,指定node重开,关闭
以上的操作,并不能很满足我们的需求,假如代码中途报错意外终止,而浏览器窗口没有正常关闭咋办,此时到默认设置的timeout时间段内,该进程一直是在占用资源的,假如后面实际运用起来有很多个node,很多套代码各自执行的话,是很不好管理的,所以就需要指定手动关闭一个窗口,这种怎么处理呢
我查阅大量的资料,都没有直接说怎么关闭,基本都是说的stop掉那个docker容器然后再开,那假如node节点很多,我都不知道哪些正常执行,哪些意外终止呢?怎么处理?
所以,这里需要指定关闭,那怎么关呢,用session id来操作,因为刚才细心的朋友应该看到了,我刚才代码执行的时候,直接打印了下browser对象,它把session显示出来了:

我拿到这个我就知道是哪个窗口了,说明下,这里的session可能不是你理解的类似cookie那种的session会话对象,这个是selenium的一个属性,你可以这么理解,我启动一个selenium出来的浏览器窗口,那么它就是一个session,即使这个窗口可能开了多个标签,那它也是一个session。
那么,我们可以把这个session重新复制给启动的webdriver对象,不就可以关闭了吗?
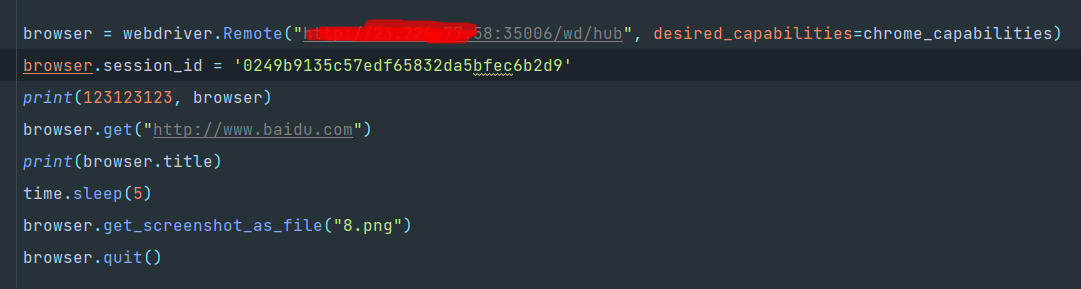
但是运行你就发现,之前的异常导致没有正常关闭的窗口还在,它去另开了一个窗口
这个思路不对吗,对了一半,距离实现真的就差一点,为啥呢,看webdriver.Remote的源码:
当初始化webdriver对象时,session_id是空的:

