机器学习笔记(11)-异常检测-孤立森林
孤立森林(Isolation Forest,iForest)是一种异常检测算法,是西瓜书作者周志华老师的团队研究开发的算法,一般用于结构化数据的异常检测,是一种树模型。思想和决策树、随机森林都极其相似。
iForest对于样本的假设有两点,当样本不符合下面两点时,不建议使用:
- 异常点很少,占样本中的比例很低
- 异常点与正常数据点的差异较大,并且彼此间的分布较为稀疏
根据上述第二点假设,说明该算法模型并不适用于异常点聚集为一小簇的情况。如下图:

该算法同样不考虑时序特征,样本间互相独立。
下面来介绍下该算法的原理和思想:
和随机森林中每颗决策树根据样本属性维度切割类似,iForest也有若干棵iTree(孤立树)组成,每棵iTree由数据样本的维度进行划分,最后将每个样本划分到iTree的左右叶子节点中,所以iTree是一棵二叉树。
iForest算法可以分为两个步骤:
- 建立iTree:根据样本建立若干棵iTree
- 打分:利用建立的iTree对样本进行打分
数据样本:假设有(N)个数据样本点,每个样本的维度是(p)维。
建立iTree:
- 设定树的高度(h)和树的个数(t)棵;
- 从所有(N)个样本数据中随机选取(m)个数据样本,用于建立一棵iTree;
- 随机从(p)维中选取1个维度,该维度的值(q)为随机选择位于(m)个样本在该维度下的值,用于分割(m)个样本点;
- 分割(m)个样本,大于分割值(q)的作为左子树,小于的作为右子树;
- 反复执行3~4两步,直到到达树的限制高度(h)或将样本全部划分到叶子节点中。
打分:
由于划分维度和维度的值都是随机的,所以我们需要反复建立iTree,结果取均值来确保结果稳定。
建立完成(t)棵树后,采用打分函数:
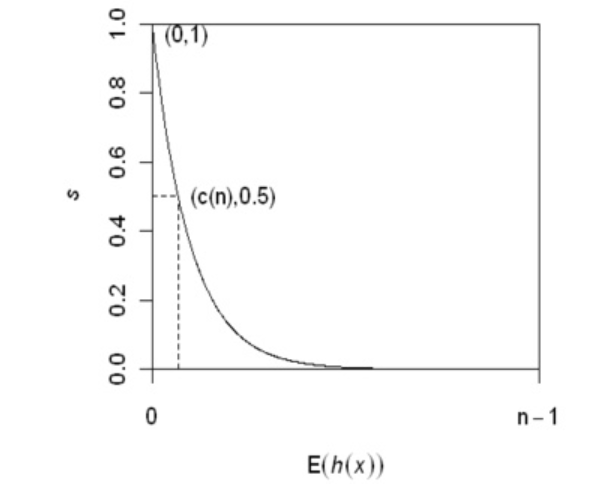
[score(x)=2^{-frac{E[h(x)]}{frac{1}{t}sum_{i=1}^{t}h_{i}}}
]
其中(E[h(x)])表示样本x在所有构建的iTree中的高度的期望值,(frac{1}{t}sum_{i=1}^{t}h_{i})表示每棵iTree的最大高度的均值。
根据上面的打分函数可以很明显看出,越正常的样本在iTree中的深度越大,对应的(h(x))就越接近iTree的高度,score就越接近0.5,而异常点的score越接近1。
总结一下:
- 使用iForest时需要反复构建iForest,使随机性降低,结果收敛。
- 迭代次数越多,iTree构建越多,结果越稳定、准确。