预训练网络
如果这个数据集足够大且足够通用,那么预训练网络学到的特征的空间层次结构可以作为有效的提取视觉世界特征模型。
神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。
即使新问题和新数据与原始网络不同,学习到的特征在不同问题之间是可以移植的,这也是深度学习与浅层学习方法的一个重要优势,它使得深度学习对于小数据问题非常有效。
Keras内置预训练网络
Keras库包含(在tensorflow中也就是tf.keras模块)、VGG16、VGG19、ResNet50、InceptionV3、Xception等网络架构
ImageNet
ImageNet是一个手动标注好类别的图片数据库,为了机器视觉研究已经有了22000各类别。当我们在深度学习和卷积神经网络背景下,听到'ImageNet'一词,我们可能会提到ImageNet视觉识别比赛,称为ILSVRC,这个图片分类比赛是训练一个模型,能够将输入图片正确分类到1000各类别中的某个类别,训练集120w,验证集5w,测试集10w。这里的1000个图片的类别是我们日常生活中遇到的猫、狗、生活用品等。
VGG16和VGG19
VGG模型架构在2014年被提出,"极深的大规模图像识别卷积网络"-Very Deep Convolution Networks For Large Scale Image Recognition论文中有介绍。
VGG模型结构简单有效,前几层仅使用3*3卷积核来增加网络深度,通过max pooling依次减少每层的神经元数量,最后三层分别是有两个4096个神经元的全连接层和softmax层。
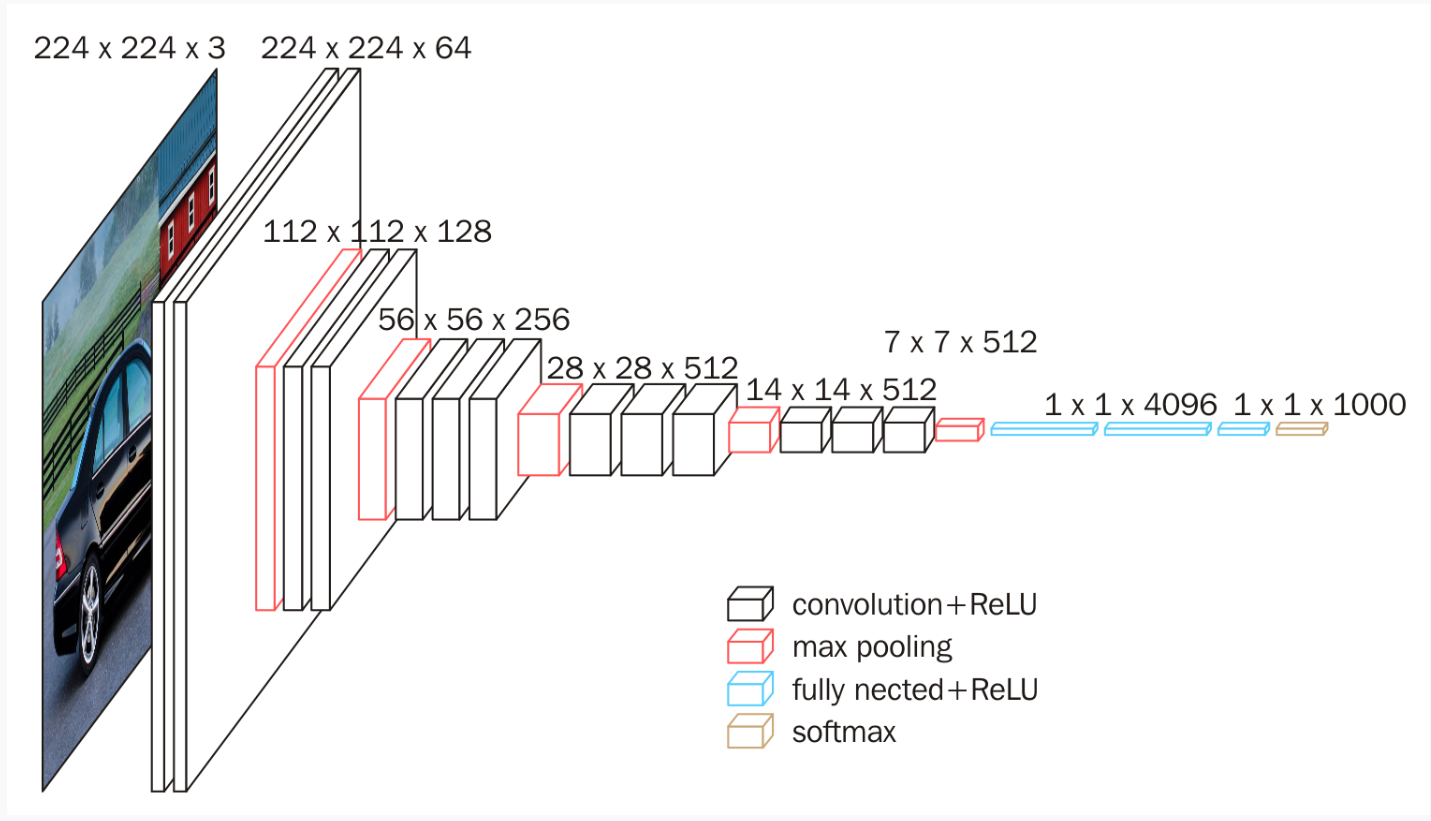
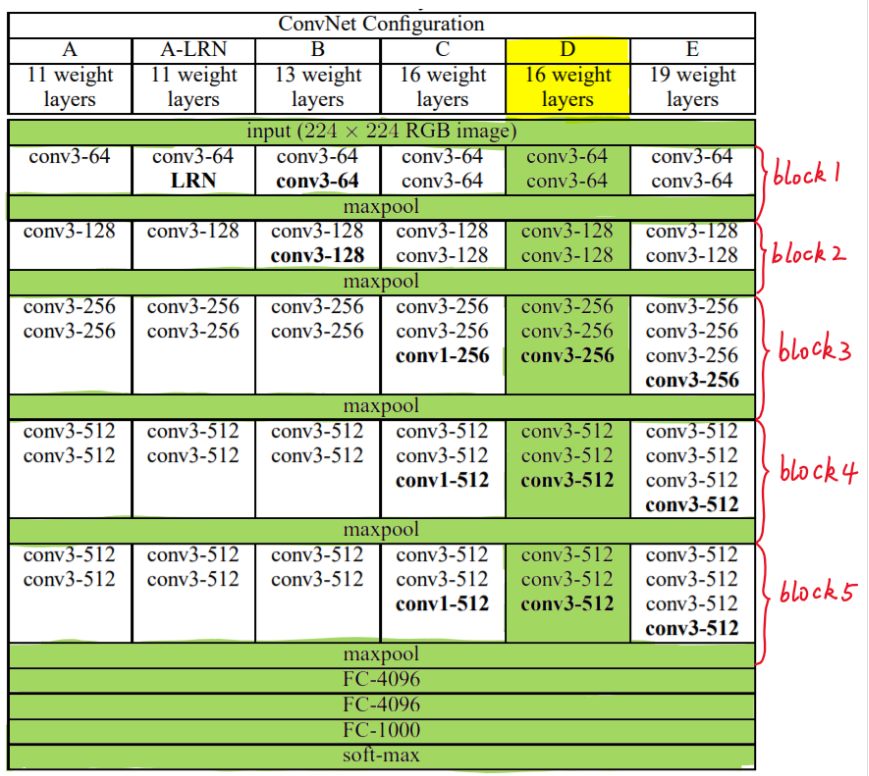
16weight layers就是代表VGG16。
conv3-68指的是卷积核为3*3,filter是68。
FC-4096代表的是全连接层,里面有4096个神经元。
缺点:
1.网络架构中weight数量非常的大,很消耗磁盘空间
2.训练非常慢
由于它的全连接层的数量较多,再加上网络比较深,VGG16有533M+,VGG19有574MB,这使得VGG网络部署十分耗时。
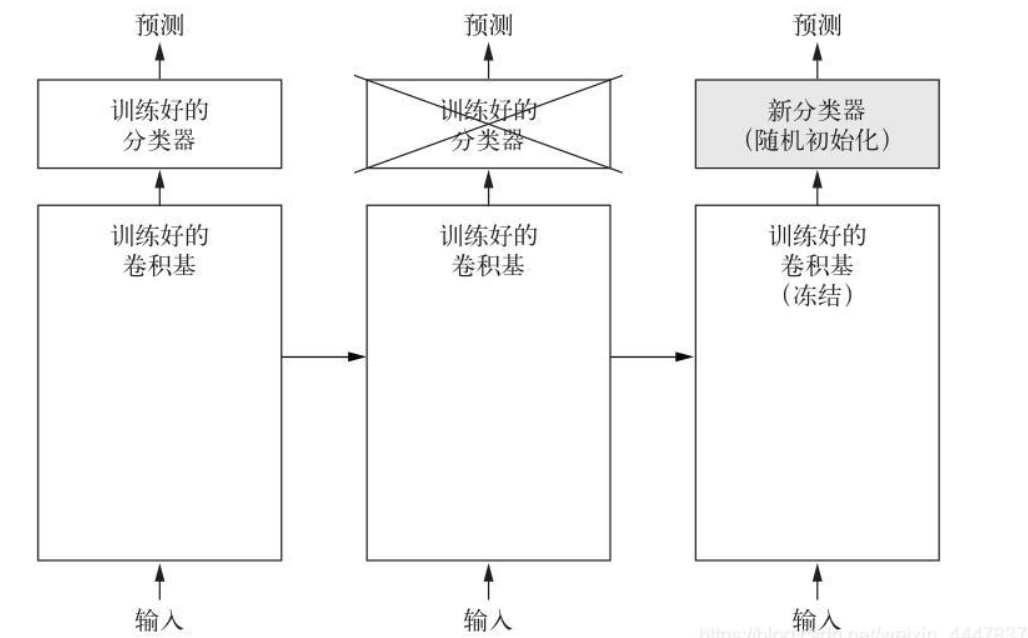
预训练网络的实现