进到start_session方法里:
发现里面其实调用了execute方法,同时新创建了一个session对象,
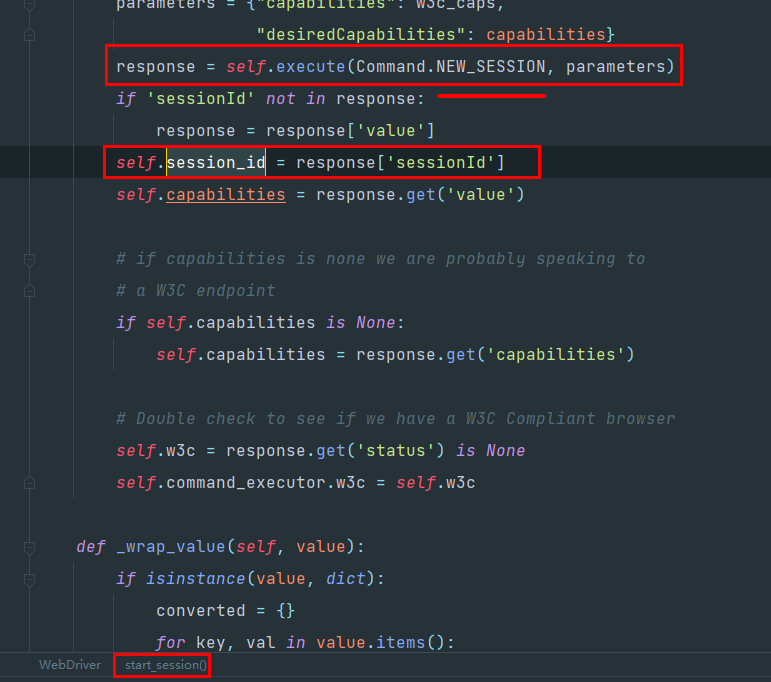
什么意思呢,意思就是,我直接赋值覆盖调session_id是没有用的,因为对象一初始化的时候就已经创建好了一个新的session,也就是一个新的窗口了,根本没法利用之前的session id,那我拿到session id之后可以直接关闭吗,
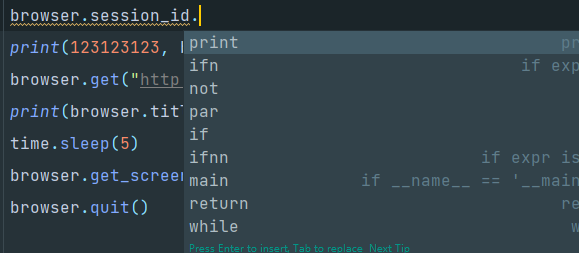
不行,session_id之后没有方法或属性可用了
怎么办,改写start_session方法:
from selenium import webdriver
from selenium.common.exceptions import (InvalidArgumentException,
WebDriverException,
NoSuchCookieException)
from selenium.webdriver.chrome.options import Options
import time
class ReuseChrome(webdriver.Remote):
def __init__(self, command_executor, session_id):
self.rewrite_session_id = session_id
webdriver.Remote.__init__(self, command_executor=command_executor, desired_capabilities={})
def start_session(self, capabilities, browser_profile=None):
"""
重写start_session方法
"""
if not isinstance(capabilities, dict):
raise InvalidArgumentException("Capabilities must be a dictionary")
if browser_profile:
if "moz:firefoxOptions" in capabilities:
capabilities["moz:firefoxOptions"]["profile"] = browser_profile.encoded
else:
capabilities.update({'firefox_profile': browser_profile.encoded})
self.capabilities = Options().to_capabilities()
self.session_id = self.rewrite_session_id
self.w3c = False
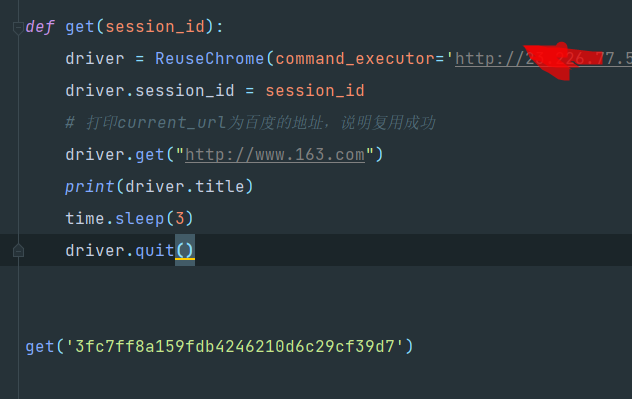
def get(session_id):
driver = ReuseChrome(command_executor='http://<你的服务端ip>:<你刚才映射的端口>/wd/hub', session_id=session_id)
driver.session_id = session_id
driver.get("http://www.baidu.com") # 打印current_url为百度的地址,说明复用成功
print(driver.title)
time.sleep(3)
driver.quit()
get('7696c3eb43f97438229f6763242fd8b9') # 请用实际的session id,如果一个不存在的也会报错
以上,定义了一个类,继承了webdriver.Remote,然后改写了start_session方法,让它不要去重新创建对象
好的,现在执行测试:
还是刚才的执行node的代码,然后停顿300秒模拟程序异常导致没法立即关闭
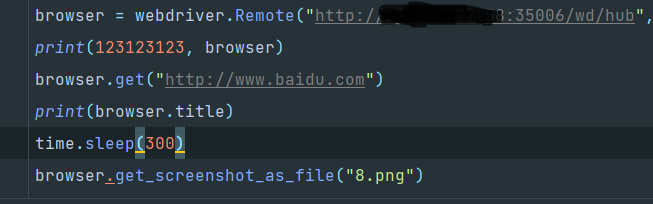
查看管理界面:
左边这个有点灰色,说明是在执行中
鼠标放上去还会有提示:

现在我们执行关闭的脚本,手动传入刚才的session id 3fc7ff8a159fdb4246210d6c29cf39d7
vnc看到打开了163:
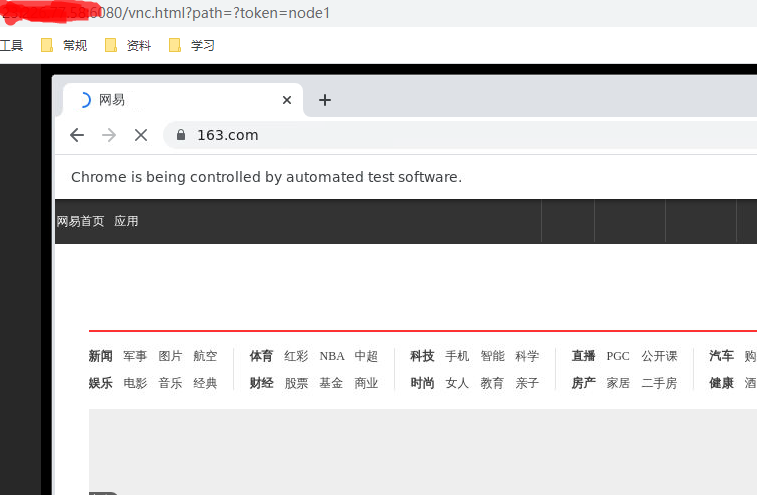
过了3秒,关闭了:
同时这边的管理界面也没有在执行中的状态:
同时这边刚才模拟执行异常这边还在执行
过段时间执行完后会报错,这个不打紧,意思就是没有正常关闭的意思,这个是我模拟sleep的,如果是真是的异常,估计都看不到报错是啥了,得去docker里看日志了

