一、缺失值
1.空值判断
isnull()空值为True,非空值为False
notnull() 空值为False,非空值为True
s = pd.Series([1,2,'3',np.nan,'hello',np.nan]) df = pd.DataFrame({'a':[1,2,np.nan,'3'],'b':[2,np.nan,'3','hello']}) print(s.isnull()) print(s[s.isnull() == False]) #求s中的非空值,或者直接s[s.notnull()] print(df.notnull()) print(df[df['b'].notnull()]) #求s中的非空值,或者df[df.isnull() == False]


0 False 1 False 2 False 3 True 4 False 5 True dtype: bool 0 1 1 2 2 3 4 hello dtype: object a b 0 True True 1 True False 2 False True 3 True True a b 0 1 2 2 NaN 3 3 3 hello
2.空值删除
dropna()删除所有出现空值的行,即任何一个字段出现空值该行都会被删除。
dropna()默认返回删除空值后的数据且不修改原数据,加参数inplace=True直接修改原数据
s = pd.Series([1,2,'3',np.nan,'hello',np.nan]) df = pd.DataFrame({'a':[1,2,np.nan,'3'],'b':[2,np.nan,'3','hello']}) print(s.dropna()) df.dropna(inplace = True) print(df)
0 1
1 2
2 3
4 hello
dtype: object
a b
0 1 2
3 3 hello
3.空值填充
fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
value 指定value填充空值,默认为None
method 填充方法,backfill/bfill使用后面的值填充,pad/ffill使用前面的值填充,默认为None
inplace 默认为False不修改原数据
limit 如果有多个空值,最多修改多少个
s = pd.Series([1,2,'3',np.nan,'hello',np.nan]) df = pd.DataFrame({'a':[1,2,np.nan,'3'],'b':[2,np.nan,'3','hello']}) print(s.fillna(0)) print(s.fillna(0,limit = 1)) print(df.fillna(method = 'bfill'))
0 1 1 2 2 3 3 0 4 hello 5 0 dtype: object 0 1 1 2 2 3 3 0 4 hello 5 NaN dtype: object a b 0 1 2 1 2 3 2 3 3 3 3 hello In [41]:
4.空值替换
replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad')
to_replace 被替换值
value 替换值
method 如果不指定value,使用method指定的方法进行替换,pad/ffill使用前面的值替换,backfill/bfill使用后面的值替换
limit 如果被替换的值有多个,最多替换多少个
s = pd.Series([1,2,'3',np.nan,'hello',np.nan]) print(s.replace(np.nan,method = 'bfill'))
0 1 1 2 2 3 3 hello 4 hello 5 NaN dtype: object
5.缺失值处理方法
①直接删除空值(根据实际意义,如果缺失值占比<2%且不好填充,可考虑直接删除)
②使用均值/中位数/众数填充
③使用前值/后值填充
④插值,拉格朗日插值法
from scipy.interpolate import lagrange x = [3,6,9] y = [10,8,4] print(lagrange(x,y),type(lagrange(x,y))) print(lagrange(x,y)(15)) df = pd.DataFrame({'x':np.arange(20)}) df['y'] = lagrange(x,y)(df['x']) plt.plot(df['x'],df['y'],linestyle='--',marker = 'o') # -0.1111 x^2 + 0.3333 x + 10 <class 'numpy.poly1d'> # -10.000000000000004
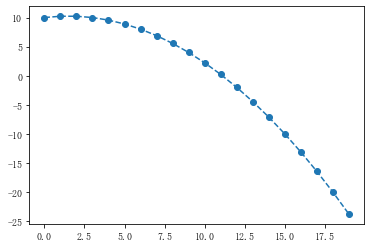
