GitHub
恳请测试的同学,一定要记得看README,去多下载一个我的.json文件和python放同一子目录下再进行评测,不然就爆0了。当然,如果爆0了,恳请告知我一声
这是我博客开通到现在,写得最难受还最长的博客,真是累了
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 30 |
| Estimate | 估计这个任务需要多少时间 | 1400 | 1580 |
| Developm | 开发 | 210 | 600 |
| Analysis | 需求分析(包括学习新技术) | 150 | 150+ |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 60 | 120 |
| Coding | 具体编码 | 210 | 600 |
| Code Review | 代码复审 | 15 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | 60 | 60 |
| Test Report | 测试报告 | 120 | 120 |
| Size Measurement | 计算工作量 | 120 | 120 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 30 | 30 |
| 合计 | 1400 | 1580 |
解题思路:
一、思考
1、难度1!2!:字符串处理
2、难度3!:补全之后的字符串处理(补全之后,调用2!级别难度代码即可)
二、查找资料
1、学习了一下正则在python下的使用(主要匹配手机号、门牌号、路名等)。
2、下载了一个四级字典来暴力匹配省(直辖市自治区)、市、地区等等。
实现过程:
一、思考(1!2!难度)
1、预处理:摘掉头部(','),去掉尾部('.'),拿出手机,放心食用。
2、省、市……分别封装,直到所下载字典的无法继续匹配的最低一级。
3、1中剩余部分,根据所到级数(记一个标志看到哪一级停止)来寻找对应关键字(镇、街道……),从而获得该级地址,若此时获得的为4级地址,则结束,余下部分即为5级地址。
4、根据输入难度,决定是否解析5级地址至7级。
5、3!的难度即为调用在线api之后,丢入2!难度处理代码(先得到5级地址,进而解析为7级地址)。
二、编码
1、面对样例编程的C++代码夭折。
2、Lv.5 $
ightarrow$ Lv.7 $
ightarrow$ 3!难度的python代码作为提交。
3、函数流图: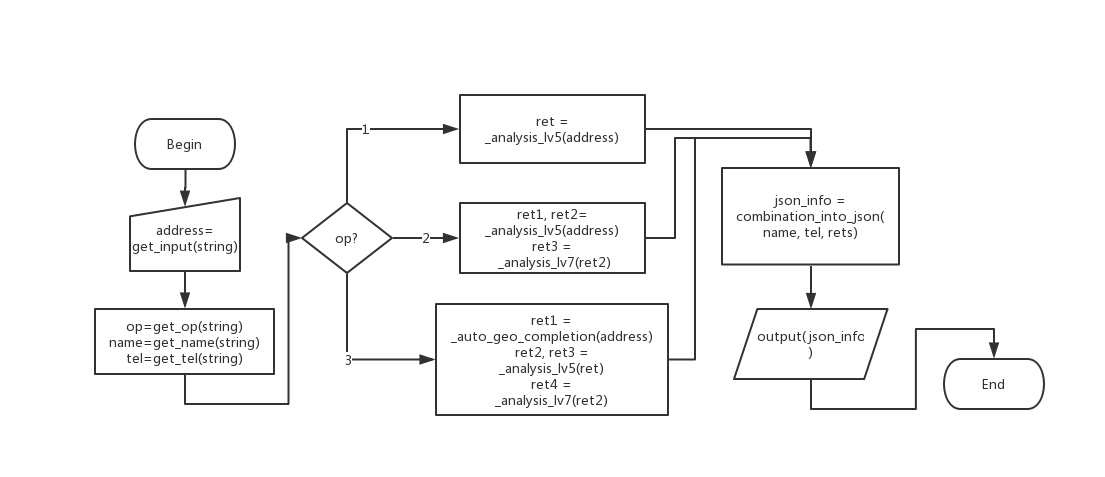
4、关键接口(代码过于冗长,故以接口说明替代):
单元测试:
一、手动测试
2!李四,福建省福州13756899511市鼓楼区鼓西街道湖滨路110号湖滨大厦一层.
