变色龙原理
变色龙这种动物想必大家都了解,它们会根据周遭环境的局势来改变自己的颜色,伪装自己。
那么爬虫有这种技能吗?当然是有的,先不着急说这个问题。
从上一篇开始,你有没有想过,站在网站管理的角度,如果在同一时间段,大家全部利用爬虫程序对自己的网站进行爬取操作,那么这网站服务器能不能承受这种负荷?肯定不能啊,如果严重超负荷则会时服务器宕机(死机)的,对于一些商业型的网站,宕机一秒钟的损失都是不得了的,这不是一个管理员能承担的,对吧?那管理员会网站服务器做什么来优化呢?我想到的是,写一个脚本,当检测到一个IP访问的速度过快,报文头部并不是浏览器的话,那么就拒绝服务,或者屏蔽IP等,这样就可以减少服务器的负担并让服务器正常进行。
那么既然服务器做好了优化,但你知道这是对爬虫程序的优化,如果你是用浏览器来作为一个用户访问的话,服务器是不会拦截或者屏蔽你的,它也不敢拦你,为什么,你现在是客户,它敢拦客户,不想继续经营了是吧?所以对于如果是一个浏览器用户的话,是可以正常访问的。
所以想到方法了吗?是的,把程序伪造成一个浏览器啊,前面说过服务器会检测报文头部信息,如果是浏览器就不正常通行,如果是程序就拒绝服务。
那么报文是什么?头部信息又是什么?详细的就不解释了,这涉及到http协议和tcp/ip三次握手等等的网络基础知识,感兴趣的自己百度或者谷歌吧。
本篇博文不扯远了,只说相关的重点——怎么查看头部信息。
User-Agent
其实我想有些朋友可能有疑惑,服务器是怎么知道我们使用的是程序或者浏览器呢?它用什么来判断的?这么玄乎?不玄乎,但确实可以,好的,我就用博客园的当前我正在编辑的博文页面为例:
我使用的是火狐浏览器,鼠标右键-查看元素(有的浏览器是审查元素或者检查)
网络(有的是network):
出现报文:

双击它, 右边则会出现详细的信息,选择消息头(有的是headers)

找到请求头(request headers),其中的User-Agent就是我们头部信息:
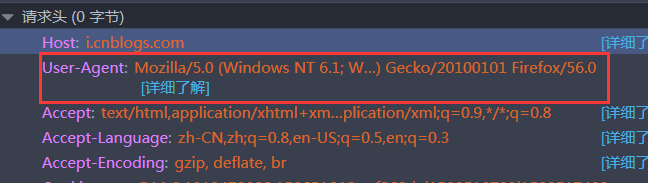
看到是显示的
# -*- coding:utf-8 -*-
import urllib
url='http://www.baidu.com' #百度网址
html=urllib.urlopen(url)#利用模块urllib里的urlopen方法打开网页
print(dir(html)) #查看对象html的方法
print(urllib.urlopen) #查看对象urllib.urlopen的方法
print(urllib.urlopen()) #查看对象urllib.urlopen实例化后的方法
Traceback (most recent call last):
File "D:programmePyCharm 5.0.3helperspycharmutrunner.py", line 121, in <module>
modules = [loadSource(a[0])]
File "D:programmePyCharm 5.0.3helperspycharmutrunner.py", line 41, in loadSource
module = imp.load_source(moduleName, fileName)
File "G:programmePythonpython project est.py", line 8, in <module>
print(urllib.urlopen())
TypeError: urlopen() takes at least 1 argument (0 given)
['__doc__', '__init__', '__iter__', '__module__', '__repr__', 'close', 'code',
'fileno', 'fp', 'getcode', 'geturl', 'headers', 'info', 'next', 'read', 'readline', 'readlines', 'url']
<function urlopen at 0x0297FD30>
urlopen提供了如下方法:
- read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
- info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到
- geturl():返回请求的url
- headers:返回请求头部信息
- code:返回状态码
- url:返回请求的url
好的,详细的自己去研究了,本篇博文的重点终于来了,伪装一个头部信息
伪造头部信息
由于urllib没有伪造头部信息的方法,所以这里得使用一个新的模块,urllib2
# -*- coding:utf-8 -*-
import urllib2
url='http://www.baidu.com'
head={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} #头部信息,必须是一个字典
html=urllib2.Request(url,headers=head)
result=urllib2.urlopen(html)
print result.read()
或者你也可以这样:
# -*- coding:utf-8 -*-
import urllib2
url='http://www.baidu.com'
html=urllib2.Request(url)
html.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0') #此时注意区别格式
result=urllib2.urlopen(html)
print result.read()
结果都一样的,我也就不展示了。
按照上面的方法就可以伪造请求头部信息。
那么你说,我怎么知道伪造成功了?还有不伪造头部信息时,显示的到底是什么呢?介绍一个抓包工具——fidder,用这个工具就可以查看到底报文头部是什么了。这里就不展示了,自己下去常识了。并且我可以确切的保证,确实伪造成功了。
这样,我们就把爬虫代码升级了一下,可以搞定普通的反爬虫限制。