特征提取是使用之前网络学到的表示来从新样本中提取出有趣的特征,然后将这个输入一个新的分类器,从头训练。图像分类的卷积神经网络包含两个部分:
1.一系列池化层和卷积层:模型的卷积基(convolution base)
2.一个密集链接分类器
对于卷积神经网络而言,特征提取就是取出之前训练好的网络的卷积基,在上面运行新的数据,然后在输出上面训练一个新的分类器
1)某个卷积层提取的表示的通用性(以及可复用性)取决于该层在模型中的深度
2)新数据集与原始模型训练的数据集有很大差异,那么最好只使用模型的前几层来做特征提取,而不是使用整个卷积基
3)模型中更靠近底部的层提取的是局部的、高度通用的特征图(比如视觉边缘、颜色和纹理),而更靠近顶部的层提取的是更加抽象的概念(比如“猫耳朵”或“狗眼睛”)
微调
即冻结模型库底部的卷积层,共同训练新添加的分类器和顶部部分卷积层,这允许我们微调基础模型中高阶特征表示,让它们与特定任务相关。
只有在分类器已经训练好了,才能微调卷积基的顶部卷积层,如果没有这样的话,刚开始的训练误差会很大,微调之前学到的会被破坏掉。
微调步骤:
1.在预训练卷积基上添加自定义层
2.冻结卷积基所有层
3.训练添加的分类层
4.解冻卷积基的一部分层
5.联合训练解冻的卷积层和添加的自定义层