购买的固定代理IP一般都需要账号密码, 在网上找了几个使用方法,但是都报错,所以,就想了这个笨办法,如有好办法希望大家指点。
import requests from requests.auth import HTTPBasicAuth proxy = { 'http': 'http://ip:port', 'https': 'https://ip:port8' } head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/50.0.2661.102 Safari/537.36', 'Connection': 'keep-alive', 'Proxy-Authorization': '...' # 在浏览器中获取此值 } p = requests.get('http://icanhazip.com', headers=head) print(p.content.decode('utf-8'))
# ########################## 下面是获取Proxy-Authorization的方法############################################
首先,就是获取在headers 中的 Proxy-Authorization
用的是Chrome浏览器, 设置代理ip

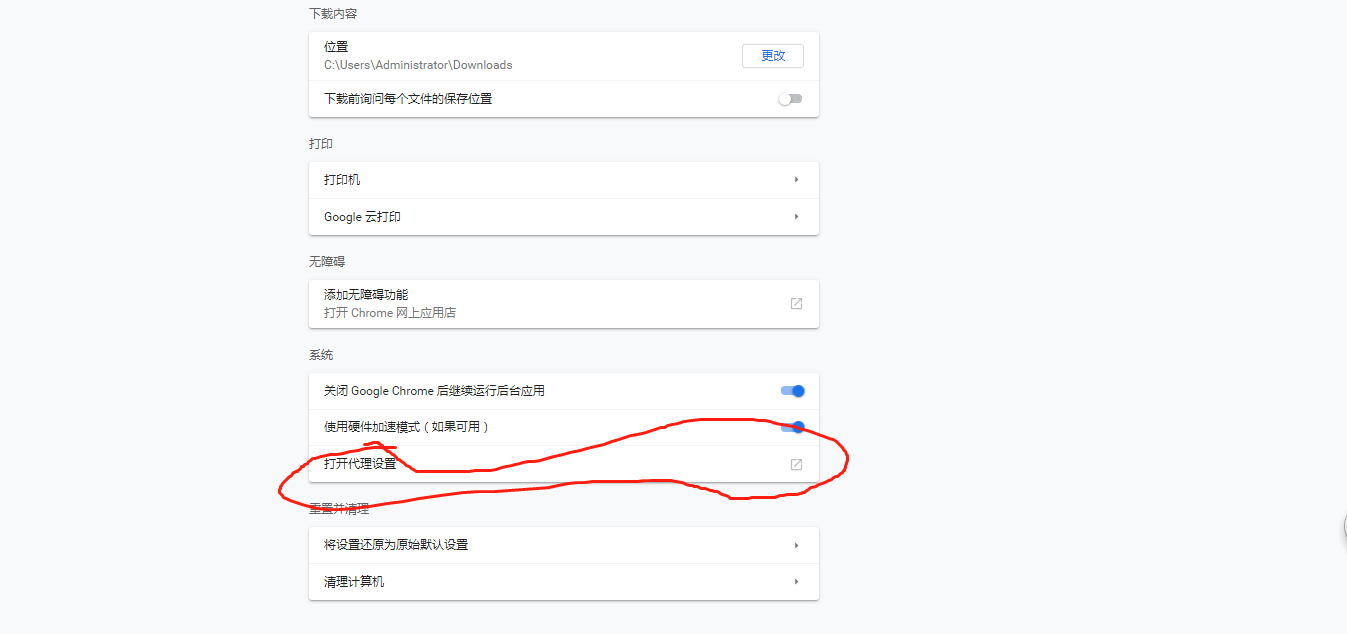
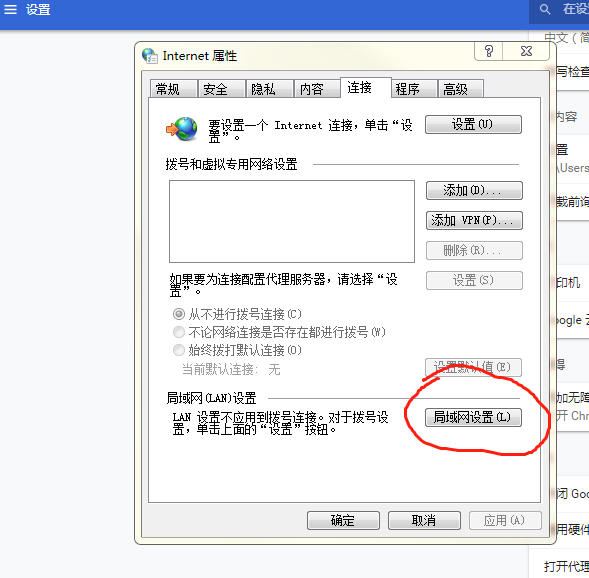

