本文打算对这小段时间学习 scala 以及 spark 编程技术做个小结,一来温故而知新,而来为以后查阅方便
spark scala 入门小例子


文本文件 UserPurchaseHistory.csv: John,iPhone Cover,9.99 John,Headphones,5.49 Jack,iPhone Cover,9.99 Jill,Samsung Galaxy Cover,8.95 Bob,iPad Cover,5.49 下面开始读取文件进行分析 package com.ghc.bigdata import org.apache.spark.{SparkConf, SparkContext} /** * Created by Yu Li on 12/5/2017. */ object ScalaApp { def main(args:Array[String]):Unit={ val sparkConf=new SparkConf() sparkConf.setMaster("local[2]") sparkConf.setAppName("Scala App") val sc=new SparkContext(sparkConf) val textFromFile=sc.textFile("./src/main/scala/UserPurchaseHistory.csv") val data=textFromFile.map(x=>x.split(",")).map(p=>(p(0),p(1),p(2))) //购买次数 val countOfPurchase=data.count() //多少不同客户购买过商品 val distinctCountOfPurchase=data.map(x=>x._1).distinct.count() println("共有 "+distinctCountOfPurchase+" 不同客户购买过商品") println("共有 "+data.map{case(user,product,price)=>user}.distinct.count()+" 不同客户购买过商品") val totalRevenue=data.map{case(user,product,price)=>price.toDouble}.sum() //只有 double才能 sum println("totalRevenue: "+totalRevenue) //最畅销的产品,可以想到对产品分组求和 reduceByKey val mostPoplularProduct=data.map{case(user,product,price)=>(product,1)}.reduceByKey(_+_).collect().sortBy(-_._2) // 负是倒序的意思 println(mostPoplularProduct.mkString(",")) println("mostPoplularProduct: "+mostPoplularProduct(0)) //mostPoplularProduct(0) println("共购买:"+countOfPurchase+" 件商品") println("共有 "+data.map{case(user,product,price)=>user}.distinct.count()+" 不同客户购买过商品") println("总收入: "+totalRevenue) println("最畅销的产品是: %s 购买了 %d 件".format(mostPoplularProduct.take(1)(0)._1,mostPoplularProduct.take(1)(0)._2)) } } package com.ghc.bigdata import org.apache.spark.{SparkConf,SparkContext} /** * Created by Yu Li on 12/6/2017. */ object SparkScalaApp { def main(args:Array[String]):Unit={ val sparkConf:SparkConf=new SparkConf() sparkConf.setAppName("Spark Scala App") sparkConf.setMaster("local[2]") val sc:SparkContext=new SparkContext(sparkConf) val fileName:String="./src/main/scala/UserPurchaseHistory.csv" printResult(sc,fileName) } /*println("共购买:*/ def printResult(sc:SparkContext,fileName:String):Unit={ // 共购买多少产品 val rawRDD=sc.textFile(fileName).map(x=>x.split(",")).map(purchase=>(purchase(0),purchase(1),purchase(2))) val countOfPurchase=rawRDD.count() // 共有多少不同客户购买产品 val countOfDistinctPurchase=rawRDD.map{case(user,item,price)=>user}.distinct.count() // 总收入 val sumRevenue=rawRDD.map{case(user,item,price)=>price.toDouble}.sum() //每一类产品收入 val sumGroupByItemRevenue=rawRDD.map{case(user,item,price)=>(item,price.toDouble)}.reduceByKey(_+_).sortBy(-_._2).collect()(0) //按照每一类商品收入倒序取最大的那个值 // 最畅销的产品 val mostPopularItem=rawRDD.map{case(user,item,price)=>(item,1)}.reduceByKey(_+_).sortBy(-_._2).collect()(0) println("共购买 "+countOfPurchase+" 件商品") println("共有 "+countOfDistinctPurchase+" 个不同用户购买过商品") println("总收入 "+sumRevenue) println("收入最高的商品是 %s 卖了 %.2f 钱".format(sumGroupByItemRevenue._1,sumGroupByItemRevenue._2)) println("最畅销的产品是 %s 卖了 %d 件".format(mostPopularItem._1,mostPopularItem._2)) } }
package com.ghc.bigdata import org.apache.spark.{SparkConf,SparkContext} /** * Created by Yu Li on 12/6/2017. */ object SparkScalaApp { def main(args:Array[String]):Unit={ val sparkConf:SparkConf=new SparkConf() sparkConf.setAppName("Spark Scala App") sparkConf.setMaster("local[2]") val sc:SparkContext=new SparkContext(sparkConf) println("2 在List中的位置: "+getPosition(List(1,2,3),2)) for(i<- map[Int,String](List(1,2,3),{num:Int=>num+"2"})){ println(i) } } def getPosition[A](l:List[A],v:A): Int ={ l.indexOf(v) } def map[A,B](list:List[A],func: A=>B)=list.map(func) }
