Part1.optimize(最优化的,充分利用的)优化模型方法
今天主要学习的就是torch中的model优化方法库——optim
在昨天的nn库的基础上把原来的手动更新模型数据的代码换成封装好的optim
#在使用nn的基础上,我们在学一个torch的方法opitmizer,可以帮助我们做model的优化
#因此在这里我们继续沿用昨天的代码(删除手写的模型更新)来完成 使用optimizer优化模型
import torch.nn as nn
import torch
N,D_in,H,D_out=64,1000,100,10
x=torch.randn(N,D_in)
y=torch.randn(N,D_out)
model=torch.nn.Sequential(##模型的组成顺序
#第一层是一个线性结构 这里和前面有点不一样了这里有偏置的
#y=w1*x+b1
torch.nn.Linear(D_in,H),
#第二层是一个ReLU激活函数
torch.nn.ReLU(),
#第三层也是一个线性的结构和第一层一样的
torch.nn.Linear(H,D_out),
)
#这里使用了nn里的MSELoss来处理loss损失数值,里面的参数reduction
#reduction = ‘none’,直接返回向量形式的 loss
#reduction = ‘sum’,返回loss之和
#reduction = ''elementwise_mean,返回loss的平均值
#reduction = ''mean,返回loss的平均值
loss_fn=nn.MSELoss(reduction='sum')
learning_rate= 1e-4# 1*10^4在torch中学习率一般就选1e-4---1e-5
#使用optimizer来自动更新模型的参数,因此把所有的参数都传进去,加入学习率
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
for it in range(500):
y_pred=model(x)
loss=loss_fn(y_pred,y)
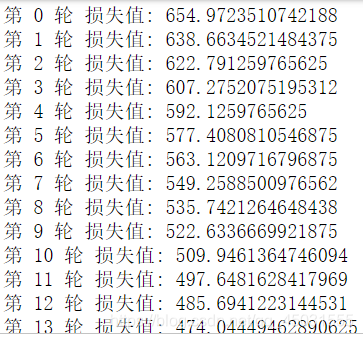
print("第",it,"轮","损失值:",loss.item())
#在每次循环中清零 grad避免累加
optimizer.zero_grad()
loss.backward()
#optimizer的执行step更新指令,更新model的每一个parameter
optimizer.step()
看一下模型的训练情况:

Part2.做一个结构清晰的pytorch的model
1.define input and output
定义好输入和输出的,得到方便进入训练的数据
2.define a torch model
这里的模型就只有两层线性结构,也没有偏置,很简单。一旦网络复杂起来其实也不必担心,我们一个一个的初始化每一层结构
3.define a loss function
用nn.MSELoss()计算loss
4.optimize this model
优化我们的模型,这里用到的是optim.Adam()
5.train this model by updating the parameters
在这个神经网络里面训练模型我就拿一轮举例,
Forwad pass:网络正向传播由x计算得到y_pred预测值
Compute the loss:(target-y_pred)求均方得到loss
Backward pass:是网络反向传播,链式反应发生,输出层-->隐藏层-->输入层的权值(如果有bias偏置的时候偏置也会调整)使得模型中的参数得到训练,模型的loss值不断减少得到优化。
无论一个多大的模型,多长的代码就想小说一样都有明确的结构,以上也大概就是在pytorch上做一个神经网络的最基本的流程,最基本的思路,通过今天的网课学习获得了这个知识,心里算式踏实了。接下来我们写一个如上结构的神经网络
import torch
import torch.nn as nn
N,D_in,H,D_out=64,1000,100,10
#1.define input and output
x=torch.randn(N,D_in)
y=torch.randn(N,D_out)
#2.define a torch model
class TwoLayerNet(torch.nn.Module):
def __init__(self,D_in,H,D_out):
super(TwoLayerNet,self).__init__()#supper是python里调用父类方法
#2.define the model atchitecture,
self.linear1=torch.nn.Linear(D_in,H,bias=False)#这里bias是偏置
self.linear2=torch.nn.Linear(H,D_out,bias=False)
def forward(self,x):
y_pred=self.linear2(self.linear1(x).clamp(min=0))
return y_pred
#2. define a model
model=TwoLayerNet(D_in,H,D_out)
#3.define a loss function
loss_fn=nn.MSELoss(reduction='sum')
learning_rate=1e-4
#4.optimize this model
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
#4.train this model
for it in range(0,500):
#Forward pass
y_pred=model(x)
#compu the loss
loss=loss_fn(y_pred,y)
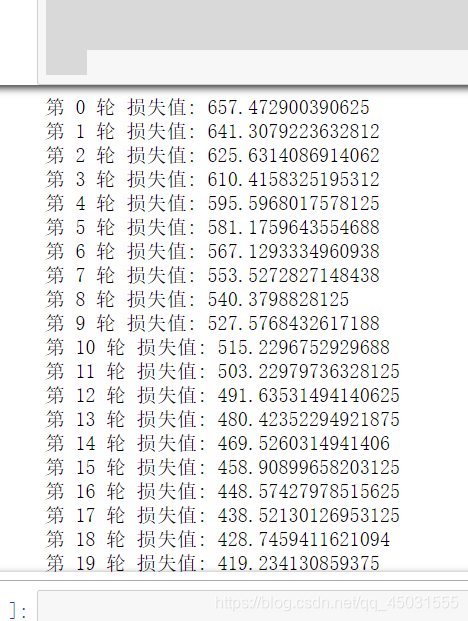
print("第",it,"轮","损失值:",loss.item())
#Baclward pass
optimizer.zero_grad()
loss.backward()
#update the model parameters
optimizer.step()
运行结果:模型训练合格