昨天做了从复杂的手写神经网络到backward,今天再使用更为简单的 torch中的nn库,nn就是neural network,在这个里面可以创建一个model来帮助我们保存数据和计算。同样这个nn我们是可以根据我们的网络的结构根据顺序来给与参数,比方说我们的输入层到隐藏层是线性的结构(y=wx+b),而隐藏层中是激活函数ReLU,隐藏层到输出层又是线性的,我们就可以这样定义
model=torch.nn.Sequential(
torch.nn.Linear(D_in,H),
torch.nn.ReLU(),
torch.nn.Linear(H,D_out),
)
其中关于一些代码的注释我也添加了,便于阅读
完整代码如下:
#这次我用使用Pytorch中的nn库来创建神经网络,用Pytorch autograd来构建计算图和gradients然后Pytorch会帮我们自动计算gradients
#nn==neural network,在backward的基础上让网络变的更简单
import torch.nn as nn
import torch
N,D_in,H,D_out=64,1000,100,10
x=torch.randn(N,D_in)
y=torch.randn(N,D_out)
model=torch.nn.Sequential(##模型的组成顺序
#第一层是一个线性结构 这里和前面有点不一样了这里有偏置的
#y=w1*x+b1
torch.nn.Linear(D_in,H),
#第二层是一个ReLU激活函数
torch.nn.ReLU(),
#第三层也是一个线性的结构和第一层一样的
torch.nn.Linear(H,D_out),
)
#这是把w1,w2输入层-->隐藏层-->输出层的权重初始化为normal类型的
#关于normal,官网的解释是 :Returns a Tensor of random numbers drawn from separate normal distributions who’s mean and standard deviation are given.
#大概是返回一个张量,张量里面的随机数是从相互独立的正态分布中随机生成的,这样使得权重会好一点,训练效果也好,过一会我会做实验
torch.nn.init.normal_(model[0].weight)
torch.nn.init.normal_(model[2].weight)
#这里使用了nn里的MSELoss来处理loss损失数值,里面的参数reduction
#reduction = ‘none’,直接返回向量形式的 loss
#reduction = ‘sum’,返回loss之和
#reduction = ''elementwise_mean,返回loss的平均值
#reduction = ''mean,返回loss的平均值
loss_fn=nn.MSELoss(reduction='sum')
learning_rate= 1e-6# 1*10^6
for it in range(500):
y_pred=model(x)
loss=loss_fn(y_pred,y)
print("第",it,"轮","损失值:",loss.item())
loss.backward()
with torch.no_grad():
#解释一下这里面的parameter是指的所有的参数,包括了这个模型里的所有参数,tensor和grad都有
for param in model.parameters():
#这里的parm是每一个参数,这里就是把每一个都参数都在当做grad在计算,我试过如果换成pram.grad LOSS值就不会改变了
param-=learning_rate*param.grad
model.zero_grad()#每次循环结束了要清零,不然会累加
我们将把权重正态分布随机化的语句注释掉,跑一下代码,观察网络训练情况:


我们可以发现这个模型虽然有一定效果但是损失值依旧很大,我在看视频的时候B站视频链接
里面的老师很有经验,起初是没有添加这个权值的normal随机正态分布随机化的模型很糟糕,于是他就把权值正态分布随机初始化了,效果好了很多,所以以后我再实践过程当中遇到这样的麻烦也应该这些试试。
我们添加上这一句:
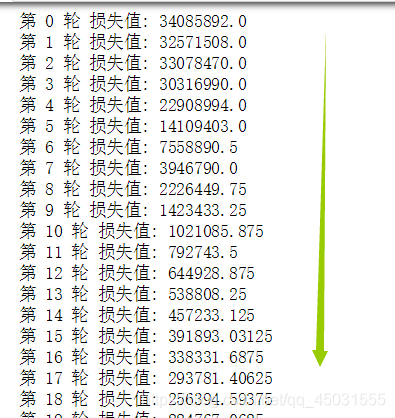
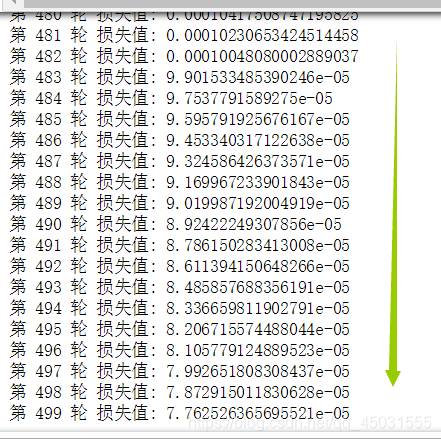
效果得到了显著的提升,很明显这个方法很有效,其实BP网络的目的就是想让权值W朝着向目标值值方向靠拢运动的,一开始的w1不争气,模型也拿它没有办法。
还有就是loss_fn=nn.MSELoss(reduction='sum')函数
这里使用了nn里的MSELoss来处理loss损失数值,里面的参数reduction
reduction = ‘none’,直接返回向量形式的 loss
reduction = ‘sum’,返回loss之和
reduction = ''elementwise_mean,返回loss的平均值
reduction = ''mean,返回loss的平均值
以后也可能会用到,今天还有别的事,就值了解了一下nn搭建神经网络的方法。