
入门python好博客
进阶大纲
有趣的灵魂
老齐的教程
老齐还整理了很多精华
听说 fluent python + pro python 这两本书还不错!
元组三种遍历,有点像回字有四种写法一样。。。苦笑
for index in range(0,len(tuple_1)):
... print(tuple_1[index])
>>> for index in range(0,len(tuple_1)):
... print('{}--{}'.format(index,tuple_1[index]))
>>> tuple_1 = (1,2,'hello','world')
>>> for content in tuple_1:
... print(content)
>>> for index,enum in enumerate(tuple_1):
... print('{}--{}'.format(index,enum))
# 黑魔法咩? map ,reduce
from functools import reduce
def str2int(s):
Digital = {'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9}
return Digital[s]
def str_reduce(s):
l = list(map(str2int,s))
if not isinstance(s, str):
raise ValueError('输入不是字符串类型!')
return reduce(lambda x,y:x+y,[v * 10**(len(l)-i-1) for i , v in enumerate(l)])
str_reduce('213')
# 更加 逆天的 map 用法,不论传入的 list 是普通值 还是 func 都行
>>> for i in range(10):
... print(list(map(lambda x:x(i),[lambda x:x+x,lambda x:x**2])))
# filter 用法
>>> list_1 = [i for i in range(30) if i%2 == 1]
>>> list_1
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29]
>>> list(filter(lambda x:x<10,list_1))
[1, 3, 5, 7, 9]
tuple 互转 tuple(list_1) , list(tuple_2)
>>> import os
>>> print(os.path.abspath('.'))
C:UsersFrankLiDesktop
>>> import sys
>>> print(sys.argv)
['']
>>> print(sys.executable)
D:Program Files (x86)pythonpython.exe
- 列表生成式 vs 生成器表达式
>>> [x for x in list_1 if x%2==1]
[1, 3, 5]
>>> (x for x in list_1 if x%2==1)
<generator object <genexpr> at 0x033C2660>
>>> gen = (x for x in range(0,10) if x%3==1)
>>> for x in gen:
... print(x)
...
1
4
7
>>> #这是一个生成器应用,斐波拉契数列
... def fib(max):
... n,a,b=0,1,1
... while n<=max:
... yield b
... a,b=b,a+b
... n=n+1
... return 'Nore More!'
...
>>> for f in fib(6):
... print('fib: {}'.format(f))
...
fib: 1
fib: 2
fib: 3
fib: 5
fib: 8
fib: 13
fib: 21
>>> def fib(x):
... a,b = 1,1
... for i in range(x):
... yield a
... a,b = b,a+b
...
>>> for i in fib(10):
... print(i)
...
1
1
2
3
5
8
13
21
34
55
#获取生成器重的 return 返回值 Nore More!
>>> g = fib(6)
>>> while True:
... try:
... x=next(g)
... print('g: {}'.format(x))
... except StopIteration as e:
... print('evalue: {}'.format(e.value))
... break
...
g: 1
g: 2
g: 3
g: 5
g: 8
g: 13
g: 21
evalue: Nore More!
# string 也是序列可以被迭代 iter(s) 即可
>>> s = 'google'
>>> s_iter = iter(s)
>>> while True:
... try:
... print(next(s_iter))
... except StopIteration as stopIter:
... print('done')
... break
...
g
o
o
g
l
e
done
>>> # 杨辉三角末尾补零两数相加大法
... def triangle():
... l=[1]
... while True:
... yield l
... l.append(0)
... l=[l[i-1]+l[i] for i in range(0,len(l))]
调用杨辉三角生成器
>>> n=0
>>> for e in triangle():
... n=n+1
... print(e,' ')
... if n==10:
... break
...
[1]
[1, 1]
[1, 2, 1]
[1, 3, 3, 1]
[1, 4, 6, 4, 1]
[1, 5, 10, 10, 5, 1]
[1, 6, 15, 20, 15, 6, 1]
[1, 7, 21, 35, 35, 21, 7, 1]
[1, 8, 28, 56, 70, 56, 28, 8, 1]
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
迭代器
Generator 天然的 迭代器
而 tuple , list 等 序列如果要编程 迭代器 需要 iter(list_1) 、iter(tuple_2)
>>> from collections import Iterator
>>> isinstance((1,2,3,4),Iterator)
False
>>> isinstance((x for x in range(10) if x%2==0),Iterator)
True
>>>
>>> isinstance(iter((1,2,3,4)),Iterator)
True
>>>
>>> list_1 = [1,2,3,4]
>>> list_1_iter = iter(list_1)
>>> while True:
... try:
... x=next(list_1_iter)
... print('x:{}'.format(x))
... except StopIteration as e:
... print('e.value: {}'.format(e.value))
... break
...
x:1
x:2
x:3
x:4
e.value: None
- python map reduce 实现
>>> def pow2(val):
... return val**2
...
>>> list_1 = [1,2,3,4,5]
>>> list(map(pow2,list_1))
[1, 4, 9, 16, 25]
>>> def sum(x,y):
... return x+y
...
>>> from functools import reduce
>>> reduce(sum,list(map(pow2,list_1)))
55
强悍的 lambda
>>> from functools import reduce
>>> reduce(lambda x,y:x+y,list(map(lambda x:x**2,[1,2,3,4,5,6,7])))
- 注意区别 Iterable 可迭代 与 Iterator 惰性迭代器
高阶函数
>>> def lazy_sum(*args):
... def sum():
... ax=0
... for n in args:
... ax=ax+n
... return ax
... return sum
...
>>> lazy_sum(1,2,3,4,5)
<function lazy_sum.<locals>.sum at 0x013902B8>
>>> f=lazy_sum(1,2,3,4,5)
>>> f()
15
win 下 python 清屏
>>> import os
>>> def clear():
... os.system('cls')
>>> import os
>>> def cls():
... if os.name.upper() == 'NT':
... os.system('cls')
... else:
... os.system('clear')
可变参数,巧调用
python的可变参数和关键字参数(*args **kw)
讲*args 可变参数, **kw 关键字参数非常好的文章
>>> def test(*args):
... sum=0
... for n in args:
... sum=sum+n
... return sum
... test([1,2,3,4])
File "<stdin>", line 6
test([1,2,3,4])
^
SyntaxError: invalid syntax
>>> test(*[1,2,3,4])
10
>>> test(1,2,3,4)
10
在 python3 中已经废除了 dict 的 has_key 方法 用 key in dict 这种方式代替
>>> def person(*args,**kw):
... l=[]
... for n in args:
... l.append(n)
... dic=kw
... if 'city' in dic:
... pass
... if 'job' in dic:
... pass
... print('l:{} dic {}'.format(l,dic))
...