s = pd.Series(np.random.rand(100)*100) s[3,6,33,56,45,66,67,80,90] = np.nan print('数据个数为%d'%len(s)) s_na = s[s.isnull()] print('缺失值个数为%d'%len(s_na)) print('缺失值占比%.2f%%'%(100*len(s_na)/len(s))) s_handle = s.fillna(s.median()) fig,axes = plt.subplots(1,4,figsize = (20,4)) s.plot.box(ax = axes[0],title = '数据分布') s.plot(kind = 'kde',linestyle = '--',ax = axes[1],title = '折线图(默认删除缺失值)') s_handle.plot(kind = 'kde',linestyle = '--',ax = axes[2],title = '折线图(中位数填充缺失值)') def f(data,n,k = 5): y = data[list(range(n-k,n+1+k))] y = y[y.notnull()] return lagrange(y.index,list(y))(n) for i in range(len(s)): if s.isnull()[i]: s[i] = f(s,i) print(i,f(s,i))
二、异常值
异常值是指样本中的个别值明显偏离其余的样本值,异常值也称离群点,异常值的分析也称为离群点的分析。
1.异常值鉴定
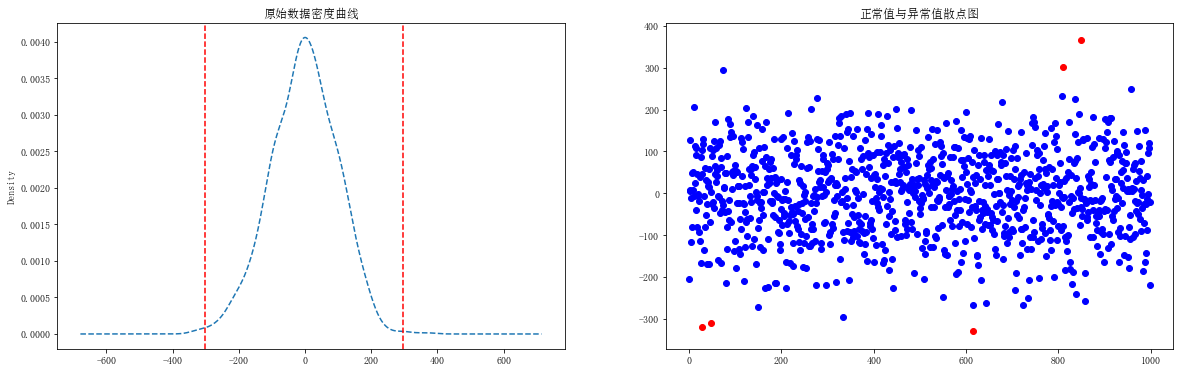
①3α原则
对于服从正态分布的样本数据,通常认为 |样本值-均值| >3倍标准差的样本值为异常值。在实际工作中可自根据实际情况自定义这个倍数。
s = pd.Series(np.random.randn(1000)*100) u = s.mean() std = s.std() print('样本均值为%.2f,标准差为%.2f'%(u,std)) p = stats.kstest(s,'norm',(u,std)).pvalue if p > 0.05: print('样本服从正态分布') fig = plt.figure(figsize = (20,6)) ax1 = fig.add_subplot(1,2,1) s.plot(kind = 'kde',linestyle ='--',title = '原始数据密度曲线') plt.axvline(u+3*std,linestyle ='--',color = 'red') #u+3*std处绘制垂直线 plt.axvline(u-3*std,linestyle ='--',color = 'red') #u-3*std处绘制垂直线 unusual = s[abs(s-u) > 3*std] #异常值 s_clean = s[abs(s-u) <= 3*std] #非异常值 print('共有%d个异常值'%len(unusual)) ax2 = fig.add_subplot(1,2,2) plt.scatter(s_clean.index,s_clean.values,color = 'b') #非异常值用蓝色表示 plt.scatter(unusual.index,unusual.values,color = 'r') #异常值用红色表示 plt.title('正常值与异常值散点图') # 样本均值为-2.56,标准差为99.70 # 样本服从正态分布 # 共有5个异常值
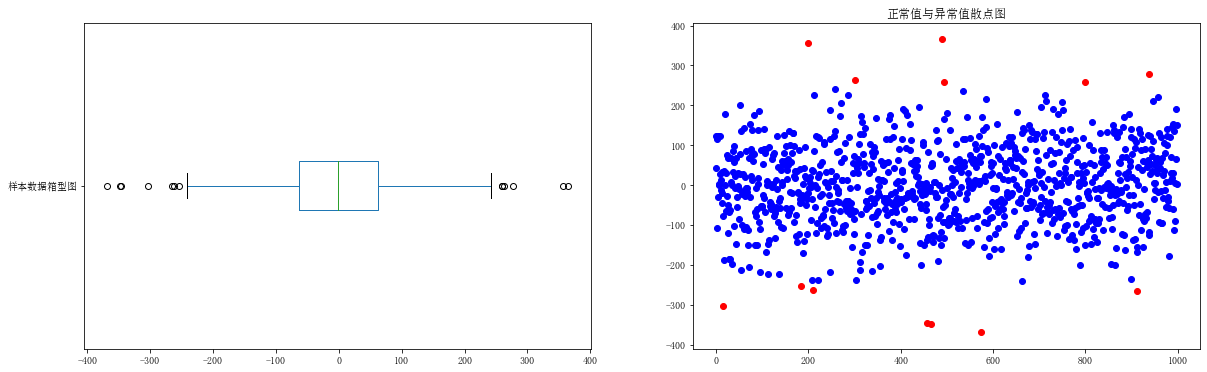
②箱型图分析
箱型图中,是将样本值 > (q3+1.5*iqr)和样本值<(q1-1.5*iqr)的样本作为异常值。
s = pd.Series(np.random.randn(1000)*100) fig = plt.figure(figsize = (20,6)) ax1 = fig.add_subplot(121) s.plot.box(vert = False,label = '样本数据箱型图') des = s.describe() q1 = des['25%'] q3 = des['75%'] iqr = q3 - q1 ma = q3 + 1.5*iqr mi = q1 - 1.5*iqr unusual = s[(s>ma)|(s<mi)] s_clean = s[(s<ma)&(s>mi)] print('共有异常值%d个'%len(unusual)) ax2 = fig.add_subplot(1,2,2) plt.scatter(s_clean.index,s_clean.values,color = 'b') #非异常值用蓝色表示 plt.scatter(unusual.index,unusual.values,color = 'r') #异常值用红色表示 plt.title('正常值与异常值散点图')
2.异常值处理
删除,或类似空值填充的方法修补。