word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具.
gensim包提供了word2vec的python接口.
word2vec采用了CBOW(Continuous Bag-Of-Words,连续词袋模型)和Skip-Gram两种模型.
模型原理
为了便于进行定量的分析,我们通常使用向量来代表我们研究的对象(如单词)。常用的向量化形式有两种:
-
one-hot编码:一个词用一个长度为词典长度的向量表示。词向量中仅一个元素为1其它均为0。
这种方式的缺点在于向量无法反映对象之间的关系,且维度较多计算量较大。 -
分布编码: 该编码将词语映射为固定长度的向量, 即N维向量空间中的一点。
理想状况下,两个对象越相似,它们词向量的相似度也越高,空间中两点的距离越近。
Word2Vec模型即是一种典型的分布编码方式。
统计语言模型
N-gram模型
N-Gram模型是一种统计语言模型。简单来讲,统计语言模型是计算语料库中某个句子出现概率的模型。
假设句子W是由T个单词 $ w_1, w_2, w_3 … w_T $按照顺序构成的,那么句子W出现的概率可以认为是T个单词依次出现的联合概率:
其中,(w_i^j)表示单词 (w_i, w_{i+1}, w_{i+2}, … w_j) 组成的序列, (p(w_2|w_1))表示在出现(w_1)的条件下,下一个单词为(w_2)的条件概率。
那么, (p(w_T|w_1^T))表示在出现序列(w_1^T)的条件下,下一个单词为(w_T)的条件概率。
根据贝叶斯定理, 可以得到:
在句子较长的情况下,根据上面两式计算P(W)计算量十分巨大。
根据经验可知,一个词出现的概率并非与前面所有词都相关,距离越远相关性越低。
因此,可以假设一个词出现的概率只与前面N-1个词有关。那么,这个问题变为了N-1阶马尔科夫模型。
对于语句(W(w_1, w_2, w_3 … w_T)),已知(w_1, w_2, w_3 … w_{T-1}),语句W出现的概率仅与(w_T)有关。
统计语言模型可以表示为在已知语句出现的概率的情况下,推算某个单词w出现在语句的k位置的概率。
神经概率语言模型
神经概率语言模型沿用了N-Gram模型的核心观点:语句出现的概率是语句中各单词依次出现的联合概率。
神经概率语言模型使用向量表示词语,在已知语句W出现概率的情况下,预测最可能出现在k位置的单词(w_k)。
神经概率语言模型是一个三层的神经网络模型。训练样本为单词w上下文的词向量,经过隐含层传递到输出层,输出层为单词w的词向量。
如图所示:
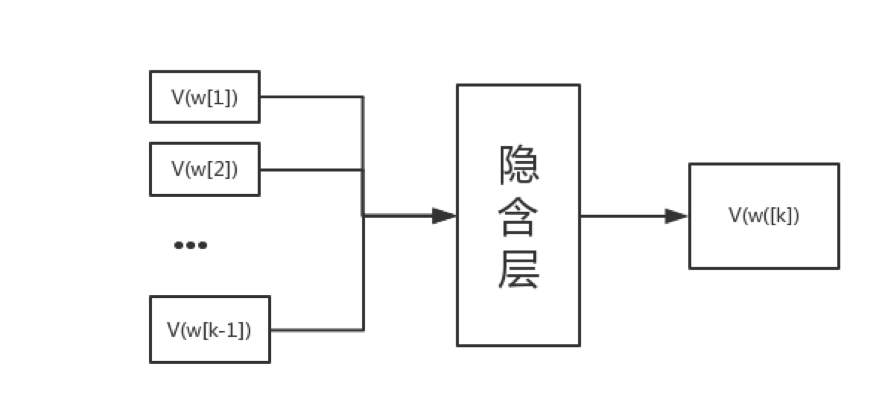
我们可以随机初始化词典中所有单词的词向量,然后将语料库中所有语句输入网络得到预测的词向量,然后与库中的词向量对比修正单词w的词向量或者其上下文的词向量。
经过充分迭代,最终得到可以较好地表示语义的词向量。
Word2Vec
Word2Vec模型是Google公司在2013年开源的一种将词语转化为向量表示的模型。Word2Vec是由神经概率语言模型演进而来,它对神经概率语言模型做了重要改进,提高了计算效率。
Word2Vec模型有两种主要的实现方式:连续词袋 模型(Continuous Bag-of-Word Model, CBOW Model) 和 skip-gram_模型。
CBOW
连续词袋模型(Continuous Bag-of-Word Model, CBOW)是一个三层神经网络, 输入已知上下文输出对下个单词的预测.