'地址': ['福建省', '福州市', '鼓楼区', '鼓西街道', '湖滨路', '110号', '湖滨大厦一层']
1!张三,福建福州闽13599622362侯县上街镇福州大学10#111.
'地址': ['福建省', '福州市', '闽侯县', '上街镇', '福州大学10#111']
2!王五,福建省福州市鼓楼18960221533区五一北路123号福州鼓楼医院.
'姓名':'王五'
3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院.
'地址': ['北京市', '北京市', '东城区', '交道口街道', '交道口东大街', '1号']}(调用api补全缺失最小一级,而输入串又有缺失。解决思路:可将五级地址丢入api补全以后再解析,同时将5级剩余的详细地址存住,最后加上7级解析剩余地址的结果,即为答案)
1!小陈,广东省东莞市凤岗13965231525镇凤平路13号.
'手机': '13965231525'
二、单元测试代码
class Test_For_UnitTest(unittest.TestCase):
@classmethod
def tearDownClass(self):
pass
@classmethod
def setUpClass(self):
pass
def test_get_name(self):
_in = open('./input.txt')
_out = open('./output_name.txt')
for _data, _label in zip(_in.readlines(), _out.readlines()):
_predict = get_name(_data)
self.assertEqual(_label.rstrip('
'), _predict)
_in.close()
_out.close()
def test_auto_geo_completion(self):
_in = open('./input_broken.txt')
_out = open('./output_completion.txt')
for _broken in _in.readlines():
nw = _broken.rstrip('
')
ret = _auto_geo_completion(nw)
_out.write(ret+'
')
_in.close()
_out.close()
def test_get_tel(self):
_in = open('./input.txt')
_out = open('./output_tel.txt')
for _data, _label in zip(_in.readlines(), _out.readlines()):
_predict = ''.join(get_tel(_data))
self.assertEqual(_label.rstrip('
'), _predict)
_in.close()
_out.close()
PS:为什么有了单元测试代码,仍然还要手动测试呢?其实,单元测试的代码写起来很快,但是我解决报错问题解决了很久,仍然没有找到解决方案。报错的原因就是某些自定义函数和系统库均会报错(NameError)。吐了啊
正常情况(仅测试名字时:)
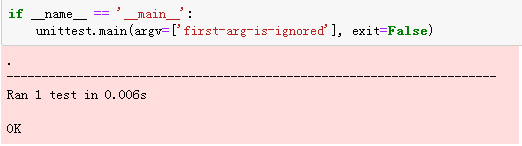
全部模块测试:

我not defined你个大头鬼啊
三、尝试解决过程:
1、调整顺序被测试函数和测试函数顺序(不要问为什么有这么蠢的操作,虽然事后我也觉得蠢,但是我真的去做过了)。结果:失败。
2、我瞟了一眼warning平时都不看warning的,无非也就是警告文件没关,你都给我异常了,我拿什么给你关文件啊。结果:补一下try-catch。
class Test_For_UnitTest(unittest.TestCase):
@classmethod
def tearDownClass(self):
pass
@classmethod
def setUpClass(self):
pass
def test_get_name(self):
_in = open('./input.txt')
_out = open('./output_name.txt')