五.为node设置maxsession和超时时间
以上的步骤已经能解决大部分的问题了,但是还是有两个场景没有实现,就是,以上的,一个node只能开一个session,比如下面:
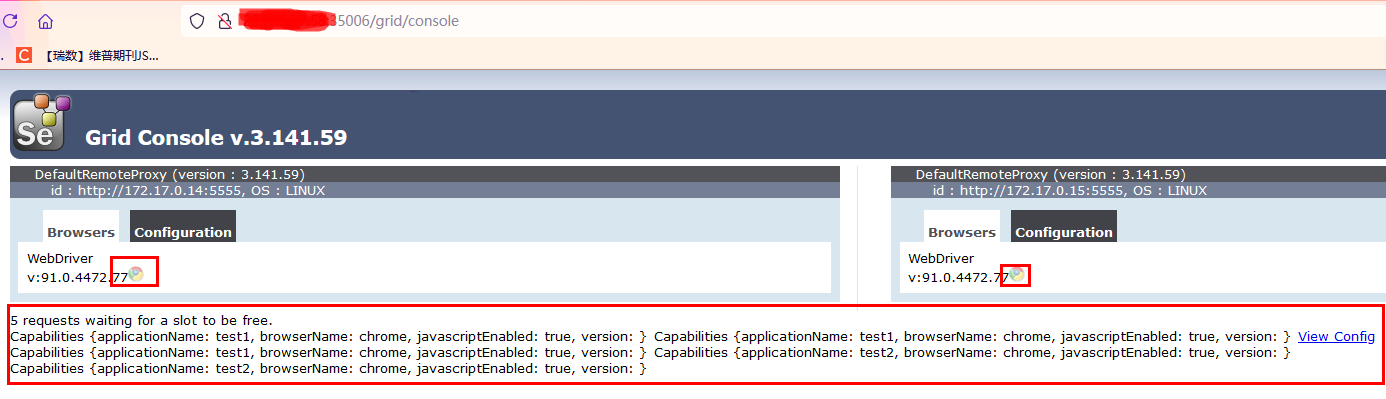
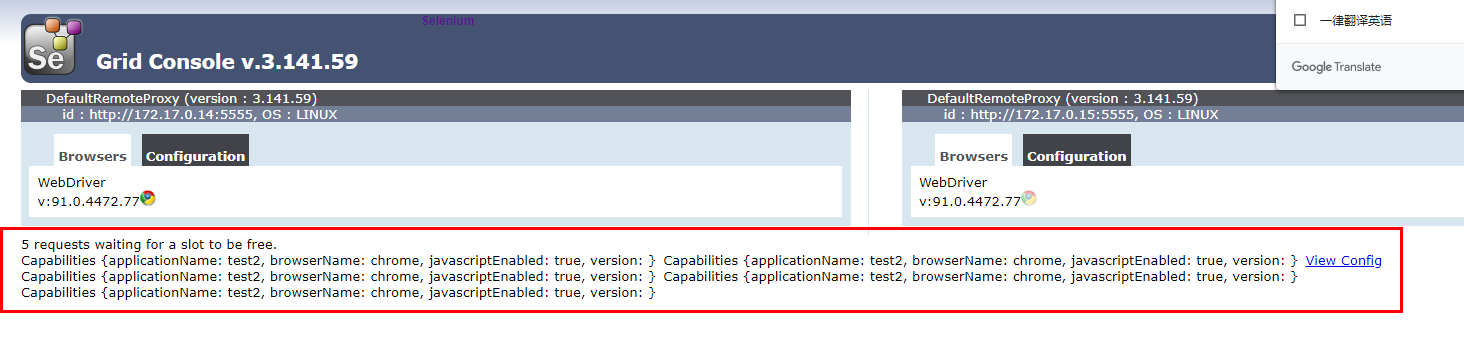
我启动了多次脚本,然后因为可用的session不够,已经超额量的执行,导致阻塞等待了:

管理界面也显示有5个请求还在等待处理
那怎么处理呢?
开多个node?这个是可以,但是这是典型的以磁盘空间来换的,那后期有上百个咋搞呢?而且回到上面说的时间问题,此时,我已经不知道这些session id分别是哪些了,我就算手动的关闭,也是一个一个关闭,它默认的超时时间又是30分钟,我得等这么久才能操作,咋办呢?
这个,目前的话,真的就只能停止docker容器再执行了,因为上面的两个问题只有在创建docker容器,注册到hub时才能设置的,现在已经到这后面了,没法改了
所以,停止docker重来吧:
1.重设置docker容器
镜像不用再拉了,只是启动hub和node重新搞下就行:
docker run -p 35006:4444 -p 35007:5900 -d --name hub -e "GRID_TIMEOUT=30" selenium/hub
docker run -d -p 35008:5900 --link hub:hub --name selenium-node1 -e "NODE_APPLICATION_NAME=test1" -e "NODE_TIMEOUT=30" -e "NODE_MAX_SESSION=5" selenium/node-chrome-debug
说明下,GRID_TIMEOUT是指对hub设置超时时间30秒的处理
NODE_TIMEOUT是指对node节点设置超时时间
NODE_MAX_SESSION是指设置最大的session数量,也就是我们可以在一个节点里开多个窗口而不会被阻塞住了
进入管理界面查看:
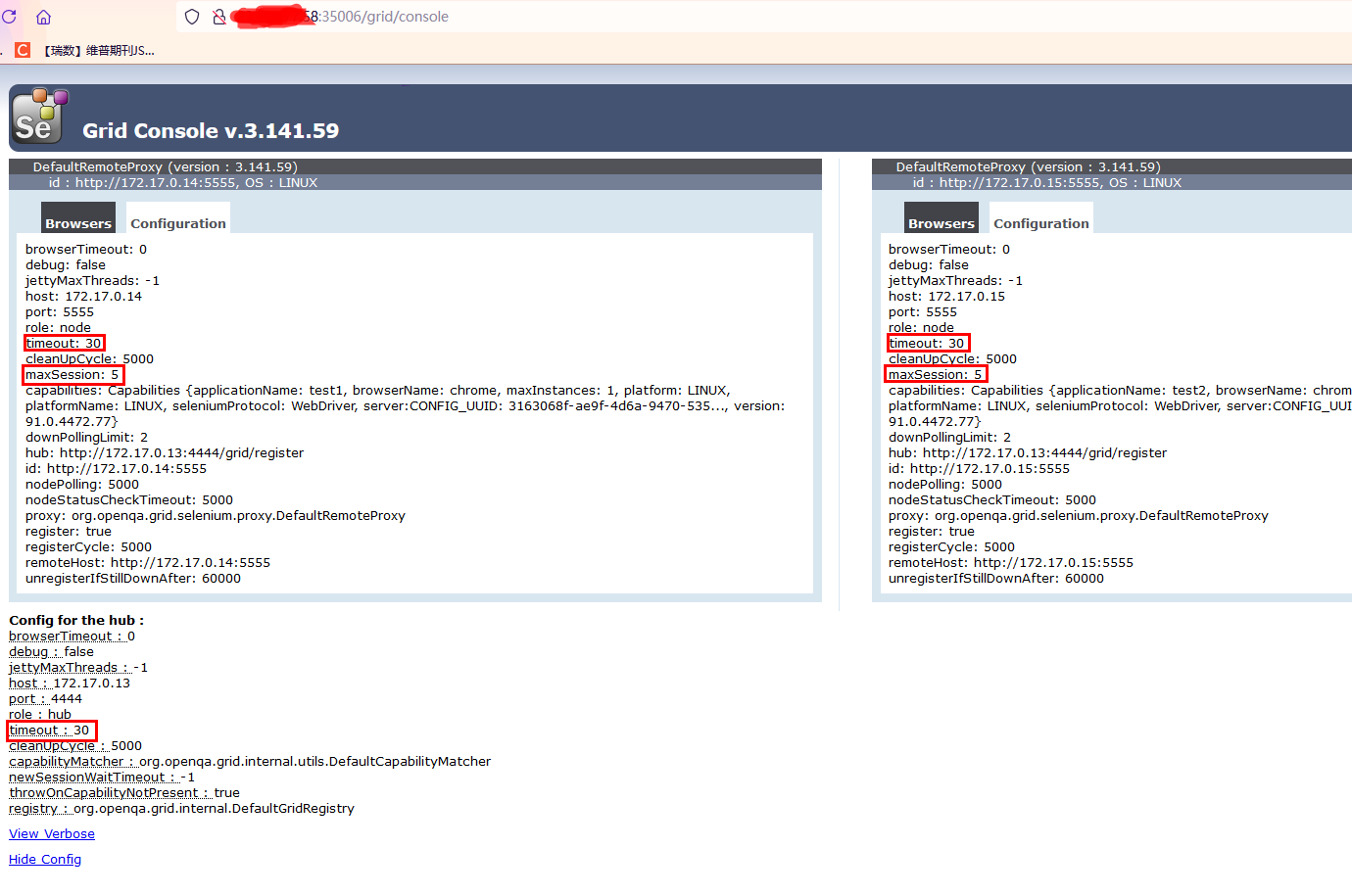
目前来看,应该是设置成功了的
2.测试超时时间
现在再看刚才哪个脚本,就是模拟异常停顿了300秒那个:
先看,目前是空闲状态:
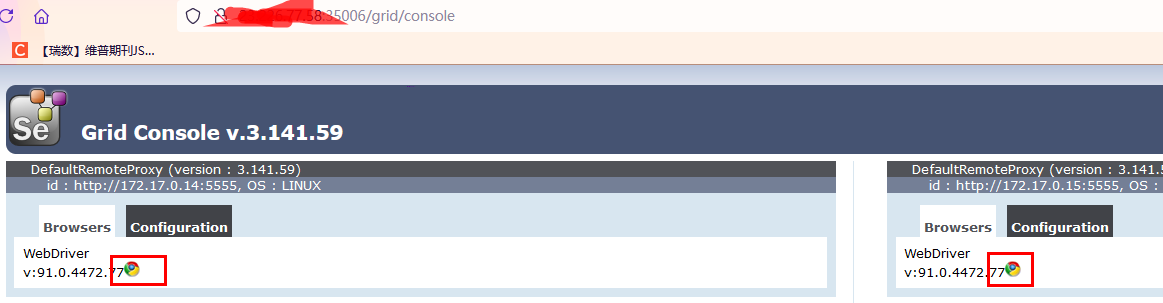


