字符串匹配
BF算法(朴素模式匹配)
时间复杂度O(m*n),普通的模式匹配算法
BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;
若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
模板
输出s2在s1里出现的次数
我写的,两行获取两行字符,第二行的字符串在第一行的字符串匹配,看看有几个
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int maxn = 1e6 + 5;
int main(){
char str[maxn];
gets(str);
char s[maxn];
gets(s);
int len1 = strlen(str);
int len2 = strlen(s);
int cnt = 0;
for(int i = 0; i < len1; i++){
if(str[i] == s[0]){
int flag = 1;
for(int j = 0; j < len2; j++){
if(str[i + j] == s[j]){
}else{
flag = 0;
break;
}
}
if(flag)cnt++;
}
}
printf("%d
",cnt);
return 0;
}
匹配成功,继续,匹配失败回溯
输出第一次匹配的下标
#include <iostream>
#include <string.h>
using namespace std;
int BF(char a[], char b[]){
int index = 0;//第一个字符串的下标
int i = 0;//第一个字符串目前下标
int j = 0;//第二个字符串目前下标
int len1 = strlen(a);
int len2 = strlen(b);
while(i != len1 && j != len2){
if(a[i] == b[j]){
i++;
j++;
}else{
index++;
i = index;
j = 0;
}
}
if(j == len2) return index + 1;//匹配成功
else return 0;
}
int main(){
char a[200];
cout << "请输入主串:";
cin >> a;
char b[200];
cout << "请输入子串:";
cin >> b;
cout << "子串在主串首次匹配的位置是:" << BF(a,b) << endl;
return 0;
}
kmp算法
时间复杂度O(m+n)
对于朴素算法的一个缺点就是每次子串匹配失败就会回溯,所以kmp针对这个问题,使得主串不需要回溯,只对子串进行回溯
而next就解决了这个问题,如果说主串和子串进行匹配,而在主串i与子串j位置失配,那么i前面和j前面那一段必定是匹配的,那么也就是说,可以采用回溯子串使得子串中与其前面具有相同结构部分进行回溯
前缀:指的是字符串的子串中从原串最前面开始的子串,如abcdef的前缀有:a,ab,abc,abcd,abcde
后缀:指的是字符串的子串中在原串结尾处结尾的子串,如abcdef的后缀有:f,ef,def,cdef,bcdef
注意,前缀与后缀均不包含本身
kmp算法最大的特点是加入了next[i]数组
next[i]的含义是对于字符串去掉下标为i的字符后的字符串的前缀与后缀的最长匹配
这是普遍的定义

求解next
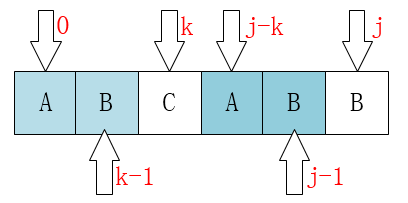
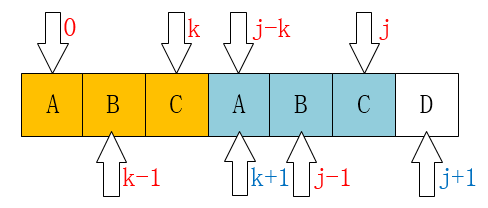