>>> person('tom',2,city='changsha',job='unknown')
l:['tom', 2] dic {'city': 'changsha', 'job': 'unknown'}
进阶
>>> extra = {'city':'cs','job':'developer'}
>>> tuple=('tom',30)
>>> person(*tuple,**extra)
l:['tom', 30] dic {'city': 'cs', 'job': 'developer'}
>>>
装饰器类似于 java 里的 AOP 动态代理,或者继承组合
>>> import functools
>>> #自定义文本消息的事务装饰器
... def trans(text):
... def decorater(func):
... @functools.wraps(func)
... def wrapper(*args,**kw):
... print('{} {}'.format(text,func.__name__))
... return func(*args,**kw)
... return wrapper
... return decorater
...
>>> @trans('开启事务'):
File "<stdin>", line 1
@trans('开启事务'):
^
SyntaxError: invalid syntax
>>> @trans('开启事务')
... def trans_func():
... print('我是一个要被事务装饰的函数')
...
>>> trans_func()
开启事务 trans_func
我是一个要被事务装饰的函数
>>> from functools import wraps
>>> def my_decorator(func):
... @wraps(func)
... def wrap_func():
... print('before...')
... func()
... print('after...')
... return wrap_func
...
>>> @my_decorator
... def func_a():
... print('func_a...')
...
>>> func_a()
before...
func_a...
after...
>>> func_a.__name__
'func_a'
>>> from functools import wraps
>>> def custom_text(text):
... def decorater(func):
... @wraps(func)
... def wrap_decorated(*args,**kwargs):
... print('{} {}'.format(text,func.__name__))
... return func(*args,**kwargs)
... return wrap_decorated
... return decorater
...
>>> @custom_text('自定义文本信息...')
... def tran(*args,**kwargs):
... for i in args:
... print(i,end=',')
... for key,value in kwargs.items():
... print('{}-->{}'.format(key,value))
... print('事务...社会...')
...
>>> args = (1,'abc',3)
>>> from functools import wraps
>>> kwargs = dict(name='Frank',age=18)
>>> tran(*args,**kwargs)
自定义文本信息... tran
1,abc,3,name-->Frank
age-->18
事务...社会...
from functools import wraps
class LogIt(object):
def __init__(self,log_file='out.log'):
self._log_file = log_file
@property
def log_file(self):
return self._log_file
@log_file.setter
def log_file(self,log_file):
self._log_file = log_file
def __call__(self,func):
@wraps(func)
def wrap_func(*args,**kwargs):
log_string = '{} {}'.format(func.__name__,'called...')
print('wrap_func logging...{}'+log_string)
with open(self.log_file,'a') as logfile:
logfile.write(log_string+'
')
self.notify(log_string)
return func(*args,**kwargs)
return wrap_func
def notify(self,log_string):
print('notify logging...{}'.format(log_string))
@LogIt('out1.log')
def trans(*args,**kwargs):
for i in args:
print(i,end=',')
for key,value in kwargs.items():
pritn('{}<-->{}'.format(key,value))
args = ('trans start..',1,2,'test')
kwargs = dict(name='Frank',age=18)
trans(*args,*kwargs)
wrap_func logging...{}trans called...
notify logging...trans called...
trans start..,1,2,test,name,age,
偏函数,可以见 functools 多么强大值得好好学学
>>> convert_int_from_8 = functools.partial(int,base=8)
>>> convert_int_from_8(12345)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: int() can't convert non-string with explicit base
>>> convert_int_from_8('12345')
5349
# kw 这种 dict 传值也是可以的
>>> kw = {'base':8}
>>> convert_int_from_8 = functools.partial(int,base)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'base' is not defined
>>> convert_int_from_8 = functools.partial(int,**kw)
>>> convert_int_from_8('123456')
最后,创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,当传入:
int2 = functools.partial(int, base=2)
实际上固定了int()函数的关键字参数base,也就是:
int2('10010')
相当于:
kw = { 'base': 2 }
int('10010', **kw)
当传入:
max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是:
max2(5, 6, 7)
相当于:
args = (10, 5, 6, 7)
max(*args)
结果为10。
# 总结 就是 偏函数 其实就是把原本参数很多的函数简化参数,便于使用
#当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单
模块
# -*- coding: utf-8 -*-
'test module'
__author__ = 'Frank Li'
import sys
def test():
args=sys.argv
if len(args)==1:
print('hello world!')
elif len(args)==2:
print('hello {}'.format(args[1]))
else:
print('to many args!')
if __name__ == '__main__':
test()
模块搜索路径
默认情况下,Python解释器会搜索当前目录、所有已安装的内置模块和第三方模块,搜索路径存放在sys模块的path变量中:
>>> import sys
>>> sys.path
['', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python36.zip', '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6', ..., '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages']
如果我们要添加自己的搜索目录,有两种方法:
一是直接修改sys.path,添加要搜索的目录:
>>> import sys
>>> sys.path.append('/Users/michael/my_py_scripts')
这种方法是在运行时修改,运行结束后失效。
第二种方法是设置环境变量PYTHONPATH,该环境变量的内容会被自动添加到模块搜索路径中。设置方式与设置Path环境变量类似。注意只需要添加你自己的搜索路径,Python自己本身的搜索路径不受影响。
面向对象
>>> class Test(object):
... def __init__(self,*args):
... self.name,self.age=args[0],args[1]
...
>>> t = Test('frank',18)
>>> t
<__main__.Test object at 0x02F00AB0>
>>> t.name
'frank'
>>> t.age
18
再进一阶
>>> class Person(object):
... def __init__(self,name,age,*args,**kw):
... self.name,self.age = name,age
... for arg in args:
... print('arg: {}'.format(arg))
... for key in kw:
... print('key: {}--> value: {}'.format(key,kw[key]))
...
