查成绩,算分数,每年的综合测评都是个固定的过程,作为软件开发者,这些过程当然可以交给代码去做,通过脚本进行网络请求获取数据,然后直接进行计算得到基础分直接填表就好了,查成绩再手动计算既容易出错也繁琐,所以本篇的内容就是开发一个爬虫脚本取抓取成绩表,至于综合测评计算,这个没什么意义这里就不说了,分数都有了就都够了。
我们的目的就是通过编写脚本,模仿浏览器进行请求获取源码,再进行解析本地化(或者直接计算)
要抓取到数据,其实方案不止一种,这里会介绍两种不同的方案,达到同样的目的:
- 模仿浏览器进行请求(速度快)
- 操作浏览器进行请求(速度慢)
先说第一种,这种方案是普遍的爬虫技术,因为爬取的内容不多,对速度要求也不够,所以就是很简单的一个爬虫过程:
- 分析请求
- 模仿请求
对于普通的校园网,一般不做流量限制,所以就算请求频繁,也基本不用担心IP被封禁,所以编写爬虫代码可以不用太过担心。先说我所在学校的校园网,是杭州方正软件公司开发的。
① 分析请求
分析请求很简单,就是使用浏览器进行请求,然后分析每个请求所发送和接收的信息,这里最简单应该是使用chrome的开发者模式(F12打开)

输入用户名和密码,勾选已认真阅读,接着点击登陆,这样右边的网络窗口中会检查到所有的网络请求,我们只需要找到对应登陆的一个(这里会带有表单):

这个时候,我们可以通过一些测试工具,尝试进行请求对应的这个地址,并且把表单提交上去试试登陆能否成功,如果成功的话,脚本也就可以模拟这个请求,这里用的是chrome商店的一个工具Postman,用法很简单:

登陆成功之后,我们再进行查询成绩:

这里可以看到这次得到了两个新的请求(上图红框的前两个)
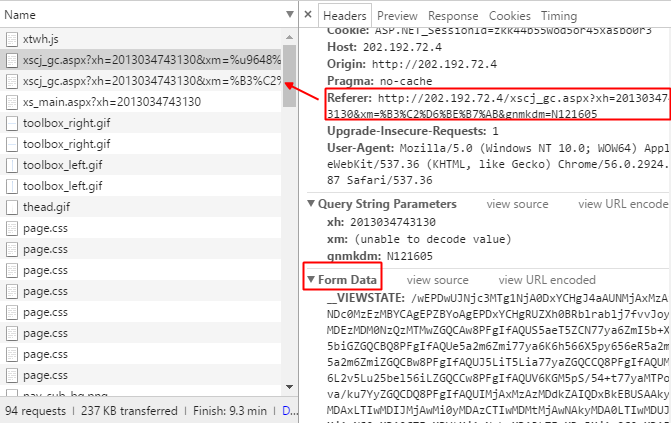
仔细观察会发现,第一个请求头中的Referer指向的是第二个请求的地址,所以可以知道,第二个请求是先于第一个请求发送的。其次,我们发现这个请求中也有表单。
再看第二个请求:

它的Referer指向第三个请求,而这个第三个请求实际上登陆成功之后,就已经存在了,它就是请求到主界面的,而这个请求的类型是Get,所以也表明,第三个请求没有传递任何信息给这个请求。
整理可以知道,流程是这样的:
登陆成功后跳转:http://202.192.72.4/xs_main.aspx?xh=2013034743130
点击查询成绩按钮请求:http://202.192.72.4/xscj_gc.aspx?xh=2013034743130&xm=%B3%C2%D6%BE%B7%AB&gnmkdm=N121605 (Get)
点击查询在校成绩请求:http://202.192.72.4/xscj_gc.aspx?xh=2013034743130&xm=%u9648%u5fd7%u5e06&gnmkdm=N121605 (Post)
所以,我们先来模拟第二个,这个请求是Get类型,所以直接请求即可,但是会发现请求会失败,原因是服务器不能知道我们已经进行登陆了:

所以最先想到的办法是带上第一个请求得到的Cookie,但是也是不行,这个时候要用到上面说的Referer标识,这个标识会告诉服务器请求来源,因为登陆成功会在服务器进行登记,这个标记会让服务器知道请求来源于登陆成功的账号:

此时请求返回正常,我们在源码中可以发现有两个隐藏的<input>标签:


这两个标签传递的,其实是第三个请求的参数,这个时候,模拟第三个请求,并且添加对应的Referer(第二个请求的URL),会发现请求也成功了:
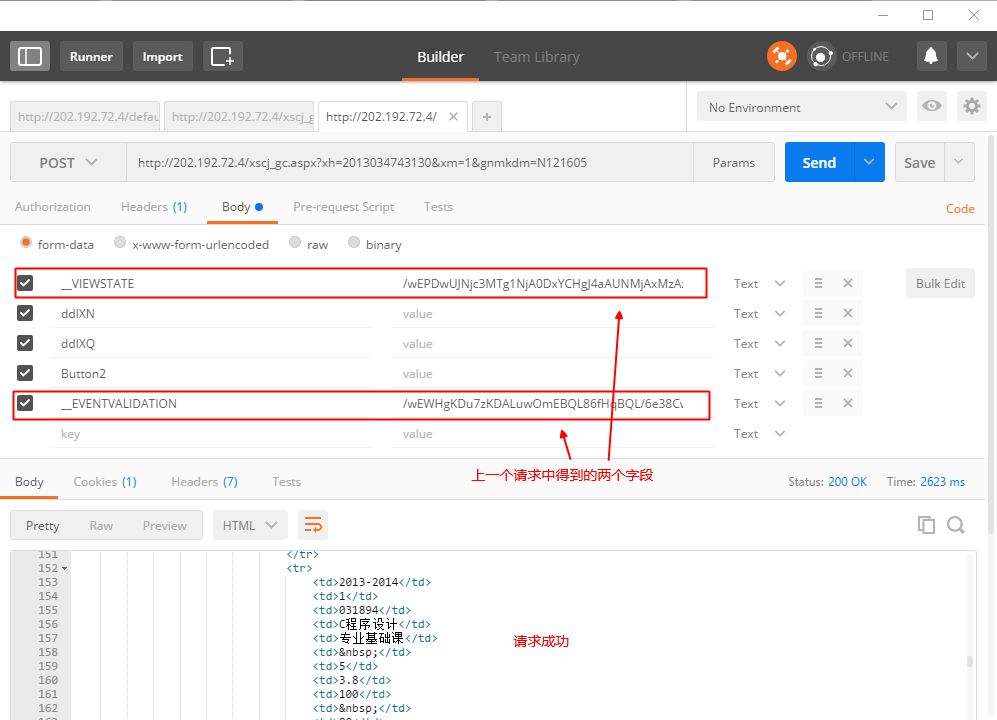
这个请求中的url中的一个参数xm被我更改为1了,原本使用的是一种unicode加密编码,把用户名编码过去了,但是实际上这个参数并没有实际意义,%u的格式会破坏Python程序,所以这里直接改成1了。
② 模仿请求
请求分析完毕,就可以开始写代码了:
用到的包:
1 import requests, xlwt, os 2 from bs4 import BeautifulSoup
登录:
1 def login(s, number, password): 2 print '正在登录账号:'+number 3 url = 'http://202.192.72.4/default_gdsf.aspx' 4 data = {'__EVENTTARGET': 'btnDL', 5 'TextBox1': number, 6 'TextBox2': password, 7 '__VIEWSTATE': '/wEPDwULLTExNzc4NDAyMTBkGAEFHl9fQ29udHJvbHNSZXF1aXJlUG9zdEJhY2tLZXlfXxYBBQVjaGtZRIgvS19wi/UKxQv2qDEuCtWOjJdl', 8 'chkYD': 'on', 9 '__EVENTVALIDATION': '/wEWCgKFvrvOBQLs0bLrBgLs0fbZDAK/wuqQDgKAqenNDQLN7c0VAuaMg+INAveMotMNAuSStccFAvrX56AClqUwdU9ySl1Lo85TvdUwz0GrJgI='} 10 s.post(url, data) 11 return s.cookies
登录操作没有给后面的请求传递任何参数,这里的Cookies不是必须的,但是登录是必须的,这样告诉服务器我们后面的请求才是合法的。
点击查询成绩按钮:
1 def get_data_for_grade(s, number, password): 2 url = 'http://202.192.72.4/xscj_gc.aspx?xh=' + number + '&xm=%B3%C2%D6%BE%B7%AB&gnmkdm=N121605' 3 referer = 'http://202.192.72.4/xs_main.aspx?xh=' + number 4 cookies = login(s, number, password) 5 response = s.get(url=url, headers={'Referer': referer}, allow_redirects=False, cookies=cookies) 6 source = response.text 7 soup = BeautifulSoup(source, 'html.parser') 8 view_state = soup.find('input', attrs={'id': '__VIEWSTATE'})['value'] 9 event_validation = soup.find('input', attrs={'id': '__EVENTVALIDATION'})['value'] 10 states = {'view_state': view_state, 'event_validation': event_validation, 'cookies': cookies, 'origin': url} 11 return states