for _data, _label in zip(_in.readlines(), _out.readlines()):
_predict = get_name(_data)
self.assertEqual(_label.rstrip('
'), _predict)
_in.close()
_out.close()
def test_get_tel(self):
_in = open('./input.txt')
_out = open('./output_tel.txt')
#_see = open('./see.txt')
for _data, _label in zip(_in.readlines(), _out.readlines()):
try:
_predict = ''.join(get_tel(_data))
#_see.write(predict+'
')
self.assertEqual(_label.rstrip('
'), _predict)
except Exception as NameError:
_in.close()
_out.close()
_in.close()
_out.close()
#_see.close()
def test_auto_geo_completion(self):
_in = open('./input_broken.txt')
_out = open('./output_completion.txt')
for _broken in _in.readlines():
nw = _broken.rstrip('
')
try:
ret = _auto_geo_completion(nw)
_out.write(ret+'
')
except Exception as NameError:
_in.close()
_out.close()
_in.close()
_out.close()
结果:
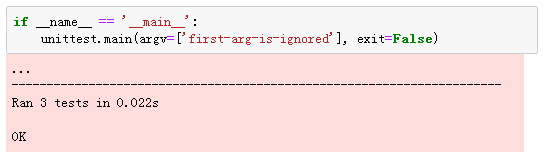
!!!我可以,我真的可以,它好了。其实,并没有好,因为我在try的时候尝试写文件(_see.txt,test_get_tel()代码中注释部分),结果发现文件里并没有东西,只是因为加了异常处理使得程序能够跑完而已。(表面ok,其实还是gg)
性能改进:
1、主要是想把python写得短一点,葬送了4小时无果,不太熟悉此类代码如何减少编码复杂度。
2、因为输入的极短(每条地址信息),几乎没有考虑过时间复杂度,满屏的库操作。
3、函数开销(三幅图分别对应1,2,3难度,在命令行得到结果后,写入文件):

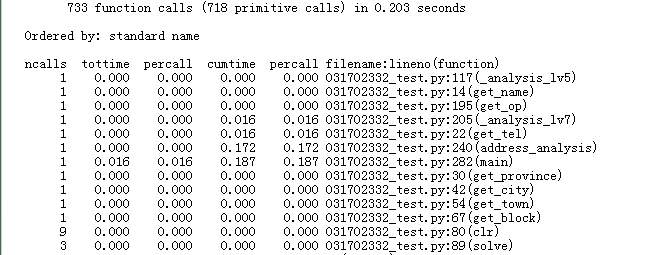
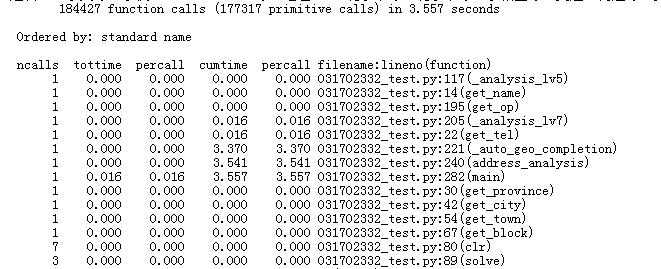
可以看出3难度下,调用高德地图在线api时,程序的时间开销瞬间上涨。
参数解释:
ncalls:表示函数调用的次数。
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间。
percall:(第一个 percall)等于 tottime/ncalls。
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间。
percall:(第二个 percall)即函数运行一次的平均时间,等于 cumtime/ncalls。
filename:lineno(function):每个函数调用的具体信息。
参考:使用 profile 进行python代码性能分析
大量数据结果:
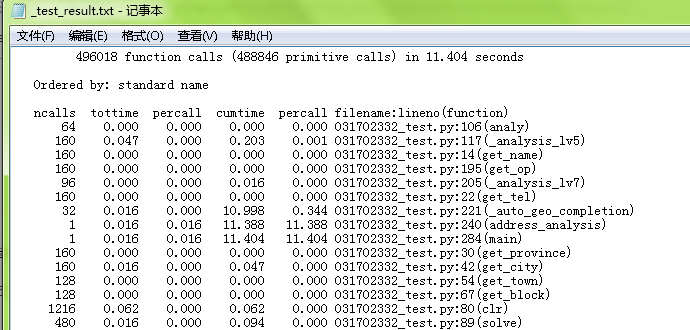
没想到就160条数据,就得跑这么久
异常处理:
1、对于3!难度下,若样例前4级地址缺失,代码会报错无法运行,针对此在得知该条信息的需求难度时,若为3!,先进行补全。
2、字典的键值错误(KeyError),主要是通过最后一个样例发现(广东省……),于是增加了标志信息。
3、上面单元测试的异常处理,能算么?满(恬)怀(不)期(知)待(耻)
4、发现评测时会出现ValueError,故捕获了之后就能正常输出。
try:
_json_info = {'姓名':'','手机':'','地址':[]}
s = input()
s = s[:len(s)-1]
_op, s = get_op(s, '!')