>>> args=('a',1,2,'b')
>>> kw ={'city':'changsha','job':'developer'}
>>> Person('frank',18,*args,**kw)
arg: a
arg: 1
arg: 2
arg: b
key: city--> value: changsha
key: job--> value: developer
<__main__.Person object at 0x02F00DD0>
>>> class Student(object):
... def __init__(self,name,score,*args,**kw):
... self.name,self.score = name,score
... for arg in args:
... print('arg: {}'.format(arg))
... for key in kw:
... if key=='city':
... self.city =kw[key]
... elif key=='job':
... self.job=kw[key]
... else:
... pring('key: {} --> value: {}'.format(key,kw[key]))
... def get_grade(self):
... if self.score >= 90:
... return '优'
... if 70<self.score<90:
... return '良'
... elif 60<self.score<=70:
... return '几个'
... else:
... return '不及格'
>>> student = Student('frank',80,*args,**kw)
arg: a
arg: 1
arg: 2
arg: 3
arg: c
arg: d
>>> student.city
'changsha'
>>> student.get_grade()
'良'
>>>
区别于 java 这种静态语言 , python 是动态语言
小结
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;
方法就是与实例绑定的函数,和普通函数不同,方法可以直接访问实例的数据;
通过在实例上调用方法,我们就直接操作了对象内部的数据,但无需知道方法内部的实现细节。
和静态语言不同,Python允许对实例变量绑定任何数据,也就是说,对于两个实例变量,虽然它们都是同一个类的不同实例,但拥有的变量名称都可能不同:
>>> bart = Student('Bart Simpson', 59)
>>> lisa = Student('Lisa Simpson', 87)
>>> bart.age = 8
>>> bart.age
8
>>> lisa.age
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Student' object has no attribute 'age'
访问权限控制
此方法不推荐, 应该用 set_gender() 而不是 bart._Student__gender 这种方式修改 gender 属性
>>> class Student(object):
... def __init__(self,name,gender):
... self.name=name
... self.__gender=gender
... def get_gender(self):
... return self.__gender
...
>>> bart = Student('Bart', 'male')
>>> if bart.get_gender() != 'male':
... print('测试失败!')
... else:
... bart._Student__gender='female'
... if bart.get_gender() != 'female':
... print('测试失败!')
... else:
... print('测试成功!')
...
测试成功!
正确做法:
>>> class Student(object):
... def __init__(self,name,gender):
... self.name,self.__gender=name,gender
... def set_gender(self,gender):
... self.__gender = gender
... def get_gender(self):
... return self.__gender
# 测试
>>> bart = Student('Bart','male')
>>> if bart.get_gender() != 'male':
... print('测试失败~!')
... else:
... bart.set_gender('female')
... if bart.get_gender() != 'female':
... print('测试失败!')
... else:
... print('测试成功~!')
...
测试成功~!
以为是多态,然而是多态,更不止是多态, 只要有 run 方法的 对象 都可以 往里丢 ,这一点注意区分 java 的 接口以及父类
>>> class Animal(object):
... def run(self):
... print('animal is running...')
...
>>> class Dog(Animal):
... def run(self):
... print('dog is running...')
...
>>> def run_twice(animal):
... animal.run()
... animal.run()
...
>>> run_twice(Animal())
animal is running...
animal is running...
>>> run_twice(Dog())
dog is running...
dog is running...
# 逝者如斯,东流不回 ,水不继承自 Animal 类 依旧可以 往 run_twice 这个方法里丢, 在 java 里是编译错误!!!
>>> class water(object):
... def run(self):
... print('water is running....and never back...')
...
>>> run_twice(water())
water is running....and never back...
water is running....and never back...
类型判断 type vs isinstance ==》 isinstance 胜 !!! 总是优先使用 isinstance 判断
>>> type(123) == int
True
>>> isinstance(123,int)
True
下面这种判断太过于复杂
判断基本数据类型可以直接写int,str等,但如果要判断一个对象是否是函数怎么办?可以使用types模块中定义的常量:
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True
并且还可以判断一个变量是否是某些类型中的一种,比如下面的代码就可以判断是否是list或者tuple:
>>> isinstance([1, 2, 3], (list, tuple))
True
>>> isinstance((1, 2, 3), (list, tuple))
True
总是优先使用isinstance()判断类型,可以将指定类型及其子类“一网打尽”。
# dir 查看,然后等价
>>> len('ABC') 3 >>> dir('ABC') ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
# 创建自己的 len 方法, 自己写一个 __len__() 方法就是了
>>> class myStr():
... def __init__(self,val):
... self.__val = val
... def __len__(self):
... return len(self.__val)
...
>>> myStr('abc')
<__main__.myStr object at 0x02F363D0>
>>> len(myStr('abc'))
3
>>>
# 查看 python 内建函数
>>> dir(__builtins__)
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '_', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
# 查看一波
>>> 'hasattr' in dir(__builtins__)
True
>>> 'getattr' in dir(__builtins__)
True
>>>
小结
通过内置的一系列函数,我们可以对任意一个Python对象进行剖析,拿到其内部的数据。要注意的是,只有在不知道对象信息的时候,我们才会去获取对象信息。如果可以直接写:
sum = obj.x + obj.y
就不要写:
sum = getattr(obj, 'x') + getattr(obj, 'y')
一个正确的用法的例子如下:
def readImage(fp):
if hasattr(fp, 'read'):
return readData(fp)
return None
假设我们希望从文件流fp中读取图像,我们首先要判断该fp对象是否存在read方法,如果存在,则该对象是一个流,如果不存在,则无法读取。hasattr()就派上了用场。
请注意,在Python这类动态语言中,根据鸭子类型,有read()方法,不代表该fp对象就是一个文件流,它也可能是网络流,也可能是内存中的一个字节流,但只要read()方法返回的是有效的图像数据,就不影响读取图像的功能。
getter setter
>>> class Student(object):
... def __init__(self,name,*args,**kw):
... self.__name = name
... for arg in args:
... print('arg: {}'.format(arg))
... for key in kw:
... if key == 'city':
... print('city %s' %kw[key])
... @property
... def score(self):
... return self._score
... @score.setter
... def score(self,value):
... self._score = value
...
>>> s = Student()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: __init__() missing 1 required positional argument: 'name'
>>> s = Student('frank',*(1,2,'a',3),**{'city':'changsha','job':'unknown'})
arg: 1
arg: 2
arg: a
arg: 3
city changsha
>>> s.score = 80
>>> s.score
80
>>> class Screen(object):
... @property
... def width(self):
... return self._width
... @width.setter
... def width(self,width):
... self._width = width
... @property
... def height(self):
... return self._height
... @height.setter
... def height(self,height):
... self._height = height
... @property
... def resolution(self):
... self._resolution = self._width * self._height
... return self._resolution
...
>>> s = Screen()
>>> s.width = 600
>>> s.height = 800
>>> s.resolution
480000
记住标准写法就好,别追问,会晕!!!