动图next求解

下面是基于清华数据结构教材的定义去求我绝对不是为了考试才这么去解释的也就是字符串下标以0位开头的
比如求ababa的next值
| i | 字符 | 去掉i之后的字符 | 前缀 | 后缀 | next |
|---|---|---|---|---|---|
| 0 | a | null | null | null | -1 |
| 1 | ab | a | null | null | 0 |
| 2 | aba | ab | a | b | 0 |
| 3 | abab | aba | ab | ba | 1 |
| 4 | ababa | abab | aba | bab | 2 |
考研题库里面求出来的值是该方法求出的值加1,因为初始下标的定义不同,next[i]是进行匹配的,所以如果字符串从1开始,那就把next值加1,而字符串从0开始,就按照上面去求即可
void getnext(){
int i = 0,j = -1;
Next[0]=-1;
while(i < len2){
if(j == -1||t[i] == t[j]){
i++;
j++;
Next[i]=j;
}else{
j = Next[j];
}
}
}
主要i和j的起始位置即可,本文都是以下标0开始
优化kmp
当子串重复个数很多的时候,子串的回溯很浪费时间,所以加入了新的优化
比如aaaaaaaa进行匹配时,当最后一个a匹配失败,就会一个一个地向前回溯,很浪费时间,如果最后一个a的next直接指到第一个a就好了
那么在求next时加一个判断
if(T[i] == T[j])next[i] = next[j];
void getnext(){
int i = 0,j = -1;
Next[0]=-1;
while(i < len2){
if(j == -1||t[i] == t[j]){
i++;
j++;
if(t[i]!=t[j])Next[i]=j;
else Next[i] = Next[j];
}else{
j = Next[j];
}
}
}
如何手动求
只要在求得next[]之后,再遍历一下,看t[i]和t[next[i]]是否相同,相同的话就把t[i]的next改了,next[i] = next[next[i]];
kmp
主要在于j的回溯
int kmp(){
int i = 0,j = 0;
while(i < len1 && j < len2){
if(j == -1||s1[i] == s2[j]){
i++;
j++;
}else j = Next[j];
}
return i - len2;
}
模板
传送门
输出匹配的首字母下标和next[]数组
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
char a[1000005];
char b[1000005];
int Next[1000005];
int len1, len2;
void getnext(){
int p = 0;//p是下标
Next[1] = 0;
for(int i = 2; i <= len2; i++){
while(p && b[i] != b[p + 1]){
p = Next[p];
}
if(b[p + 1] == b[i])p++;
Next[i] = p;
}
}
void kmp(){
int p = 0;
for(int i = 1; i <= len1; i++){
while(p && b[p + 1] != a[i])p = Next[p];
if(b[p + 1] == a[i])p++;
if(p == len2){
printf("%d
", i - len2 + 1);
p = Next[p];//改成p=0的话是不重复
}
}
for(int i = 1; i <= len2; i++)
printf("%d ",Next[i]);
}
int main(){
scanf("%s", a + 1);
scanf("%s", b + 1);
len1 = strlen(a + 1);
len2 = strlen(b + 1);
getnext();
kmp();
return 0;
}
另一种写法
#include <cstdio>
#include <iostream>
#include <cstring>
#include <algorithm>
#include <vector>
const int maxn = 1e6+5;
using namespace std;
int Next[maxn];
char s[maxn];
char t[maxn];
int len1, len2;
void kmp(){
int i = 0,j = 0;
while(i < len1){
if(j == -1||s[i] == t[j]){
i++;
j++;
}else{
j = Next[j];
}
if(j == len2){
printf("%d
",i - len2 + 1);
j = Next[j];
}
}
}
void getnext(){
int i = 0,j = -1;
Next[0] = -1;
while(i < len2){
if(j == -1 || t[i] == t[j]){
i++;
j++;
Next[i] = j;
}else{
j = Next[j];
}
}
}
void print(){
for(int i = 1; i <= len2; i++){
printf("%d ", Next[i]);
}
}
int main(){
scanf("%s", s);
scanf("%s", t);
len1 = strlen(s);
len2 = strlen(t);
getnext();
kmp();
print();
return 0;
}
例题
要求匹配不重复,输出匹配的个数
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
char a[1000005];
char b[1000005];
int Next[1000005];
int len1, len2;
int cnt;
void getnext(){
int p = 0;
Next[1] = 0;
for(int i = 2; i <= len2; i++){
while(p && b[i] != b[p+1]){
p = Next[p];
}
if(b[p + 1] == b[i])p++;
Next[i] = p;
}
}
void kmp(){
int p = 0;
for(int i = 1; i <= len1; i++){
while(p && b[p + 1] != a[i])p = Next[p];
if(b[p + 1] == a[i])p++;
if(p == len2){
cnt++;
p = 0;//达到不重复的目的
}
}
}
int main(){
while(1){
cnt = 0;
scanf("%s", a + 1);
if(strcmp(a + 1, "#") == 0)break;
scanf("%s", b + 1);
len1 = strlen(a + 1);
len2 = strlen(b + 1);
getnext();
kmp();
printf("%d
", cnt);
}
return 0;
}
输出匹配的第一个位置
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
int a[1000005];
int b[1000005];
int Next[1000005];
int len1, len2;
int cnt;
int flag = -1;
void getnext(){
int p = 0;
Next[1] = 0;
for(int i = 2; i <= len2; i++){
while(p && b[i] != b[p + 1]){
p = Next[p];
}
if(b[p + 1] == b[i])p++;
Next[i] = p;
}
}
void kmp(){
int p = 0;
for(int i = 1; i <= len1; i++){
while(p && b[p + 1] != a[i])p = Next[p];
if(b[p + 1] == a[i])p++;
if(p == len2){
flag = i - len2 + 1;
p = Next[p];//
return;
}
}
}
int main(){
int t;
cin >> t;
while(t--){
flag = -1;
int n, m;
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++){
scanf("%d", &a[i]);
}
for(int j = 1; j <= m; j++){
scanf("%d", &b[j]);
}
len1 = n;
len2 = m;
getnext();
kmp();
printf("%d
", flag == -1 ? -1 : flag);
}
return 0;
}