简介:图像金字塔是图像中多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。简单来说,图像金字塔就是用来进行图像缩放的。
进行图像缩放可以用图像金字塔,也可以使用resize函数进行缩放,后者效果更好。这里只是对图像金字塔做一些简单了解。
两种类型的金字塔:
①高斯金字塔:用于下采样。高斯金字塔是最基本的图像塔。原理:首先将原图像作为最底层图像G0(高斯金字塔的第0层),利用高斯核(5*5)对其进行卷积,然后对卷积后的图像进行下采样(去除偶数行和列)得到上一层图像G1,将此图像作为输入,重复卷积和下采样操作得到更上一层图像,反复迭代多次,形成一个金字塔形的图像数据结构,即高斯金字塔。
②拉普拉斯金字塔:用于重建图像,也就是预测残差,对图像进行最大程度的还原。比如一幅小图像重建为一幅大图,原理:用高斯金字塔的每一层图像减去其上一层图像上采样并高斯卷积之后的预测图像,得到一系列的差值图像即为 LP 分解图像。
两种类型的采样:
①上采样:就是图片放大(所谓上嘛,就是变大),使用PryUp函数。 上采样步骤:先将图像在每个方向放大为原来的两倍,新增的行和列用0填充,再使用先前同样的内核与放大后的图像卷积,获得新增像素的近似值。
②下采样:就是图片缩小(所谓下嘛,就是变小),使用PryDown函数。下采样将步骤:先对图像进行高斯内核卷积 ,再将所有偶数行和列去除。
总之,上、下采样都存在一个严重的问题,那就是图像变模糊了,因为缩放的过程中发生了信息丢失的问题。要解决这个问题,就得用拉普拉斯金字塔。
参考博客:
https://www.cnblogs.com/skyfsm/p/6876732.html
https://blog.csdn.net/app_12062011/article/details/52471299
代码如下:
import cv2 as cv #高斯金字塔 def pyramid_demo(image): level = 3 #设置金字塔的层数为3 temp = image.copy() #拷贝图像 pyramid_images = [] #建立一个空列表 for i in range(level): dst = cv.pyrDown(temp) #先对图像进行高斯平滑,然后再进行降采样(将图像尺寸行和列方向缩减一半) pyramid_images.append(dst) #在列表末尾添加新的对象 cv.imshow("pyramid"+str(i), dst) temp = dst.copy() return pyramid_images #拉普拉斯金字塔 def lapalian_demo(image): pyramid_images = pyramid_demo(image) #做拉普拉斯金字塔必须用到高斯金字塔的结果 level = len(pyramid_images) for i in range(level-1, -1, -1): if (i-1) < 0: expand = cv.pyrUp(pyramid_images[i], dstsize = image.shape[:2]) lpls = cv.subtract(image, expand) cv.imshow("lapalian_down_"+str(i), lpls) else: expand = cv.pyrUp(pyramid_images[i], dstsize = pyramid_images[i-1].shape[:2]) lpls = cv.subtract(pyramid_images[i-1], expand) cv.imshow("lapalian_down_"+str(i), lpls) src = cv.imread('E:/imageload/zixia.jpg') cv.namedWindow('input_image', cv.WINDOW_AUTOSIZE) #设置为WINDOW_NORMAL可以任意缩放 cv.imshow('input_image', src) lapalian_demo(src) cv.waitKey(0) cv.destroyAllWindows()
运行结果:
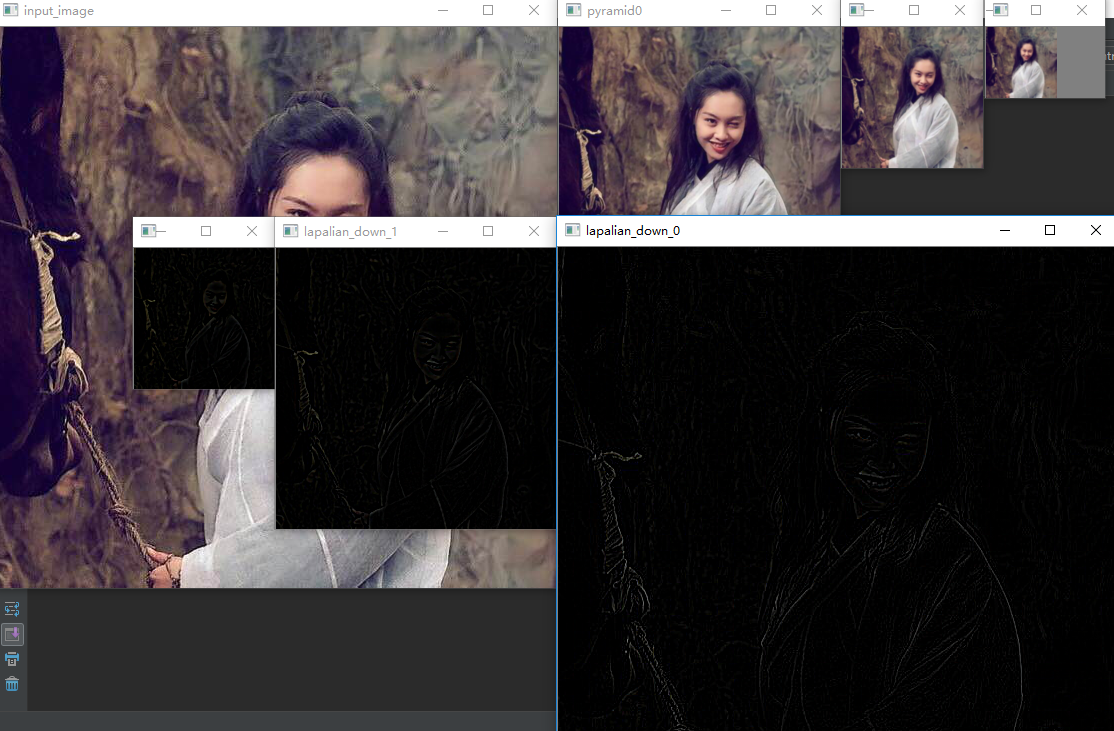
注意:
1.opencv的pyrDown函数先对图像进行高斯平滑,然后再进行降采样(将图像尺寸行和列方向缩减一半)。其函数原型为:pyrDown(src[, dst[, dstsize[, borderType]]]) -> dst
src参数表示输入图像。
dst参数表示输出图像,它与src类型、大小相同。
dstsize参数表示降采样之后的目标图像的大小。它是有默认值的,如果我们调用函数的时候不指定第三个参数,那么这个值是按照 Size((src.cols+1)/2, (src.rows+1)/2) 计算的。而且不管你自己如何指定这个参数,一定必须保证满足以下关系式:|dstsize.width * 2 - src.cols| ≤ 2; |dstsize.height * 2 - src.rows| ≤ 2。也就是说降采样的意思其实是把图像的尺寸缩减一半,行和列同时缩减一半。
borderType参数表示表示图像边界的处理方式。
2.opencv的pyrUp函数先对图像进行升采样(将图像尺寸行和列方向增大一倍),然后再进行高斯平滑。其函数原型为:pyrUp(src[, dst[, dstsize[, borderType]]]) -> dst
src参数表示输入图像。
dst参数表示输出图像,它与src类型、大小相同。
dstsize参数表示降采样之后的目标图像的大小。在默认的情况下,这个尺寸大小是按照 Size(src.cols*2, (src.rows*2) 来计算的。如果你自己要指定大小,那么一定要满足下面的条件:
|dstsize.width - src.cols * 2| ≤ (dstsize.width mod 2); //如果width是偶数,那么必须dstsize.width是src.cols的2倍
|dstsize.height - src.rows * 2| ≤ (dstsize.height mod 2);
borderType参数表示表示图像边界的处理方式。
参考:
https://blog.csdn.net/woainishifu/article/details/62888228
https://blog.csdn.net/poem_qianmo/article/details/26157633
注意:拉普拉斯金字塔时,图像大小必须是2的n次方*2的n次方,不然会报错?(只要图像长和宽相等即可,并不非要是2的n次方*2的n次方,至少我这么做没问题,也不知道为什么都说图像大小必须是2的n次方*2的n次方,求知道的大佬告知一波!)