>>> class Student(object):
... def __init__(self,name,score,*args,**kw):
... self._name = name
... self._score = score
... if len(args)!=0:
... self.arg = args[0]
... for key in kw:
... if key == 'city':
... self.city = kw[key]
... @property
... def name(self):
... return self._name
... @name.setter
... def name(self,name):
... self._name = name
... @property
... def score(self):
... return self._score
... @score.setter
... def score(self,score):
... self._score = score
...
>>> args=('a',1,2)
>>> kw = {'city':'changsha','job':'unknown'}
>>> s = Student('frank',100,*args,**kw)
>>> s.name
'frank'
>>> s.score
100
>>> s.city
'changsha'
>>> s.arg
'a'
>>> class Student(object):
... def __init__(self,name,age,score,*args,**kw):
... self._name=name
... self._age = age
... self._score = score
... if len(args)!=0:
... self.arg = args[0]
... for key in kw:
... if key == 'city':
... self.city = kw[key]
... @property
... def name(self):
... return self._name
... @name.setter
... def name(self,name):
... self._name = name
... @property
... def age(self):
... return self._age
... @age.setter
... def age(self,age):
... if not isinstance(age,int):
... raise TypeError('年龄必须为整数!')
... else:
... self._age = age
... @property
... def score(self):
... return self._score
... @score.setter
... def score(self,score):
... if not isinstance(score,int):
... raise TypeError('分数应该为整数!')
... elif not 0<= score <= 100:
... raise ValueError('分数必须介于0-100之间!')
... else:
... self._score = score
...
>>> s = Student('frank',18,100)
>>> s.name
'frank'
>>> s.age
18
>>> s.score
100
多继承 ,对应 java extends class implements Runnable 这种写法, 只是 python 木有 接口一说 貌似,我也不确定哈,自己去查查吧
>>> class Animal():
... pass
...
>>> Animal()
<__main__.Animal object at 0x008DCF30>
>>> class Mammal(Animal):
... pass
...
>>> class Runnable(object):
... def run(self):
... print('running......')
...
>>> class Flyable(object):
... def fly(self):
... print('flying......')
...
>>> class Dog(Mammal,Runnable):
... pass
...
>>> d = Dog()
>>> d.run()
running......
>>> class Bat(Mammal,Flyable):
... pass
...
...
>>> b = Bat()
>>> b.fly()
flying......
定制类
# __slot__ 固定 self 属性个数
# __str__ 区别 于 __repr__ 前一个 是 返回给 用户的 , 第二个 是 返回给 程序员 用来调试的
>>> class Student(object):
... def __init__(self,name):
... self.name = name
... def __str__(self):
... return 'Student object (name = {})'.format(self.name)
... __repr__ = __str__
...
>>> s = Student('frank')
>>> s
Student object (name = frank)
枚举类
>>> from enum import Enum
>>> Month = Enum('Month',('Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'))
>>> for name,member in Month.__members__.items():
... print(name, '=>', member, ',', member.value)
...
Jan => Month.Jan , 1
Feb => Month.Feb , 2
Mar => Month.Mar , 3
Apr => Month.Apr , 4
May => Month.May , 5
Jun => Month.Jun , 6
Jul => Month.Jul , 7
Aug => Month.Aug , 8
Sep => Month.Sep , 9
Oct => Month.Oct , 10
Nov => Month.Nov , 11
Dec => Month.Dec , 12
>>> from enum import Enum,unique
>>> @unique
... class Weekday(Enum):
... Sun=0
... Mon=1
... Tue=2
... Wed=3
... Thu=4
... Fri=5
... Sat =6
...
>>> day1 = Weekday.Sun
>>> day1
<Weekday.Sun: 0>
>>> day1.value
0
>>> day1 = Weekday(0)
>>> day1
<Weekday.Sun: 0>
>>> day1.value
0
>>> for name,member in Weekday.__members__.items():
... print(name,'==>',member)
...
Sun ==> Weekday.Sun
Mon ==> Weekday.Mon
Tue ==> Weekday.Tue
Wed ==> Weekday.Wed
Thu ==> Weekday.Thu
Fri ==> Weekday.Fri
Sat ==> Weekday.Sat
枚举类与错误综合小例子
>>> class Student(object):
... def __init__(self,name,gender):
... if not isinstance(gender,Gender):
... raise TypeError('{}'.format('传入的性别类型异常'))
... self.__name = name
... self.gender = gender
...
>>> bart = Student('Bart', Gender.Male)
>>> if bart.gender == Gender.Male:
... print('测试通过!')
... else:
... print('测试失败!')
...
测试通过!
>>> bart = Student('Bart', '男')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 4, in __init__
TypeError: 传入的性别类型异常
>>>
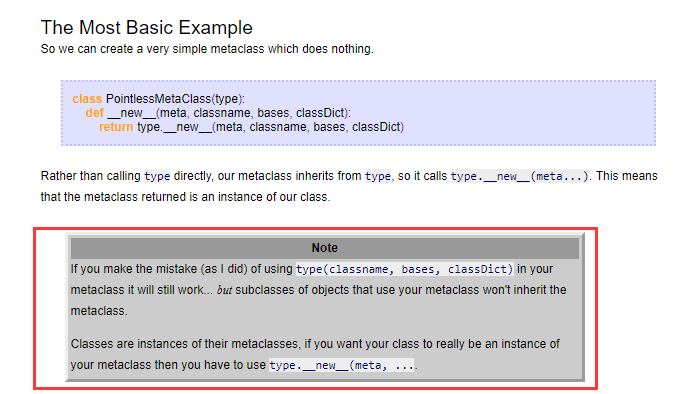
元类,我服了!!!
>>> def fn(self,world = 'world!'):
... print('hello {}'.format(world))
...
>>> Hello = type('Hello',(object,),dict(hello = fn))
>>> h = Hello()
>>> h.hello()
hello world!
>>> class ListMetaclass(type):
... def __new__(cls,name,bases,attrs):
... attrs['add']=lambda self,value:self.append(value)
... return type.__new__(cls,name,bases,attrs)
...
>>> class MyList(list,metaclass=ListMetaclass):
... pass
...
>>> l = MyList()
>>> l.add(5)
>>> l
[5]
# 类是一种特殊的对象,因为python 是动态语言,可以后期绑定属性方法等
>>> class ObjectCreator():
... pass
...