等待30秒,看它会不会自动变成空闲状态
这个管理界面有时候会如此抽风,不用管,多刷几次即可

出来了,果真变成空闲状态了

去docker镜像里看看日志,注意左边我框出来的时间,从9点52分的28秒到53分的04秒的样子自己删除了这个session,为什么不是定死的30秒呢?selenium调起浏览器,再关闭,肯定还是需要一点时间准备资源和释放资源的,这几秒的时间误差其实对我们的项目影响并不大的
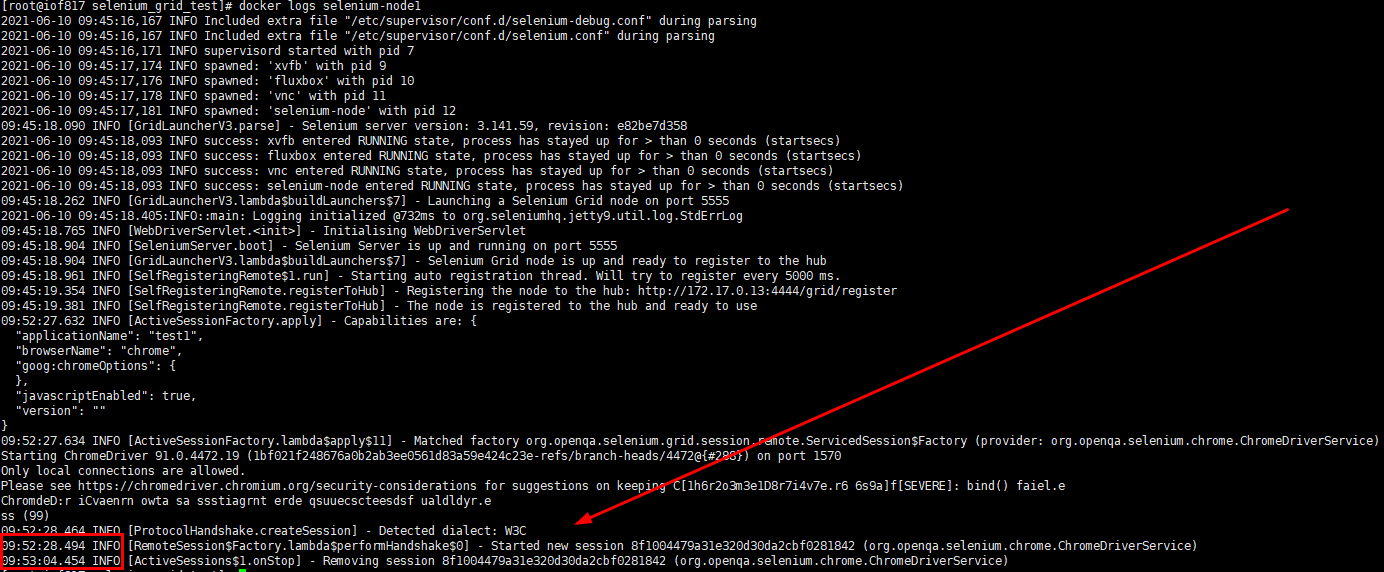
而且这个session id跟上面脚本执行打印出来的id对得上,说明就是它了,没问题,实现了自动关闭
3.测试最大的sessoin
这次还是用的节点test2,因为之前test1执行了一次,为了方便查看日志,这里用test2
现在节点test2还是空的,结尾提示的才入册到hub上
然后使用多线程开了多个来模拟后期被多个项目调用时的场景
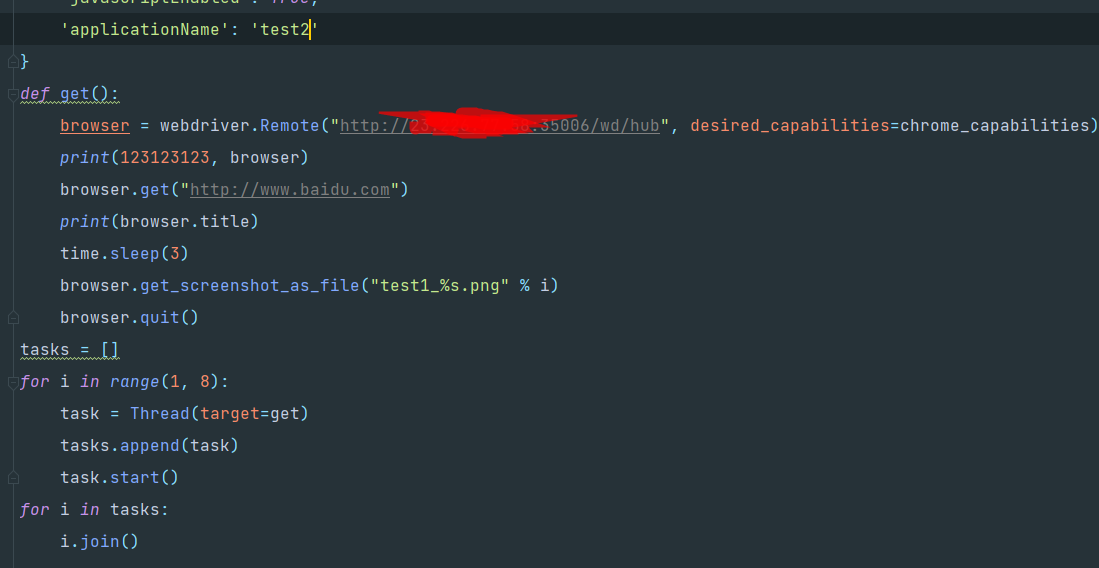
运行
管理界面就立即有了5个请求,为什么是5个啊,因为我们设置的maxSession=5就是同时最多有5个执行的意思了
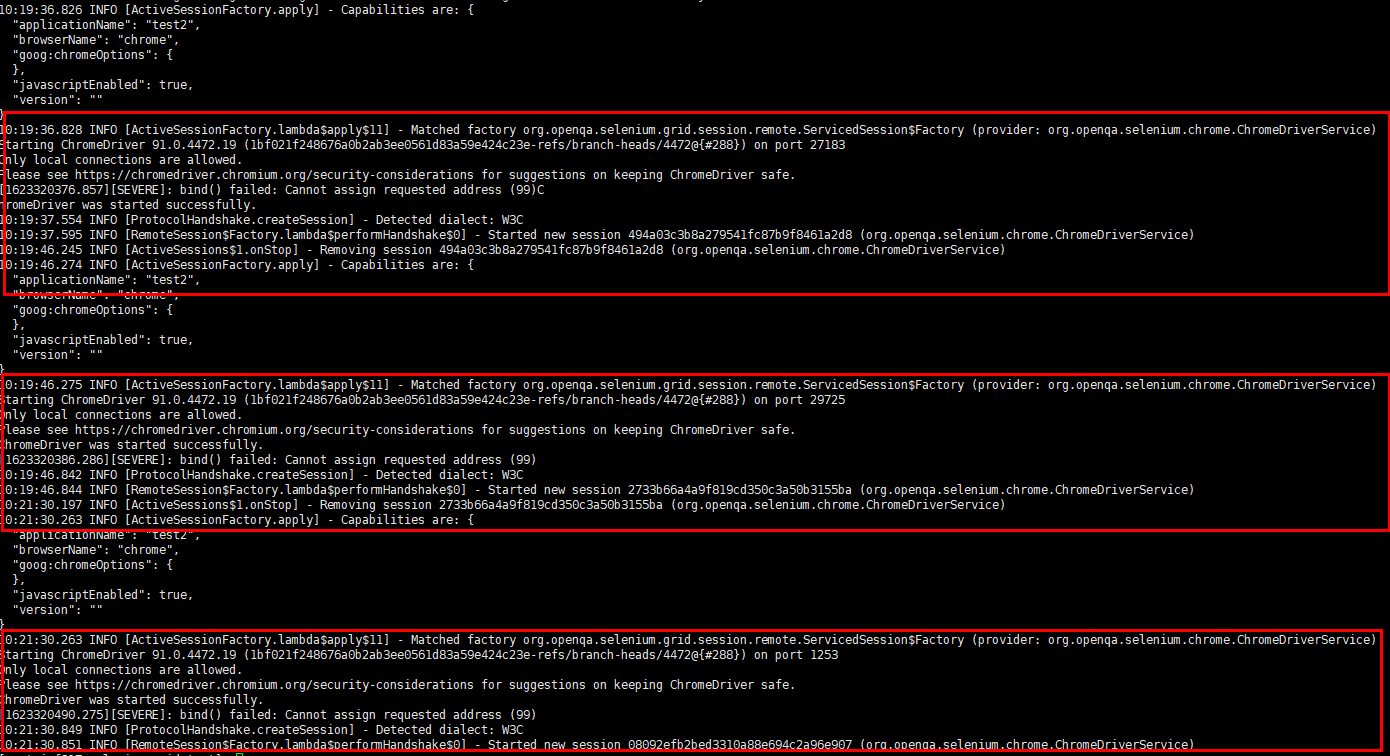
这样看不太出来,看看日志:
现在执行有3个了,
管理界面显示还有4个:

