参考博客:
shyleoking
前言
首先我们知道值类型存储在栈(Stack)中,而引用类型存储在堆(Heap)中,栈的工作方式是先进后出,会保证先分配内存的变量后释放。
这样就保证了栈中先进后出的规则不与变量的生命周期起冲突。
值类型的生命周期
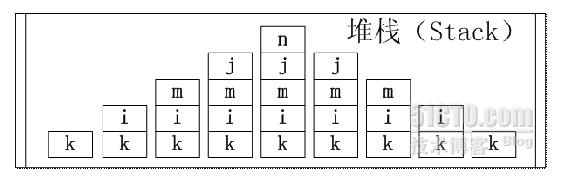
在C#中,对变量的声明要求是先定义后使用,变量的生命周期是从其定义开始直到程序的控制离开该变量所在的大括号{ }
static void Main(string[] args)
{
int k = 10;//k的生命周期开始了
for (int i = 0; i <= 10 - 1; i++)//i的生命周期开始了
{
int m = k + i;//m的生命周期开始了
for (int j = i; j <= 10 - 1; j++)//j的生命周期开始了
{
int n = j * i;//n的生命周期开始了
//n的生命周期结束了
}//j的生命周期结束了
//m的生命周期结束了
}//i的生命周期结束了
//k的生命周期结束了
}
下面的图描述了这些变量的生命周期和堆栈的存储
把值类型设置为null的情况
上述的代码改为如下形式:
static void Main(string[] args)
{
int k = 10;//k的生命周期开始了
for (int i = 0; i <= 10 - 1; i++)//i的生命周期开始了
{
int m = k + i;//m的生命周期开始了
k = null; //k的生命周期结束了???
//m的生命周期结束了
}//i的生命周期结束了
//k的生命周期结束了
}
现在我们看下代码到第8行时的栈:
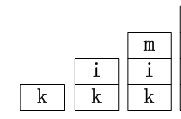
这个时候k在栈底,如果我们想释放k,就要先释放m和i。
所以这样操作就破坏了栈的先进后出的规则,所以会出错,编辑就会报错。
引用类型为什么可以设置为null
上述的代码改为如下形式:
static void Main(string[] args)
{
List<int> k = new List<int>();//k的生命周期开始了
for (int i = 0; i <= 10 - 1; i++)//i的生命周期开始了
{
k.Add(i);
int m = k.Count;//m的生命周期开始了
for (int j = i; j <= 10 - 1; j++)//j的生命周期开始了
{
int n = j * i;//n的生命周期开始了
//n的生命周期结束了
}//j的生命周期结束了
//m的生命周期结束了
}//i的生命周期结束了
//k的生命周期结束了
}
栈中的处理大致如图:
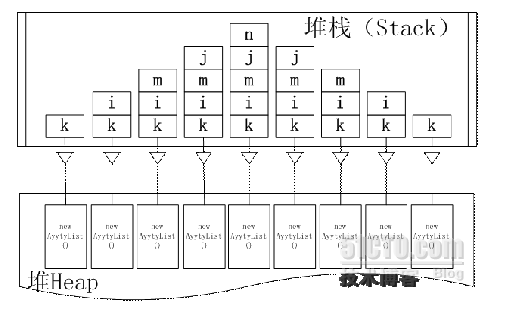
此时变量k还是分配在栈中,但实际存放List实例的区域是在堆中。对List的实例使用,是通过在栈中的变量k来间接的指向的。所以就把对象引用null和生命周期两个概念可以分离出来。
所以就算我们把k = null,也只是让变量k不再指向堆中的有效地址了,但其生命周期并没有发生变化。
现在我们明白了,因为值类型变量直接在栈中保存了数据,因此在生命周期结束前数据不能被任何形式的销毁,而引用类型变量在堆中保存数据,所以赋值null其实是将对应在堆中的数据销毁而不是结束变量的生命周期。