什么是序列?
就是每一个元素被有序的排成一列
什么是序列化?
就是将原本的列表、字典等内容转化成字符串的过程
什么时候会用到序列化?
数据存储(把数据放在文件、数据库),网络传输等
序列化的目的
1.以某种存储形式使自定义对象持久化
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
序列化:数据结构转换成字符串
反序列化:字符串转换成数据结构
三大序列化模块:
1.Json
特点:
json是一个通用的序列化格式且只有很少一部分数据(str、list、dict、tuple、数字)类型能够通过json转化成字符串
json.dumps():
方法使用序列化,将一个数据类型转化成字符串类型
import json dic = {'k1': 2,'k2': 3 } str_d = json.dumps(dic) print(type(str_d),str_d) #<class 'str'> {"k1": 2, "k2": 3}
元祖的序列化:
在json这里元祖会被转成列表再去序列化
import json tu = (1,'a',['y',2]) print(type(tu),tu) #<class 'tuple'> (1, 'a', ['y', 2]) str_t = json.dumps(tu) print(type(str_t),str_t) #<class 'str'> [1, "a", ["y", 2]]
json.loads():
方法使用反序列化,将一个字符串类型还原成原数据类型
import json str_d = '{"k1": 2, "k2": 3}' dict = json.loads(str_d) print(type(dict),dict) #<class 'dict'> {'k1': 2, 'k2': 3}
这里字符串内部的键值要""表示,否则会报错
元祖的反序列化:
结果会转成一个列表,可以用list()方法再转成元祖
json.dump():
接收文件句柄和数据类型,再将该数据类型转换成json字符串写入文件中
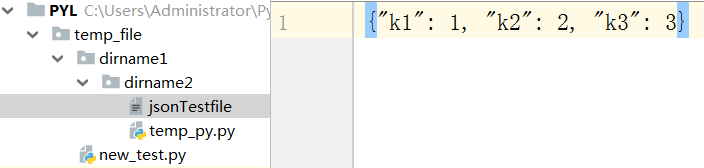
import json dic = {'k1' : 1,'k2' : 2,'k3' : 3} with open('jsonTestfile','w',encoding='utf-8') as f: json.dump(dic,f)
程序执行前:
程序执行后:
json.load():
接收一个文件句柄,将文件中json字符串转成数据结构返回
import json with open('jsonTestfile') as f: get_str = json.load(f) print(get_str) #{'k1': 1, 'k2': 2, 'k3': 3}
如果这个文件有汉字等非ASCII的字符,文件会被写成一个bytes类型
import json dic = {'k1':'中国','k2':'美国','k3':123,'k4':'abc1'} with open('jsonTestFile','w',encoding='utf-8') as f: json.dump(dic,f,ensure_ascii=False) #关闭ensure_ascii这样汉字就不变成乱码了 with open('jsonTestFile',encoding='utf-8') as f: print(json.load(f)) #{'k1': '中国', 'k2': '美国', 'k3': 123, 'k4': 'abc1'}
总结:
在这里从文件写入一个json支持的数据类型或从中取出一个json字符串,这里用到的方法dumpsloads都是从内存中直接取出想要的数据,dumpload则都是从文件中取出想要的数据
前面所归纳到的方法都只能一行一行去获取数据,如果我们要多行获取:
import json l = [{'k1':'a','k2':'b','k3':1}] #将每一个列表中的字典迭代获取并转成json字符串并以分行格式写入文件 with open('jsonTestFile','w') as f: for dic in l: str_dic = json.dumps(dic) f.write(str_dic+' ') #打开这个文件将里面的字符串每行去换行再存入到收集器中,最后再打印结果 with open('jsonTestFile') as f: colletion = [] for line in f: dic = json.loads(line.strip()) colletion.append(dic) print(colletion) #[{'k1': 'a', 'k2': 'b', 'k3': 1}]
2.Pickle
特点:
pickle可以将所有的python中的数据类型转成字符串形式,pickle序列化的内容只有python才能够理解,且部分序列化依赖python代码
pickle.dumps()
将一个数据类型转换成二进制内容,这里dumps()的参数支持python内的所有数据类型
import pickle dic = {'k1': 1,'k2': 2,'k3': 3} set = {1,2,'s'} tu = (1,2,'avb') li = ['k',1,'s',666] pstr_d = pickle.dumps(dic) print(type(pstr_d),pstr_d) #<class 'bytes'> b'x80x03}qx00(Xx02x00x00x00k1qx01Kx01Xx02x00x00x00k2qx02Kx02Xx02x00x00x00k3qx03Kx03u.' pstr_s = pickle.dumps(set) print(type(pstr_s),pstr_s) #<class 'bytes'> b'x80x03cbuiltins set qx00]qx01(Kx01Kx02Xx01x00x00x00sqx02ex85qx03Rqx04.' pstr_t = pickle.dumps(tu) print(type(pstr_t),pstr_t) #<class 'bytes'> b'x80x03Kx01Kx02Xx03x00x00x00avbqx00x87qx01.' pstr_l = pickle.dumps(li) print(type(pstr_l),pstr_l) #<class 'bytes'> b'x80x03]qx00(Xx01x00x00x00kqx01Kx01Xx01x00x00x00sqx02Mx9ax02e.'
pickle.loads()
将读取到的这一个二进制文件转换为数据类型
import pickle pstr_d = b'x80x03}qx00(Xx02x00x00x00k1qx01Kx01Xx02x00x00x00k2qx02Kx02Xx02x00x00x00k3qx03Kx03u.' print(pickle.loads(pstr_d)) #{'k1': 1, 'k2': 2, 'k3': 3} pstr_s = b'x80x03cbuiltins set qx00]qx01(Kx01Kx02Xx01x00x00x00sqx02ex85qx03Rqx04.' print(pickle.loads(pstr_s)) #{1, 2, 's'} pstr_t = b'x80x03Kx01Kx02Xx03x00x00x00avbqx00x87qx01.' print(pickle.loads(pstr_t)) #(1, 2, 'avb') pstr_l = b'x80x03]qx00(Xx01x00x00x00kqx01Kx01Xx01x00x00x00sqx02Mx9ax02e.' print(pickle.loads(pstr_l)) #['k', 1, 's', 666]
pickle.dump()
import pickle,time struct_time = time.gmtime(15000000) print(struct_time) #time.struct_time(tm_year=1970, tm_mon=6, tm_mday=23, tm_hour=14, tm_min=40, tm_sec=0, tm_wday=1, tm_yday=174, tm_isdst=0) with open('pickleTestFile','wb') as f: pickle.dump(struct_time,f)
pickle.load()
import pickle,time struct_time = time.gmtime(15000000) with open('pickleTestFile','rb') as f: print(pickle.load(f))#time.struct_time(tm_year=1970, tm_mon=6, tm_mday=23, tm_hour=14, tm_min=40, tm_sec=0, tm_wday=1, tm_yday=174, tm_isdst=0)
3.Shelve
特点:
shelve可以序列化句柄,可以使用句柄直接操作非常方便
直接创建一个shelve对象
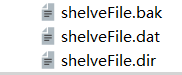
import shelve f = shelve.open('shelveFile') f['key'] = {'int': 10,'float': 15.6,'string' :'abc123'} f.close()
固定生成三个shelve专属的文件
取出存入DB中的数据
import shelve f = shelve.open('shelveFile') getData = f['key'] f.close() print(getData) #{'int': 10, 'float': 15.6, 'string': 'abc123'}
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改参数,否则对象的修改不会保存
关于shelve的学习链接:https://www.cnblogs.com/sui776265233/p/9225164.html#_label2