>>> print(ObjectCreator)
<class '__main__.ObjectCreator'>
>>> print(hasattr(ObjectCreator,'new_attribute'))
False
>>> ObjectCreator.new_attribute = 'foo'
>>> print(hasattr(ObjectCreator,'new_attribute'))
True
>>> ObjectCreatorMirror = ObjectCreator
>>> print(ObjectCreatorMirror())
<__main__.ObjectCreator object at 0x00859A30>
异常处理
>>> def div(a,b):
... if not isinstance(a,int) or not isinstance(b,int):
... raise TypeError('本方法中除数与被除数都要为整数!')
... try:
... r = a/b
... print('r: {}'.format(r))
... except ZeroDivisionError as e:
... print('except: ',e)
... finally:
... print('finally...')
... print('END...')
>>> r = div(1,2)
r: 0.5
finally...
END...
>>> div(1,0)
except: division by zero
finally...
END...
>>> def foo(i):
... return 10/i
...
>>> def bar(j):
... return foo(j) *2
>>> def main(n):
... try:
... bar(n)
... except ZeroDivisionError as e:
... logging.exception(e)
... finally:
... print('end...')
...
>>> main(5)
end...
>>> main(0)
ERROR:root:division by zero
Traceback (most recent call last):
File "<stdin>", line 3, in main
File "<stdin>", line 2, in bar
File "<stdin>", line 2, in foo
ZeroDivisionError: division by zero
end...
改错:
from functools import reduce
def str2num(s):
try:
r = int(s)
except ValueError as e:
if isinstance(s,str):
s=s.replace('.','')
r = int(s)
else:
raise ValueError('传入的不是字符串!')
finally:
pass
return int(s)
def calc(exp):
ss = exp.split('+')
ns = map(str2num, ss)
return reduce(lambda acc, x: acc + x, ns)
def main():
r = calc('100 + 200 + 345')
print('100 + 200 + 345 =', r)
r = calc('99 + 88 + 7.6')
print('99 + 88 + 7.6 =', r)
main()
既然如此重要,再谈元类
# 定义一个函数,用来待会儿在 类 内部或绑定,或调用
def print_s(s):
print(s)
# 定义元类, 必须继承自 type 才可以被当做元类,被反射
class ObjectCreatorMetaClass(type):
def __new__(current_class_name,class_tobe_created_name,base_classess_name_tuple,attrs_hold_dict):
# 打印一波传进来的参数会发现基本跟命名一致
print_s('current_class_name: {}'.format(current_class_name))
print_s('class_tobe_created_name: {}'.format(class_tobe_created_name))
print_s('base_classess_name_tuple: {}'.format(base_classess_name_tuple))
print_s('attrs_hold_dict: {}'.format(attrs_hold_dict))
#为要被创建的类 ObjectCreator 添加方法,属性都可以
attrs_hold_dict['flag'] = True
attrs_hold_dict['current_class_name_print'] = print_s(current_class_name)
attrs_hold_dict['class_tobe_created_name_print'] = print_s(class_tobe_created_name)
attrs_hold_dict['base_classess_name_tuple_print'] = print_s(base_classess_name_tuple)
attrs_hold_dict['attrs_hold_dict_print'] = print_s(attrs_hold_dict)
return type.__new__(current_class_name,class_tobe_created_name,base_classess_name_tuple,attrs_hold_dict)
# 定义我们要被创建的 类,为了方便查看传进去的 base_classess_name_tuple ,我们手动让他继承一下 object
class ObjectCreator(object,metaclass = ObjectCreatorMetaClass):
pass
# 思考为什么 第一次打印时候 attrs_hold_dict 会比后一次 打印 少掉一部分属性,方法 (如 'current_class_name_print': None, 'flag': True)
# 因为这在传进来时候并没有绑定这些参数方法啊,是后面代码 手动绑定的啦 哈哈哈哈或或或
# 上面的理解有点偏差,但愿看到的人能够自己找出,下面是我重新理解的
# 定义一个函数,用来待会儿在 类 内部或绑定,或调用
def print_s(s):
print(s)
return s
#必须继承自 type 才可以被当做元类,被反射
class ObjectCreatorMetaClass(type):
def __new__(current_class_name,class_tobe_created_name,base_classess_name_tuple,attrs_hold_dict):
# 打印一波传进来的参数会发现基本跟命名一致
print_s('current_class_name: {}'.format(current_class_name))
print_s('class_tobe_created_name: {}'.format(class_tobe_created_name))
print_s('base_classess_name_tuple: {}'.format(base_classess_name_tuple))
print_s('attrs_hold_dict: {}'.format(attrs_hold_dict))
#为要被创建的类 ObjectCreator 添加方法,属性都可以
attrs_hold_dict['flag'] = True
attrs_hold_dict['get_metaclass'] = print_s(current_class_name)
attrs_hold_dict['get_tobe_created_class'] = print_s(class_tobe_created_name)
attrs_hold_dict['get_bases_classess_tuple'] = print_s(base_classess_name_tuple)
attrs_hold_dict['get_attrs_hold_dict'] = print_s(attrs_hold_dict)
return type.__new__(current_class_name,class_tobe_created_name,base_classess_name_tuple,attrs_hold_dict)
class ObjectCreator(object,metaclass = ObjectCreatorMetaClass):
pass
# 思考为什么 第一次打印时候 attrs_hold_dict 会比后一次 打印 少掉一部分属性,方法 (如 'current_class_name_print': None, 'flag': True)
# 因为这在传进来时候并没有绑定这些参数方法啊,是后面代码 手动绑定的啦 哈哈哈哈或或或
object_from_objectcreator = ObjectCreator()
print(object_from_objectcreator.flag)
# 实际上这里返回了
object_from_objectcreator.get_metaclass
object_from_objectcreator.get_tobe_created_class
object_from_objectcreator.get_bases_classess_tuple
object_from_objectcreator.get_attrs_hold_dict
# out:
# current_class_name: <class '__main__.ObjectCreatorMetaClass'>
# class_tobe_created_name: ObjectCreator
# base_classess_name_tuple: (<class 'object'>,)
# attrs_hold_dict: {'__qualname__': 'ObjectCreator', '__module__': '__main__'}
# <class '__main__.ObjectCreatorMetaClass'>
# ObjectCreator
# (<class 'object'>,)
# {'get_bases_classess_tuple': (<class 'object'>,), '__qualname__': 'ObjectCreator', 'get_metaclass': <class '__main__.ObjectCreatorMetaClass'>, '__module__': '__main__', 'get_tobe_created_class': 'ObjectCreator', 'flag': True}
# True
# {'__module__': '__main__',
# '__qualname__': 'ObjectCreator',
# 'flag': True,
# 'get_attrs_hold_dict': {...},
# 'get_bases_classess_tuple': (object,),
# 'get_metaclass': __main__.ObjectCreatorMetaClass,
# 'get_tobe_created_class': 'ObjectCreator'}
# 到目前为止,我认为元类来创建 类 ,然后 类再创建对象的过程
# 应该是 定义一个元类继承 type 这个 class 然后 覆写它的 __new__ 方法, TBD。。。
# 曾经沧海,写完下面这个自动转换要被创建的类的属性为大写 , 元类也就会了
class Upper_attr(type):
def __new__(cls,name,bases,attr_dict):
attr_dict = dict( (name.upper(),value) for name,value in attr_dict.items() if not name.startswith('__'))
print(attr_dict)
return super(Upper_attr,cls).__new__(cls,name,bases,attr_dict)
class Foo(object,metaclass = Upper_attr):
bar = 'bip'
pass
hasattr(Foo,'BAR')
{'BAR': 'bip'}
True
# 思考为什么 构造函数 __init__ 不能用 lambda 来写函数体 , 因为,lambda 冒号后边必须接的是一个 表达式而非语句
def __init__(self, x):
self.x = x
def printX(self):
print(self.x)
Test = type('Test', (object,), {'__init__': __init__, 'printX': printX})
class TestMetaclass(type):
def __new__(cls,name,bases,attr_dict):
attr_dict['__init__'] = __init__
attr_dict['printX']= lambda self:print(self.x)
return super(TestMetaclass,cls).__new__(cls,name,bases,attr_dict)
class Test(object,metaclass = TestMetaclass):
pass
Test('123').printX()
IO , 文件 , 内存, 字符,字节 类似于 java 的 IO
import os
file_list = os.listdir('.')