第五行队请求设置Referer,接着通过BeautifulSoup解析源码得到两个隐藏的<input>标签里面value值,第三个请求要用到。
查询所有成绩请求:
1 def check_info(s, number, password): 2 url = 'http://202.192.72.4/xscj_gc.aspx?xh=' + number + '&xm=1&gnmkdm=N121605' 3 states = get_data_for_grade(s, number, password) 4 print '登录成功,正在拉取成绩' 5 data = { 6 '__VIEWSTATE': states['view_state'], 7 'ddlXN': '', 8 'ddlXQ': '', 9 'Button2': '', 10 '__EVENTVALIDATION': states['event_validation'] 11 } 12 response = s.post(url, data=data, cookies=states['cookies'], headers={'Referer': states['origin']}, 13 allow_redirects=False) 14 return response.text
得到成绩单源码之后,就可以进行解析了,这里解析存放到xls表格中:
1 def writeToFile(source): 2 print '正在写入文档' 3 wb = xlwt.Workbook(encoding='utf-8', style_compression=0) 4 soup = BeautifulSoup(source, "html.parser") 5 span = soup.find('span', attrs={'id': 'Label5'}) 6 sheet = wb.add_sheet('成绩单', cell_overwrite_ok=True) 7 table = soup.find(attrs={'id': 'Datagrid1'}) 8 lines = table.find_all('tr') 9 for i in range(len(lines)): 10 tds = lines[i].find_all('td') 11 for j in range(len(tds)): 12 sheet.write(i, j, tds[j].text) 13 try: 14 os.remove(span.text + '.xls') 15 except: 16 pass 17 wb.save(span.text + '.xls')
最后遍历学号进行爬取,这里只爬取默认账号密码的成绩:
1 for i in range(1, 55): 2 num = '2013034743001' 3 s = requests.session() 4 try: 5 if i <= 9: 6 writeToFile(check_info(s, num[:12] + str(i), num[:12] + str(i))) 7 else: 8 writeToFile(check_info(s, num[:11] + str(i), num[:11] + str(i))) 9 except: 10 pass 11 s.close()