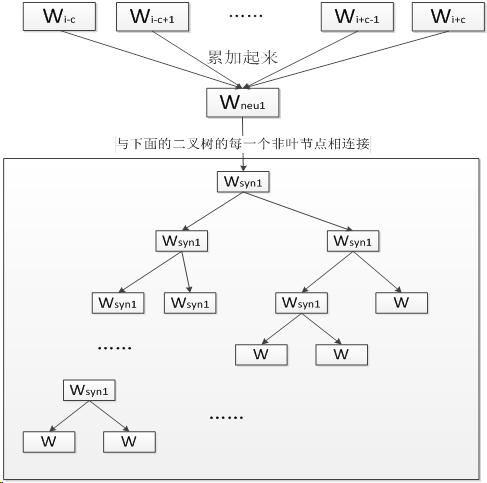
CBOW模型的第一层是输入层, 输入已知上下文的词向量. 中间一层称为线性隐含层, 它将所有输入的词向量累加.
第三层是一棵哈夫曼树, 树的的叶节点与语料库中的单词一一对应, 而树的每个非叶节点是一个二分类器(一般是softmax感知机等), 树的每个非叶节点都直接与隐含层相连.
将上下文的词向量输入CBOW模型, 由隐含层累加得到中间向量.将中间向量输入哈夫曼树的根节点, 根节点会将其分到左子树或右子树.
每个非叶节点都会对中间向量进行分类, 直到达到某个叶节点.该叶节点对应的单词就是对下个单词的预测.
首先根据预料库建立词汇表, 词汇表中所有单词拥有一个随机的词向量.我们从语料库选择一段文本进行训练.
将单词W的上下文的词向量输入CBOW, 由隐含层累加, 在第三层的哈夫曼树中沿着某个特定的路径到达某个叶节点, 从给出对单词W的预测.
训练过程中我们已经知道了单词W, 根据W的哈夫曼编码我们可以确定从根节点到叶节点的正确路径, 也确定了路径上所有分类器应该作出的预测.
我们采用梯度下降法调整输入的词向量, 使得实际路径向正确路径靠拢.在训练结束后我们可以从词汇表中得到每个单词对应的词向量.
Skip-gram
Skip-gram模型同样是一个三层神经网络. skip-gram模型的结构与CBOW模型正好相反,skip-gram模型输入某个单词输出对它上下文词向量的预测。
输入一个单词, 输出对上下文的预测.
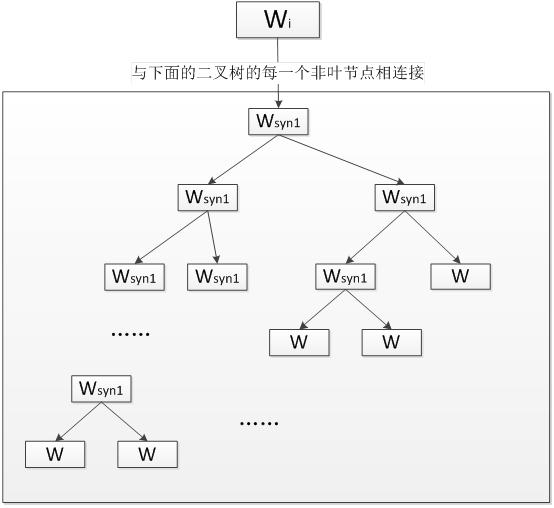
Skip-gram的核心同样是一个哈夫曼树, 每一个单词从树根开始到达叶节点可以预测出它上下文中的一个单词.
对每个单词进行N-1次迭代, 得到对它上下文中所有单词的预测, 根据训练数据调整词向量得到足够精确的结果.
模型实现
继承python内置的collections.Counter编写词频统计器WordCounter
实现哈夫曼树HuffmanTree,关于构造哈夫曼树的算法参考这里.