for file in file_list:
file_name,file_extension = os.path.splitext(file)
if file_extension == '.csv':
try:
f = open(file,'r')
print(f.read())
print('file name: ',file_name+file_extension)
except IOError as ioe:
print(e)
finally:
if f:
f.close()
print(file_name,'<----->',file_extension)
gender,age,drug,complication
0,1,3,5
1,3,2,3
0,5,1,2
0,2,3,3
1,7,3,2
0,6,3,4
file name: mock_data.csv
mock_data <-----> .csv
加上 编码,解码方式
file_list = os.listdir('.')
kw = {'encoding':'utf8'}
for file in file_list:
file_name,file_extension = os.path.splitext(file)
if file_extension == '.csv':
try:
f = open(file,'r',**kw)
print(f.read())
print('file name: ',file_name+file_extension)
except IOError as ioe:
print(e)
finally:
if f:
f.close()
print(file_name,'<----->',file_extension)
file_list = os.listdir('.')
kw = {'encoding':'utf8'}
for file in file_list:
file_name,file_extension = os.path.splitext(file)
if file_extension == '.csv':
try:
f = open(file,'r',**kw)
# print(f.read())
for line in f.readlines():
print(line)
print('file name: ',file_name+file_extension)
except IOError as ioe:
print(e)
finally:
if f:
f.close()
print(file_name,'<----->',file_extension)
# 使用 with 表达式,相当于 java 中的 try(Autoclosable Resources) 语法糖,自动关闭资源
file_list = os.listdir('.')
kw = {'encoding':'utf8','errors':'ignore'}
for file in file_list:
file_name,file_extension = os.path.splitext(file)
if file_extension == '.csv':
with open(file,'r',**kw) as f:
for line in f.readlines():
print(line.strip()) # 去掉末尾的换行符
print(file_name,'<----->',file_extension)
# 读写二进制文件 是不能加 errors 参数的
>>> with open('9.jpg','rb',errors='ignore') as fr:
... with open('99.jpg','wb') as fw:
... for line in fr.readlines():
... fw.write(line)
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: binary mode doesn't take an errors argument
# StringIO , python 3 中 是 from io import StringIO ,内存读写
# 方式一:
f = StringIO()
f.write('Hello
World!
')
print(f.getvalue())
# 方式二:
from io import StringIO
f = StringIO('Hello
World!
')
# print(f.getvalue())
while True:
s = f.readline()
if s == '':
break
print(s.strip())
# StringIO操作的只能是str,如果要操作二进制数据,就需要使用BytesIO。
# BytesIO实现了在内存中读写bytes,我们创建一个BytesIO,然后写入一些bytes:
from io import BytesIO
f = BytesIO()
f.write('中文'.encode('utf-8'))
print(f.getvalue())
结果:
b'xe4xb8xadxe6x96x87'
# 解码:
from io import BytesIO
f = BytesIO(b'xe4xb8xadxe6x96x87')
bcontent = f.read()
print(bcontent.decode('utf-8'))
与上一种utf-8 编码相反,用 utf-8 解码, 结果如下:
'中文'
文件夹目录以及文件相关操作
# 在当前路径下查找包含指定字符串的 所有文件名,并返回。如果是子目录,需要用到递归,没有写,有空写写
import os
def search_file(filename):
return [file for file in os.listdir('.') if os.path.isfile(file) and filename in file]
for name in search_file('并'):
print(name)
并发症逻辑回归准确率.ipynb
并发症概率模型.ipynb
# api 集中:
os.path.isdir(x)
os.listdir('.')