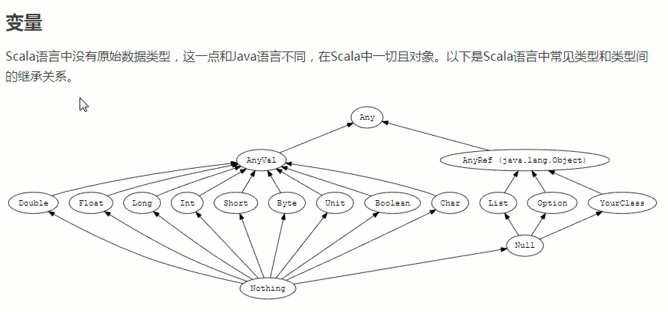
package com.ghc.spark.sql import java.io.{BufferedReader, File, IOException} import scala.collection.mutable.ArrayBuffer import scala.io.{BufferedSource, Source} import scala.util.Random abstract class Animal{ def move() val name:String } class Dog extends Animal{ override val name="trump" override def move(): Unit = { println(this.name+" move...") } } object Dog{ def apply(): Dog = { new Dog() } } class SuperDog(){ def fly(): Unit ={ println("fly...") } } class RichFile(file:File){ def read(){ val source: BufferedSource = Source.fromFile(file.getPath) source.bufferedReader().readLine() } } object DeepScala { def main(args:Array[String]): Unit ={ /*println(sum(1,2,3)) val dog:Dog = Dog() dog.move() match1() println(match1PartialFunc("frank")) match2(1) match2("abc") match2(Map(1->"a", 2->"b")) match2(Array(1,2,3)) matchException() matchCaseClass() println(s"add result: ${add(3,4)}") println(s"sum result ${sum(3)(4)}") */ implicit def Dog2SuperDog(dog:Dog):SuperDog={ new SuperDog() } val dog = Dog() dog.fly() implicit def file2RichFile(file:File): RichFile ={new RichFile(file)} val file = new File("C:\Users\Administrator\IdeaProjects\sparkapi\input\words.txt") println(file.read()) readLine("C:\\Users\\Administrator\\IdeaProjects\\sparkapi\\input\\words.txt") readNet("http://www.baidu.com") high_func() } def sum(numbers:Int*):Int = { var result = 0 for(number <- numbers){ result += number } result } // 简单基本数据类型值匹配 def match1()={ val arr = Array("frank", "stacy", "unknown") val name = arr(Random.nextInt(arr.length)) name match{ case "frank" => println("me") case "stacy" => println("lover") case _ => println("frank love stacy") } } def match1PartialFunc:PartialFunction[String, String]={ case "frank" => "me" case "stacy" => "she" case _ => "unknown" } // 类型匹配 def match2(obj:Any):Unit={ obj match{ case x:Int => println("obj is Int") case y:String => println("obj is String") case m:Map[_,_] => m.foreach(println) case _ => println("other type...") } } // IO Exception var source:BufferedSource = null; def matchException()= { try { source = Source.fromFile("input/words.txt") val reader: BufferedReader = source.bufferedReader() var line: String = reader.readLine() var content: ArrayBuffer[String] = ArrayBuffer[String]() // 可变数组 while (line != null) { content += line line = reader.readLine() } content.flatMap(_.split("\s+")) .map((_, 1)) .groupBy(_._1) .toList .map(t => (t._1, (for (i <- t._2) yield i._2).reduce(_ + _) )) .sortBy(_._2) .foreach(println) } catch { case ex: IOException => println(ex.toString) case ex: Exception => println(ex.toString) case _: Any => println("whatever...") }finally { source.close() } } // case class match def matchCaseClass(){ trait Person case class CTO(name: String, age: Int) extends Person case class Manager(name: String, age: Int) extends Person case class Clerk(age: Int, desc: String) extends Person val arr = CTO("CTO No.007 Linux", 18) :: Manager("Manager No.001 Frank", 20) :: Clerk(25, "no desc...") :: Nil val x = arr(Random.nextInt(arr.length)) x match{ case CTO(name, age) => printf("CTO<%s , %d>", name, age) case Manager(name, age) => printf("Manager<%s , %d>", name, age) case Clerk(age, desc) => println(s"Clerk<$age, $desc>") case _ => println(s"default match") } val multi_lines = """ |first line |second line |third line """.stripMargin println(multi_lines) } // 匿名函数 def add = (a:Int, b:Int) => a+b // curring def sum(a:Int)(b:Int) = {a+b} // aggregate(0) (_+_, _+_) // 高阶函数 def high_func(): Unit ={ val numbers = List(List(1,2,3), List(4,5,6), List(7,8,9)) val res1 = numbers.map(_.map(_*2)).flatten val res2 = numbers.flatMap(_.map(_*2)) val res3 = numbers.flatMap(t=> (for(i<-t) yield i*2)) println(s"res1: ${res1} res2: ${res2} res3: ${res3}") } // IO def readLine(filePath:String):Unit={ val file = Source.fromFile(filePath) for(line <- file.getLines()){ println(line) } } def readNet(url:String="http://www.baidu.com"): Unit ={ val netFile = Source.fromURL(url) for(file <- netFile.getLines()){ println(file) } } }