_op = int(_op)
_name = get_name(s)
#print(_name)
_json_info['姓名'] = _name
s = s[s.find(',')+1:]
_tel = ''.join(get_tel(s))
#print(_tel)
_json_info['手机'] = _tel
s = clr(s,_tel)
if (_op==1):
_addr, _res = _analysis_lv5(s, dic)
_addr.append(_res)
_json_info['地址'] = _addr
elif (_op==2):
_addr, _res = _analysis_lv5(s, dic)
_more_detail = _analysis_lv7(_res)
_addr = _addr + _more_detail
_json_info['地址'] = _addr
else:
_full_addr = _auto_geo_completion(s)
#print('full_addr = ',_full_addr)
_addr, _res = _analysis_lv5(_full_addr, dic)
_more_detail = _analysis_lv7(_res)
_json_info['地址'] = _addr + _more_detail
except ValueError:
print(json.dumps(_json_info, ensure_ascii=False))
else:
print(json.dumps(_json_info, ensure_ascii=False))
心路历程和收获:
我会说我都要写吐了?
显然,低估了题目难度。我拿到题目之后第一反应就是NLP啊,这一个礼拜做个鬼啊,但是在看了一眼各种友好的输入约束,我就直接想——这不就是个几乎不用考虑时间复杂度的字符串处理吗?可以顺心所欲地用stl了,于是我在作业布置的当天(2019.9.10)敲了一下午,晚上回来准备就寝之时,被群友告知C++要注意编码(需要utf-8,而默认是GBK),可以使用python等云云。差点翻身下来打技术助教舍友周六早上(2019.9.14,期间都在准备网络赛事宜)犹豫了一下,再加上看到了同学python简短的代码,我上了python的船,开始怎么简单编码怎么来,怎么好写怎么来,没多久就写完了5级解析(然而,按照同学的说法我写的python一点都不pythonable),自己想想怎么这么丑呢?算了,有空改,于是乎我在(2019.9.15)晚上,看着我冗长的代码,我进行了重构!4小时后,我放弃了,我把自己秀没了,乖乖地用了周六写的代码,加了点东西,写出了7级解析。接下来是附加题,本来不想做附加题的,因为显然就是NLP的课题,但是!群里说可以调在线api!我真是服了,然后(当然不是马上),我就去调了api,勉强算是写完了附加题(效果不好,没想到怎么处理最后补全之后解析,具体建筑物缺失的问题)。
就是在得知可以调用在线api的时候,技术助教(也就是我隔壁床的狗头舍友)发了一个分享,果然biLSTM的大字赫然在列(为什么需要有记忆性?盲猜是因为补全的话,显然是需要记忆性的,例如:福州闽侯,倘若没有记忆性,万一还有别的地方叫闽侯,结果就可能不唯一或是出错,这显然不是我们想要的,因为我们在之前限定了是福州的闽侯),而这不调用接口肯定难度上升很多,并且效果会差很多,甚至写出个不work的东西。而在我看来,如果不调用接口,我的想法就目前是爬下完整字典,然后匹配了。 而至于调用api,则是将残缺地址先转为经纬度,然后再从经纬度转回完整地址(两次api调用)。
(吐槽,非战斗人员请迅速撤离)据说评测没有部分分,就是地址一旦出错,该点爆0,建议修改评测机制(建议改成地址部分分)。泱泱华夏,地名汤汤,鄙人才疏学浅,如何毫厘不差?感觉自己就是个天坑,从第一次用SIFT提取32x32的灰度图的沙雕操作之后,怎么打python怎么踩坑,当然有才疏学浅的原因,奇怪的是每次踩坑都有“沙雕”网友也踩过,总能找到一些类似的解决方案,试着试着就过了,在自闭中冷静,在冷静中自闭(哇,自闭了,怎么会有这种错误$
ightarrow$xswl,有个沙雕网友也遇到了,那应该是能解决了$
ightarrow$服了啊,怎么对我没用啊$
ightarrow$......解决了,可是为什么?)真的打的我好气,边骂边打。未完待续仍有一丝侥幸,最后自闭实属原地自爆。