os.path.isfile(x)
os.path.splitext(x)[1]=='.py'
os.name # 操作系统类型 nt
os.uname() # 注意uname()函数在Windows上不提供,也就是说,os模块的某些函数是跟操作系统相关的。
os.environ # 在操作系统中定义的环境变量,全部保存在os.environ这个变量中,可以直接查看:
os.environ.get('PATH')
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')
'/Users/michael'
# 在某个目录下创建一个新目录,首先把新目录的完整路径表示出来:
>>> os.path.join('/Users/michael', 'testdir')
'/Users/michael/testdir'
# 然后创建一个目录:
>>> os.mkdir('/Users/michael/testdir')
# 删掉一个目录:
>>> os.rmdir('/Users/michael/testdir')
# 对文件重命名:
>>> os.rename('test.txt', 'test.py')
# 删掉文件:
>>> os.remove('test.py')
>>> os.path.split('/Users/michael/testdir/file.txt')
('/Users/michael/testdir', 'file.txt')
但是复制文件的函数居然在os模块中不存在!原因是复制文件并非由操作系统提供的系统调用。理论上讲,我们通过上一节的读写文件可以完成文件复制,只不过要多写很多代码。
幸运的是shutil模块提供了copyfile()的函数,你还可以在shutil模块中找到很多实用函数,它们可以看做是os模块的补充。
序列化 (内存流向磁盘的过程)与 反序列化(磁盘流向内存的过程)
# 序列化
import pickle
person = {'name':'Bob','age':18,'gender':'Male'}
d = pickle.dumps(person)
with open('dump.txt','wb') as fw:
pickle.dump(d,fw)
# 反序列化
with open('dump.txt','rb') as fr:
d=pickle.load(fr)
print(d)
序列化为json 串存储到磁盘, 反序列化从磁盘读取 json 串到内存转化为python对象
import json
person = dict(name = 'Tom',age = 18,gender='Male')
# dumps 将dict 转成 json 字符串
j = json.dumps(person)
with open('json.txt','w') as fw:
# dump 序列化 json 串为文件或类文件对象 (file-like Object)
json.dump(j,fw)
# loads 方法将 json串反序列化
json.loads(j)
with open('json.txt','r') as fr:
# load 方法将从文件中读取字符串并反序列化为json 串,同时你会发现是反序的
k = json.load(fr)
print(k)
再进一阶,序列化与反序列化 json 串 between 对象
import json
class Student(object):
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
s = Student('Tom',18,'Male')
def student2str(std):
return dict(name=std.name,age=std.age,sex=std.sex)
json.dumps(student2str(s))
json.dumps(s,default=lambda obj:obj.__dict__)
'{"sex": "Male", "age": 18, "name": "Tom"}'
#将上面的 json 字符串转换为 Student 对象
json_str = '{"sex": "Male", "age": 18, "name": "Tom"}'
def dict2student(d):
return Student(d['name'],d['age'],d['sex'])
s = json.loads(json_str,object_hook=dict2student)
s.name
结果:
'Tom'
小结
Python语言特定的序列化模块是pickle,但如果要把序列化搞得更通用、更符合Web标准,就可以使用json模块。
json模块的dumps()和loads()函数是定义得非常好的接口的典范。当我们使用时,只需要传入一个必须的参数。但是,当默认的序列化或反序列机制不满足我们的要求时,我们#### 又可以传入更多的参数来定制序列化或反序列化的规则,既做到了接口简单易用,又做到了充分的扩展性和灵活性。
内建模块以及常用第三方模块
import urllib.request as urllib2
import random
ua_list=["Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"]
u_agent = random.choice(ua_list)
# print(u_agent)
url = 'http://www.baidu.com'
request = urllib2.Request(url=url)
request.add_header("User_agent",u_agent)
response = urllib2.urlopen(request)
print(response.read())
其他
标准数据类型
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表)
Tuple(元组)
Sets(集合)
Dictionary(字典)
Python3 的六个标准数据类型中:
不可变数据(四个):Number(数字)、String(字符串)、Tuple(元组)、Sets(集合);
可变数据(两个):List(列表)、Dictionary(字典)。
Set(集合)
集合(set)是一个无序不重复元素的序列。
基本功能是进行成员关系测试和删除重复元素。
# 字符串的一些内建函数需要掌握 ,首字母大写 capitalize(),lower(),upper() 等等
a = 'frank'
a.capitalize()
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a和b的差集
print(a | b) # a和b的并集
print(a & b) # a和b的交集
print(a ^ b) # a和b中不同时存在的元素
dict_1 = dict(name='frank',age=18) # 这写法我喜欢
dict_1 = {'name':'frank','age':18} # 这写法也能接受
dict_1 = dict([('name','frank'),('age',18)]) # 这种写法我觉得纯粹是有病。。。
删除引用,估算引用,查询引用
del b
eval('b')
hex(id(b)) # 16 进制 hash值
# str()出来的值是给人看的。。。repr()出来的值是给python看的,可以通过eval()重新变回一个Python对象
a = 'a'
eval('a')
hex(id(a))
eval(repr(a))
# print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
# 不换行输出
print( x, end=" " )
print( y, end=" " )
dict items() , keys(), values()
list pop , append
import keyword
keyword.kwlist
# dict 是个好命令
dir(dict)
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'clear',
'copy',
'fromkeys',

python 日志
# 这段代码保存为 config.py
# -*- coding: utf-8 -*-
__author__ = 'Frank Li'
import logging
class Config():
# 创建一个logger
logger = logging.getLogger('statisticNew')
logger.setLevel(logging.DEBUG)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler('test.log')
fh.setLevel(logging.DEBUG)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
# 定义handler的输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
def getLog(self):
return self.logger
引用上段代码保存的额 config.py 文件里的module
__author__ = 'Frank Li'
from config import Config
if __name__ == '__main__':
conf = Config()
logger = conf.getLog()
logger.info('foorbar')
boy = "Frank Li"
is_handsome = True
logger.info("boy=%s,is_handsome=%s",boy,is_handsome)
# 异常处理,以后尽量不要用山寨的 print 了
try:
....
except Exception as e:
logger.exception('ERROR readFile:%s,%s' % (path,str(e)))
编码规范 , 变量定义
# Python变量命名用法(一般变量、常量、私有变量、内置变量)
#coding:utf8
__author__ = "libingxian"
class TestDemo(object):
"""
Python变量命名用法(以字符或者下划线开头,可以包括字母、数字、下划线,区别大小写)
一般变量
常量
私有变量
内置变量
"""
FINAL_VAR = "V1.0" # 常量,不可修改的变量,以大写字母或加下划线命名,这个只是约定,即使更改了也不会报错
class_name = "TestDemo" # 常见变量命名,
__maker__ = 'libingxian' # 内置变量,两个前置下划线和两个后置下划线,内置对象所具有,声明时不可与内置变量名的重复
def __init__(self):
self.__private_var = "private" # 私有变量,以两个前置下划线开头,只能在本类中使用,类外强制访问会报错
self.public_var = "public" # 一般变量
def __private_method(self):# 私有方法,以两个下划线开头、字母小写,只能在本类中使用,类外强制访问会报错
print "i am private"
def public_method(self):
print "i am public"
test_demo = TestDemo()
print test_demo.FINAL_VAR # 访问常量
print test_demo.public_var # 访问一般变量
print test_demo.__private_var # 访问私有变量,运行会报错
test_demo.__private_method() # 访问私有方法,运行会报错
字典操作 dict_1.update(dict_2) 合并 dict
dict_1 = {'name':'Frank','age':18}
gender_dict = {'gender':'Male'}
dict_1.update(gender_dict)
print(dict_1)
字典推导式
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {
k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0)
for k in mcase.keys()
}
# mcase_frequency == {'a': 17, 'z': 3, 'b': 34}
# key,value 交换
>>> {value:key for key,value in dict_1.items()}
{'Frank': 'name', 18: 'age'}
由 两个 list 合并 dict 原理是利用 zip 合并成 ((key1,value1),(key2,value2)) 然后用 dict[key] = value 方式
list_1 = ['name','age']
list_2 = ['Frank',18]
person_dict = {}
for key,value in zip(list_1,list_2):
person_dict[key] = value
print(person_dict)
# 反过来 zip(*zipped) ==> flattern
dict_2 = dict(name='Frank',age=18)
list_3,list_4 = zip(*[ [key,value] for key,value in dict_2.items()])
list_3,list_4
list 去重
# 方法一
l1 = ['b','c','d','b','c','a','a']
l2 = {}.fromkeys(l1).keys()
print(l2)
# 方法二
l3 = list(set(l1))
# 方法三
>>> a=[1,2,4,2,4,5,7,10,5,5,7,8,9,0,3]
>>> a.sort()
>>> a
[0, 1, 2, 2, 3, 4, 4, 5, 5, 5, 7, 7, 8, 9, 10]
>>> last = a[-1]
>>> for i in range(len(a)-2,-1,-1):
... if last == a[i]:
... del a[i]
... else:
... last = a[i]
...
