安装
使用Python进行操作
第一个程序Hello world
下面两个例子都来自于官方示例
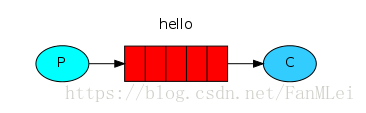
消息传递模型
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()

connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()channel.queue_declare(queue='hello')channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')connection.close()关闭连接
receive.py中前面几句和send中的作用是一样的,这里不再赘述。
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)callback是回调函数,当程序从队列中获取消息后都会执行回调函数来处理消息
channel.basic_consume(callback,
queue='hello',
#no_ack=True
)从队列中获取消息,callback指定回调函数,queue指定获取的队列名,no_ack在以后再说明
channel.start_consuming()让程序进入到一个死循环中,不断从队列中取出消息
消息队列的循环调度
消息传递模型
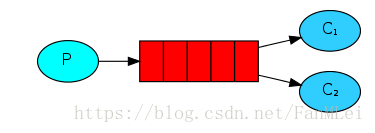
当我们启动多个程序从同一个队列中接收消息的时候,默认是依次接收,即第一个启动的程序首先接收到然后是第二个启动的程序,直到最后一个程序收到之后又从第一个开始,但是这样会造成一个后果就是,可能每个程序或者机器的处理速度不同,造成有的在等待有的消息过多。如下图启动两个接收程序,并发送从0-4数字,两个程序接收的消息依次为:


消息确认
在实际应用中一般程序接收消息后处理需要时间,如果在处理的过程中程序崩溃了那么那个消息就会从消息队列中消失了,这当然不是我们想要的结果,我们需要在程序崩溃之后将那条消息转发到另一个程序中执行,这时候我们需要设置只有在消息被确认后才将消息从队列中删除,RabbitMQ默认消息确认是打开的,但是我们可以添加参数no_ack = True来取消,这样即使消息为处理完成也不会再次发送了,会直接从队列中去除。我们还可以使用手动消息确认即在callback中添加一句:
ch.basic_ack(delivery_tag = method.delivery_tag)消息持久化
上面我们已经说了如何保证消费者崩溃时还保留消息,现在我们将介绍如何在RabbitMQ服务终止后还会保留消息队列。这里需要我们在声明这个队列的时候添加一个参数来实现
channel.queue_declare(queue = 'hello',durable = True)但是这只是保证了hello队列的持久化(下次重启服务的时候队列依然存在),但是队列中消息内容依然是不会被保留下来的,我们想要同时将消息保留下来还需要在channel.basic_publish()函数中添加下面这个参数
properties=pika.BasicProperties(delivery_mode = 2)需要注意的是消息内用只会暂存于缓存中,并未正真写入磁盘中永久保留,还有就是要实现消息持久化的前提是当前队列也是持久化的(不会报错,但是消息并没有被保留下来)
公平派遣
实际应用场景中,有些程序或者是机器处理消息的能力强一些,有些会弱一些,那么按照上面的操作所有的消息都是循环分发的这样就会导致有些机器空闲而有些会出现消息过多处理不过来的情况,为了解决这个问题我们可以在消费者中设置最多可容纳多少条消息,当消息数目满了之后就不会再接收新的消息,直到消息被处理完了留有空余才会再次接收消息。
channel.basic_qos(prefetch_count = 1)需要注意的是prefetch_count参数值并未实际意义,只要为True即可,也就是设置后消费者每次只能接收一个消息与参数值无关。
广播模式

上面所有的都是一对一的消息传递,下面将说一说一对多的传递模型,即广播模式,就好比收音机收听广播一样,需要一个发布者,其他的都是订阅者,发布者发布消息只要订阅者订阅了这个频道那么所有的订阅者都能收到消息。这里的消息传递模型就与之前的略有不同。消息并不是直接发送到队列中,而是经过一个交易所来分发到不同的队列中如上图所示。那么有人会问了,交易所是如何知道要分发到哪一个队列呢,其实只需要将队列和交易所绑定在一起就可以了,每一次消息过来的时候交易所会将消息转发到所有和他绑定的队列中。
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
message = "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)其中exchange_type类型有direct、topic、headers、fanout这四种,下面主要说明fanout类型。上面这段程序指定了一个名为logs的交易所,类型为fanout,下面向这个exchange里面publish一条message消息,routing_key为空表示使用默认操作或称为无名交换。完成了发送程序,下面再来说说接收程序。
channel.exchange_declare(exchange='logs',
exchange_type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)在第四行代码中声明了一个随机名称的队列,exclusive=True将会让程序在消费者断开连接的时候删除这个队列 在第七行代码中我们将生成的随机队列和我们之前的交换所绑定在一起,这样当一个消息过来的时候交易所会将消息分发到我们绑定过的队列中
路由
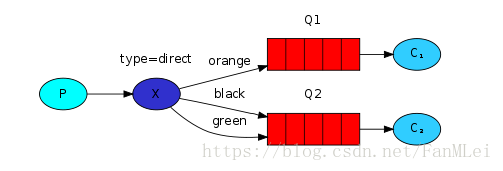
如上图所示