spark 线性回归算法预测谋杀率
package com.ghc.bigdata import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession} import org.apache.log4j.{Level, Logger} /** * Created by Yu Li on 12/7/2017. */ // 因为 ml 推荐使用 DataFrame 所以下面开始都用 DataFrame object LRDemo { def main(args:Array[String]):Unit={ //屏蔽日志 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) //设置 Spark 模拟环境 val sparkConf=new SparkConf().setAppName("Regression Demo").setMaster("local[2]") val sc=new SparkContext(sparkConf) //真实文本数据转化为 VectorDataFrame 准备真实数据集 val realFile="./src/main/scala/com/ghc/bigdata/LR_data" val delimeter="," val vecDF_real=transform2VectorDFFromFile(sc,realFile,delimeter) println("start print df from real: ") println(vecDF_real.collect.mkString(" ")) //预测文本数据转化为 VectorDataFrame 准备预测数据集 可以 select 的 val predictFile="./src/main/scala/com/ghc/bigdata/LR_data_for_predict" val vecDF_predict=transform2VectorDFFromFile(sc,predictFile,delimeter) println("start print df from predict: ") println(vecDF_real.collect.mkString(" ")) // res: 1 行 50 列 , 每列 里又是 1 行 2 列 左边,由 select 可知 [ [A]] A 里的是 feature 列 // [3615.0,3624.0,2.1,69.05,15.1,41.3,20.0,50708.0,[3615.0,3624.0,2.1,69.05,41.3,20.0,50708.0]] //建立模型预测 谋杀率 //设置线性回归参数 val lr=new LinearRegression() lr.setFeaturesCol("features") // 设置特征列 lr.setLabelCol("Murder") // 设置需要被预测的列 lr.setFitIntercept(true) // 数据中心化 lr.setMaxIter(20) // 设置迭代次数 lr.setRegParam(0.4) // 设置正则化参数 lr.setElasticNetParam(0.8) //设置弹性化混合参数 // 将真实数据 训练集合代入训练 val lrModel=lr.fit(vecDF_real) // 代入真实数据 lrModel.extractParamMap() // 输出模型全部参数 println(s"coefficients: ${lrModel.coefficients},intercept: ${lrModel.intercept}") //对训练结果进行评价 val trainingSummary=lrModel.summary println(s"numIterations: ${trainingSummary.totalIterations}") //总迭代次数 println(s"objectiveHistory: ${trainingSummary.objectiveHistory.toList}") //每次迭代损失?依次递减 trainingSummary.residuals.show()// 残差 println(s"RMSE: ${trainingSummary.rootMeanSquaredError}") //均方根差 RMSE(均方根、标准差) println(s"r2: ${trainingSummary.r2}") //决定系数 val predictions: DataFrame = lrModel.transform(vecDF_predict) // 用同一个模型来训练 println("输出预测结果") val predict_result: DataFrame =predictions.selectExpr("features","Murder", "round(prediction,1) as prediction") predict_result.foreach(println(_)) sc.stop() } //定义一个从文件中获取 VectorDataFrame 的方法,因为实际文本数据与预测文本数据都需要,便于复用 def transform2VectorDFFromFile(sc:SparkContext,fileName:String,delimeter:String):DataFrame={ val sqc=new SQLContext(sc) // SQLContext是过时的,被 SparkSession 替代 val raw_data=sc.textFile(fileName) val map_data=raw_data.map{x=> val split_list=x.split(delimeter) (split_list(0).toDouble,split_list(1).toDouble,split_list(2).toDouble,split_list(3).toDouble,split_list(4).toDouble,split_list(5).toDouble,split_list(6).toDouble,split_list(7).toDouble)} val df=sqc.createDataFrame(map_data) val data = df.toDF("Population", "Income", "Illiteracy", "LifeExp", "Murder", "HSGrad", "Frost", "Area") val colArray = Array("Population", "Income", "Illiteracy", "LifeExp", "HSGrad", "Frost", "Area") val assembler = new VectorAssembler().setInputCols(colArray).setOutputCol("features") val vecDF: DataFrame = assembler.transform(data) vecDF } }