为啥4个,我上面的range是1,8,也就是1-7,上面执行了3,还剩4个
再看管理界面:

还有一个,那日志里肯定已经执行了6个,打开看:



那么最后,也就是说我们设置的maxSession也确实生效了
补充:六.设置maxinstance和比较超时时间
由于容器已经启动起来了,又只有停止删除容器重建了
重建容器:
创建hub:
docker run -p 35006:4444 -p 35007:5900 -d --name hub -e "GRID_TIMEOUT=60" selenium/hub
这次我对hub设置60秒
创建node:
docker run -d -p 35008:5900 --link hub:hub --name selenium-node1 -e "NODE_APPLICATION_NAME=test1" -e "NODE_TIMEOUT=30" -e "NODE_MAX_SESSION=5" -e "NODE_MAX_INSTANCES=5" selenium/node-chrome-debug
docker run -d -p 35009:5900 --link hub:hub --name selenium-node2 -e "NODE_APPLICATION_NAME=test2" -e "NODE_TIMEOUT=30" -e "NODE_MAX_SESSION=5" -e "NODE_MAX_INSTANCES=5" selenium/node-chrome-debug
对node设置30秒
然后NODE_MAX_INSTANCES=5表示设置允许最多有5个实例
instance和session的区别:
参考这个答案:https://stackoverflow.com/questions/13723349/selenium-grid-maxsessions-vs-maxinstances