定义模型类:
class Word2Vec:
def __init__(self, vec_len=15000, learn_rate=0.025, win_len=5):
self.cutted_text_list = None
self.vec_len = vec_len
self.learn_rate = learn_rate
self.win_len = win_len
self.word_dict = None
self.huffman = None
词汇表word_dict是一个字典:
word_dict = {word: {word, freq, possibility, init_vector, huffman_code}, ...}
build_word_dict方法根据WordCounter建立词汇表:
def build_word_dict(self, word_freq):
# word_dict = {word: {word, freq, possibility, init_vector, huffman_code}, }
word_dict = {}
freq_list = [x[1] for x in word_freq]
sum_count = sum(freq_list)
for item in word_freq:
temp_dict = dict(
word=item[0],
freq=item[1],
possibility=item[1] / sum_count,
vector=np.random.random([1, self.vec_len]),
Huffman=None
)
word_dict[item[0]] = temp_dict
self.word_dict = word_dict
train方法控制训练流程, 将单词及其上下文交给CBOW方法或SkipGram方法进行具体训练:
def train(self, word_list, model='cbow', limit=100, ignore=0):
# build word_dict and huffman tree
if self.huffman is None:
if self.word_dict is None:
counter = WordCounter(word_list)
self.build_word_dict(counter.count_res.larger_than(ignore))
self.cutted_text_list = counter.word_list
self.huffman = HuffmanTree(self.word_dict, vec_len=self.vec_len)
# get method
if model == 'cbow':
method = self.CBOW
else:
method = self.SkipGram
# train word vector
before = (self.win_len - 1) >> 1
after = self.win_len - 1 - before
total = len(self.cutted_text_list)
count = 0
for epoch in range(limit):
for line in self.cutted_text_list:
line_len = len(line)
for i in range(line_len):
word = line[i]
if is_stop_word(word):
continue
context = line[max(0, i - before):i] + line[i + 1:min(line_len, i + after + 1)]
method(word, context)
count += 1
CBOW方法对输入变量累加求和, 交由along_huffman方法进行一次预测并得到误差, 最后根据误差更新词向量:
def CBOW(self, word, context):
if not word in self.word_dict:
return
# get sum of all context words' vector
word_code = self.word_dict[word]['code']
gram_vector_sum = np.zeros([1, self.vec_len])
for i in range(len(context))[::-1]:
context_gram = context[i] # a word from context
if context_gram in self.word_dict:
gram_vector_sum += self.word_dict[context_gram]['vector']
else:
context.pop(i)
if len(context) == 0:
return
# update huffman
error = self.along_huffman(word_code, gram_vector_sum, self.huffman.root)
# modify word vector
for context_gram in context:
self.word_dict[context_gram]['vector'] += error
self.word_dict[context_gram]['vector'] = preprocessing.normalize(self.word_dict[context_gram]['vector'])
SkipGram方法使用Skip-gram模型进行训练, 它进行多次迭代:
def SkipGram(self, word, context):
if not word in self.word_dict:
return
word_vector = self.word_dict[word]['vector']
for i in range(len(context))[::-1]:
if not context[i] in self.word_dict:
context.pop(i)
if len(context) == 0:
return
for u in context:
u_huffman = self.word_dict[u]['code']
error = self.along_huffman(u_huffman, word_vector, self.huffman.root)
self.word_dict[word]['vector'] += error
self.word_dict[word]['vector'] = preprocessing.normalize(self.word_dict[word]['vector'])
along_huffman方法进行一次预测并得到误差:
def along_huffman(self, word_code, input_vector, root):
node = root
error = np.zeros([1, self.vec_len])
for level in range(len(word_code)):
branch = word_code[level]
p = sigmoid(input_vector.dot(node.value.T))
grad = self.learn_rate * (1 - int(branch) - p)
error += grad * node.value
node.value += grad * input_vector
node.value = preprocessing.normalize(node.value)
if branch == '0':
node = node.right
else:
node = node.left
return error
从词汇表中取出词向量:
def __getitem__(self, word):
if not word in self.word_dict:
return None
return self.word_dict[word]['vector']
> wv = Word2Vec(vec_len=50)
> wv.train(data, model='cbow')
> wv['into']
array(1, 50)
完整源代码参见Word2Vec
gensim中的word2vec封装
gensim是著名的向量空间模型包, 使用pip安装:
pip gensim
gensim中封装了包括了word2vec, doc2vec等模型:
from gensim.models.word2vec import Word2Vec
profiler = Word2Vec()
首先根据语料库构建词汇表:
profiler.build_vocab(word_source)
数据源word_source是一个句子组成的序列:
word_source = [
['I', 'love', 'natural', 'language', 'processing'],
['word2vec', 'is', 'a', 'useful', 'model']
]
因为内存有限, 使用list作为数据源通常只能保存很少数据. word2vec也可以使用generator作为数据源.
word2vec需要再次扫描数据集进行训练:
self.profiler.train(word_source)
word2vec支持在线训练(resume training, 又称继续训练),即进行过训练的模型可以再次训练, 进一步提高精度.
从训练好的模型中获得词向量:
>>>profiler[word]
array([-0.00449447, -0.00310097, 0.02421786, ...], dtype=float32)
word2vec可以计算单词相似度:
>>>profiler.similarity('woman', 'man')
0.73723527
将训练好的模型存储为文件:
profiler.save(filename)
读取模型文件:
profiler = Word2Vec.load(filename)