在上篇博文中介绍了网络服务异常检测的大概,本篇将详细介绍SVDD和Isolation Forest这两种算法
1. SVDD算法
SVDD的英文全称是Support Vector Data Description,又称为支持向量数据描述,它是由Tax和Duin提出的一种单分类算法,它起源于V.VapniH的支持向量机。它计算围绕具有一组最小体积的球形决策边界对象,可以用于新奇检测或异常检测,检测从给定数据集中偏离的对象。通过使用不同的内核,SVDD可以获得更灵活和更准确的数据描述,通过区分由训练集表示的对象的类和在对象空间中的所有其他可能的对象,从而找到具有包含所有对象的最小体积(或最小半径)的球体。


对包含N个数据对象的数据集 进行描述,尝试找到这样一个球体:中心为
进行描述,尝试找到这样一个球体:中心为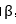 ,半径为R,具有最小半径R并且包含所有(或大多数)的数据对象。
,半径为R,具有最小半径R并且包含所有(或大多数)的数据对象。
对于验证对象z,如果z到超球体球心的距离大于半径R,可视为z为离群点,即异常点:
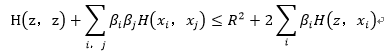
2. Isolation Forest算法
Isolation Forest简称iForest,又称为孤立森林算法,该算法由澳大利亚莫纳什大学Fei Tony Liu教授、Kai Ming Ting教授和南京大学的周志华教授共同提出,也是一种单分类的异常检测算法。
Isolation Forest算法采用构造随机森林的方法估算异常度,时间复杂度降到了O(nlogn)。Isolation Forest是由多棵Isolation Tree组合而成的,每棵Isolation Tree是一种随机二叉树,
Isolation Tree的构造过程如下:
1)选择一个特征。
2)随机选择该特征的一个值。
3)根据特征对每条记录进行分类,把记录中值小于该特征值的记录放在左子树,把大于等于该特征值的记录放在右子树。
4)递归地构造左子树和右子树,直到满足以下条件:
- 传入的数据集只有一条记录或者多条相同的记录。
- 树的高度达到了限定高度。
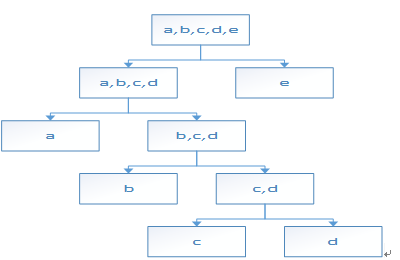
在a,b,c,d,e数据样本中,样本c和样本d的高度为4,样本b的高度是3,样本a的高度是2,可以看到样本e最有可能是异常,因为其最早就被孤立
重构后采用kmeans算法 + random forest算法 这两个算法是spark mllib自带的