精简后的意思就是说,
maxsession=5表示限制你的一个node节点下只能最多有5个浏览器实例同时执行,并且不管这5个浏览器是否是相同浏览器(如果有指定版本,相同版本)
maxinstances=5表示限制你的这个node节点下最多有5个相同浏览器(如果有指定版本,相同版本)同时执行
也就是说,我只设置 maxinstances=5时,我可以开5个firefox12版,5个chrome相同版,5个IE,5个Opera,此时已经就有20个浏览器了
而我设置了maxsession=5和maxinstances=5时,我就只能开5个firefox或者5个chrome或者5个opera或者2个firefox+2个chrome+1opera,还有其他的组合,这里就不每个可能都例举出来了,这里不是数学课里的排列组合,懂意思就行了
对于相关的设置,如果遇到问题,可以去这里查看原因:https://github.com/SeleniumHQ/docker-selenium/issues/370
查看管理页面
注意看node和hub的超时时间

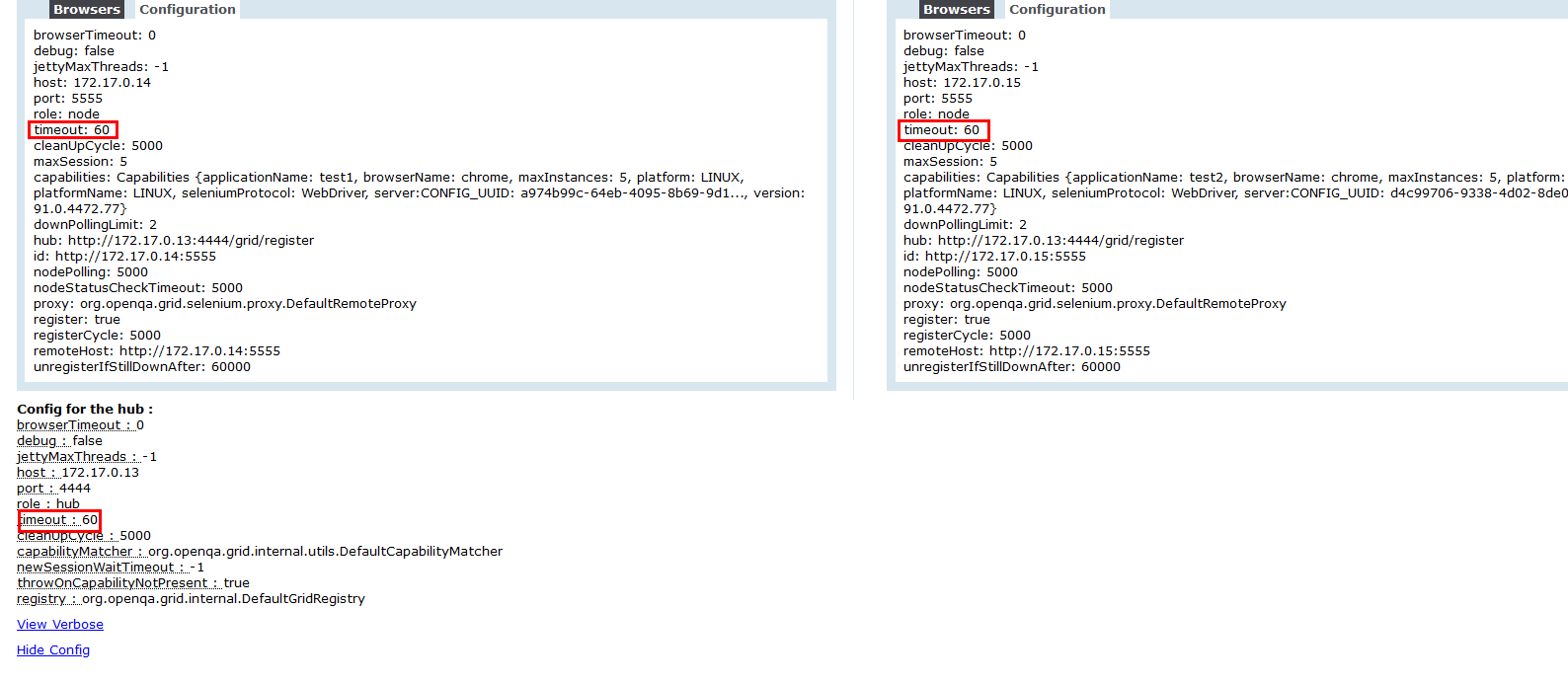
我上面明明设置的hub才是60秒,node就是30秒啊,怎么node也变成了60秒了,这就很骚了,运行脚本测试,也果然在60秒的样子就自动关闭了,查看日志得:started和removing的时间就在60秒左右,为什么一定不是60秒呢,前面也说过了,就不赘述了

感觉有点像是node继承的hub的设置,我再来测试下,我这次把node设置为60秒,hub设置为30秒,如果设置出来的时间显示是hub30秒,node30秒,那基本就是继承的没跑了
为了验证这个是不是真的继承了,配置如下:

管理页面查看,确实如此,那么这个超时时间确实是node继承hub节点的
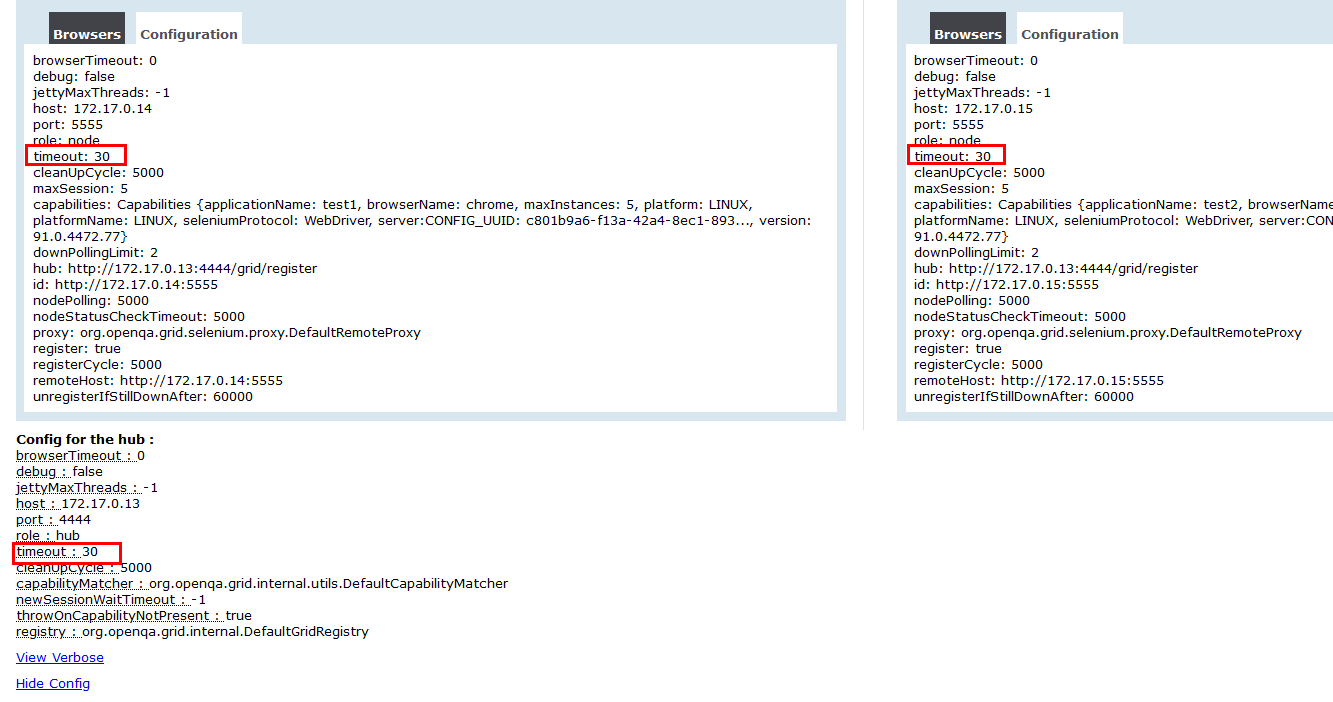
那肯定是继承的啊,官方都是说的是继承的
对了,补充下两点:
1.如果你把timeout设置为0,那它永远都不会因超时而释放了
2.如果你用的selenium grid的版本是3.12的话,这个超时时间timout设置是有问题的,设置的没法生效,而且也无法继承,看开发者回复:
https://github.com/SeleniumHQ/selenium/issues/5908

另外对于时间设置除了timeout还有下面两个设置:
browserTimeout,这个的意思是在hub节点上,可以设置节点在浏览器内挂起的最长时间,因为timeout是节点在清理一个视为过期或者作废的资源,而这个browserTimeout就是一个缓冲,比如我这里设置browserTimeout=20,那么一个会话在20秒之后还没有正常结束且没有再有什么操作,那就会把其置为【过期或者作废的资源】的行列里,这时,timeout到了就会清理掉,也就是说,我设置timeout=60,browserTimeout=20,那么一个异常会话会在60+20=80秒左右才会被关闭清理掉
cleanUpCycle,清理机制轮询超时时间,这里的单位时微妙,默认是5000,即5秒,也就是多久会检查一次超时的机制,也因为又这个,我们上面的设置30秒和60秒时,加上开启浏览器释放浏览器资源也需要点时间,并不会一定是30或者60秒才关闭清理资源
因为,假如我设置的超时tmeout是30秒,没有设置browsertimeout,不考虑浏览器开启和释放资源的造成误差的情况下,轮询是5秒,此时我的程序因为意外终止了,轮询清理机制在2秒以前就执行过了,那么这个浏览器资源会在30秒以后并不会被清理,而会再等3秒以后,被轮询清理机制查到然后清理掉,总共用时30+3,因为这个程序在意外终止时的前2秒轮询清理机制已经执行过了。
其他的参数感兴趣的可以自己研究了
附言:
另外,hub节点也可以设置GRID_MAX_SESSION相关的,这个设置之后会有什么结果,感兴趣自己研究了
相关文档:
https://www.selenium.dev/documentation/en/remote_webdriver/remote_webdriver_client/
https://www.selenium.dev/documentation/en/grid/grid_4/grid_endpoints/
https://seleniumhq.github.io/docs/grid.html
http://www.seleniumhq.org/docs/07_selenium_grid.jsp
https://github.com/SeleniumHQ/selenium/wiki/Grid2
https://github.com/SeleniumHQ/docker-selenium