第二种方案,是通过模拟浏览器来进行登录,点击按钮等操作获取成绩,这里用到的是自动化测试框架Selenium。
这种方案的优点是我们不需要像第一种那样要去分析请求,只需要告诉浏览器要怎么做就行了,但是缺点是速度慢。
1 # -*- coding: utf-8 -*- 2 from selenium import webdriver 3 from selenium.webdriver.common.by import By 4 from selenium.webdriver.support.wait import WebDriverWait 5 from selenium.webdriver.common.action_chains import ActionChains 6 from selenium.webdriver.support import expected_conditions as EC 7 from selenium.common.exceptions import NoSuchElementException 8 from selenium.common.exceptions import NoAlertPresentException 9 from bs4 import BeautifulSoup 10 import xlwt 11 import os 12 13 14 class Script(): 15 def setUp(self): 16 self.driver = webdriver.Chrome() 17 self.driver.implicitly_wait(10) 18 # self.driver.maximize_window() 19 self.base_url = "http://202.192.72.4/" 20 self.verificationErrors = [] 21 self.accept_next_alert = True 22 23 def test_jb(self, num): 24 driver = self.driver 25 driver.get(self.base_url + "/default_gdsf.aspx") 26 driver.find_element_by_id("TextBox1").clear() 27 driver.find_element_by_id("TextBox1").send_keys(num) 28 driver.find_element_by_id("TextBox2").clear() 29 driver.find_element_by_id("TextBox2").send_keys(num) 30 driver.find_element_by_id("chkYD").click() 31 driver.find_element_by_id("btnDL").click() 32 WebDriverWait(driver, 5).until(EC.alert_is_present()).accept() 33 self.open_and_click_menu(driver) 34 retry = 0 35 while retry <= 2: 36 try: 37 driver.switch_to.frame(driver.find_element_by_id('iframeautoheight')) 38 WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//input[@id='Button2']"))) 39 break 40 except: 41 print '重新点击按钮' 42 driver.switch_to.parent_frame() 43 self.open_and_click_menu(driver) 44 retry += 1 45 else: 46 print '重试失败' 47 48 source = driver.page_source 49 driver.find_element_by_xpath("//input[@id='Button2']").click() 50 51 def source_change(driver): 52 if source == driver.page_source: 53 return False 54 else: 55 return driver.page_source 56 57 self.writeToFile(WebDriverWait(driver, 10).until(source_change)) 58 driver.quit() 59 60 def open_and_click_menu(self, driver): 61 menu1 = WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//ul[@class='nav']/li[5]"))) 62 menu2 = driver.find_element_by_xpath("//ul[@class='nav']/li[5]/ul/li[3]") 63 ActionChains(driver).move_to_element(menu1).move_to_element(menu2).click(menu2).perform() 64 65 def is_element_present(self, how, what): 66 try: 67 self.driver.find_element(by=how, value=what) 68 except NoSuchElementException as e: 69 return False 70 return True 71 72 def is_alert_present(self): 73 try: 74 self.driver.switch_to_alert() 75 except NoAlertPresentException as e: 76 return False 77 return True 78 79 def close_alert_and_get_its_text(self): 80 try: 81 alert = self.driver.switch_to_alert() 82 alert_text = alert.text 83 if self.accept_next_alert: 84 alert.accept() 85 else: 86 alert.dismiss() 87 return alert_text 88 finally: 89 self.accept_next_alert = True 90 91 def tearDown(self): 92 self.driver.quit() 93 self.assertEqual([], self.verificationErrors) 94 95 @staticmethod 96 def writeToFile(source): 97 wb = xlwt.Workbook(encoding='utf-8', style_compression=0) 98 soup = BeautifulSoup(source, "html.parser") 99 span = soup.find('span', attrs={'id': 'Label5'}) 100 sheet = wb.add_sheet('成绩单', cell_overwrite_ok=True) 101 table = soup.find(attrs={'id': 'Datagrid1'}) 102 lines = table.find_all('tr') 103 for i in range(len(lines)): 104 tds = lines[i].find_all('td') 105 for j in range(len(tds)): 106 sheet.write(i, j, tds[j].text) 107 try: 108 os.remove(span.text + '.xls') 109 except: 110 pass 111 wb.save(span.text + '.xls') 112 113 114 if __name__ == "__main__": 115 # unittest.main() 116 s = Script() 117 118 for i in range(1, 50): 119 num = '2013034743101' 120 s.setUp() 121 try: 122 if i <= 9: 123 s.test_jb(num[:12] + str(i)) 124 else: 125 s.test_jb(num[:11] + str(i)) 126 except: 127 pass
这种方法的意义只是熟悉一下自动化测试框架,因为速度实在太慢了,也就不详细介绍了,这里粗略说一下,其实原理就是通过查到网页中对应的控件,进行点击或者悬浮于上面等等的操作,一步一步的到达最后的成绩单,要做的是控制整个流程,明确在什么时候应该停一下等控件出现,什么时候要去点击。
而且到目前为止,这个框架还是有一些Bug的,比如火狐浏览器的驱动无法实现在一个按钮上Hover的操作等等。