然后点击 确定
打开一个新的网页, 随意登录一个网站

登录后, 访问 http://127.0.0.1
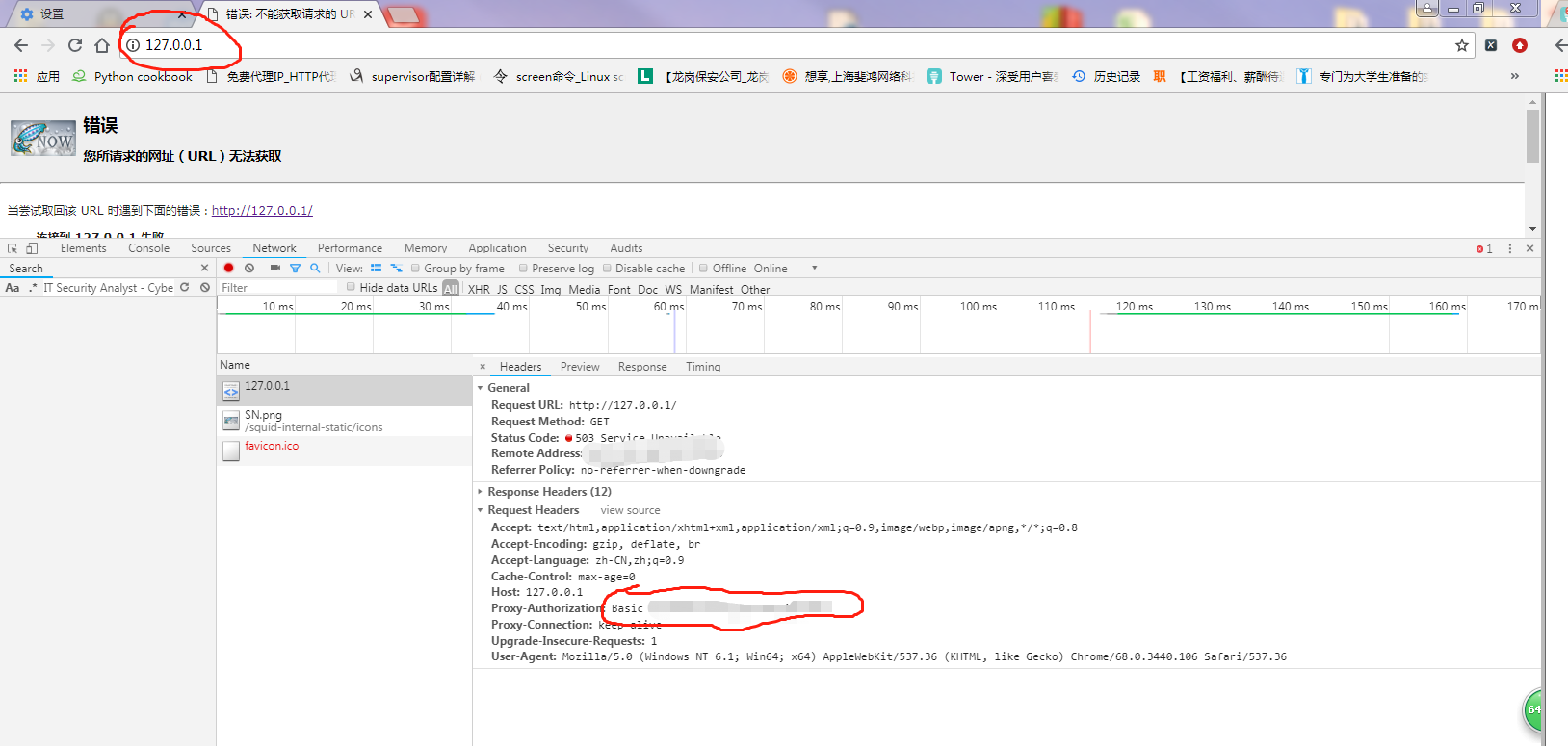
在scrapy的中间件中添加:
request.meta['proxy'] = "http://ip:port" # 添加Proxy-Authorization对应得值,添加在请求的headers中 request.headers['Proxy-Authorization'] = 'Basic ...........'
这样就将固定ip设置为代理了~