>>> a
[0, 1, 2, 3, 4, 5, 7, 8, 9, 10]
# 封装成方法 distinct
>>> def distinct(lst):
... lst.sort()
... last = lst[-1] # 这里不正向的原因是lst长度会改变
... for i in range(len(lst)-2,-1,-1): # 倒序来比较列表
... if last == lst[i]:
... del lst[i] # 如果与已经有的值相同则删除
... else: # 否则则将 last 指向前一个元素
... last = lst[i]
... return lst
distinct([1,2,4,2,4,5,7,10,5,5,7,8,9,0,3])
# 三元运算 还可以用 元组条件表达式的三元运算 is_fat =('not fat','fat') [is_state]
>>> is_state = True
>>> is_fat = 'fat' if is_state else 'not fat'
>>> is_fat
'fat'
# 优雅地查出重复数据
>>> str_list = ['a','b','a','c','d','b','c']
>>> [s for s in str_list if str_list.count(s) >1]
['a', 'b', 'a', 'c', 'b', 'c']
>>> set([s for s in str_list if str_list.count(s) >1])
{'a', 'c', 'b'}
# 求交集 差集
>>> str_list2 = ['a','b']
>>> str_list = set([s for s in str_list if str_list.count(s) >1])
>>> str_list.intersection(str_list2)
{'a', 'b'}
>>> str_list.difference(str_list2)
{'c'}
列表排序
列表排序
a = [(1, 2), (4, 1), (9, 10), (13, -3)]
a.sort(key=lambda x: x[1])
print(a)
# Output: [(13, -3), (4, 1), (1, 2), (9, 10)]
列表并行排序
list_1 = [8,4,3,2,7,6,5]
list_2 = ['e','d','c','y','i','o','p']
data = zip(list_1,list_2)
data = sorted(data)
list1, list2 = map(lambda t: list(t), zip(*data))
print(list1)
print(list2)
模拟 with open
>>> class File(object):
... def __init__(self,file_name,method):
... self.file_obj = open(file_name,method)
... def __enter__(self):
... return self.file_obj
... def __exit__(self,type,value,traceback):
... self.file_obj.close()
...
>>> with File('C:/Users/FrankLi/Desktop/Demo.java','r') as f:
... for line in f.readlines():
... print(line)
...
class Demo{
public static void main(String[] args){
System.out.println("Hello world!");
}
}
我们的__exit__函数接受三个参数。这些参数对于每个上下文管理器类中的__exit__方法都是必须的。我们来谈谈在底层都发生了什么。
with语句先暂存了File类的__exit__方法
然后它调用File类的__enter__方法
__enter__方法打开文件并返回给with语句
打开的文件句柄被传递给opened_file参数
我们使用.write()来写文件
with语句调用之前暂存的__exit__方法
__exit__方法关闭了文件
类似于 scala 的 flattern 列表展平
>>> import itertools
>>> a_list = [[1,2],[3,4],[5,6]]
>>> print(itertools.chain(*a_list))
<itertools.chain object at 0x039E6090>
>>> print(list(itertools.chain(*a_list)))
[1, 2, 3, 4, 5, 6]
>>> print(list(itertools.chain.from_iterable(a_list)))
[1, 2, 3, 4, 5, 6]
>>> l = [[1,2,3],[4,5,6], [7], [8,9]]
>>> [item for sublist in l for item in sublist] # 推导式中两层 for 循环也可以实现
[1, 2, 3, 4, 5, 6, 7, 8, 9]
for - else 结构
for n in range(2, 100):
for x in range(2, n):
if n % x == 0:
print(n, 'equals', x, '*', n / x)
break
else:
# loop fell through without finding a factor
print(n, 'is a prime number')
# 替代 switch case 方案 字典映射
>>> def switch(x):
... return {'0':0,'1':1,'2':2}.get(x,'nothing')
...
>>> switch('0')
0
>>> switch('3')
'nothing'
16.检查一个字符串是否是一个数字?
In[22]: x = '569789'
In[23]: x.isdigit()
Out[23]: True
In[24]: y = 'gdf2667'
In[25]: y.isdigit()
Out[25]: False
17.查找列表中某个元素的下标?
In[26]: ['a','b','c'].index('b')
Out[26]: 1
18.如何在列表中随机取一个元素?
import random
f= ['a', 'b', 'c']
print(random.choice(f))
# 字典排序
>>> dict_1 = {'a':3,'b':1,'c':2}
>>> sorted(dict_1.items(),key=lambda x:x[1])
[('b', 1), ('c', 2), ('a', 3)]
>>> import operator
>>> file_dict={"a":1,"b":2,"c":3}
>>> sorted(file_dict.items(),key = operator.itemgetter(1),reverse=True)
[('c', 3), ('b', 2), ('a', 1)]
# 字符串的不可变形 = immutability
Str1 = 'Yuxl'
print(Str1)
try:
Str1[0] = 'XX'
except:
print("不可更改")
Yuxl
不可更改
>>> import random
>>> def g_rand_range(max):
... for i in range(1,max+1,1):
... yield random.randint(1,10)
...
>>> for i in g_rand_range(10):
... print(i)
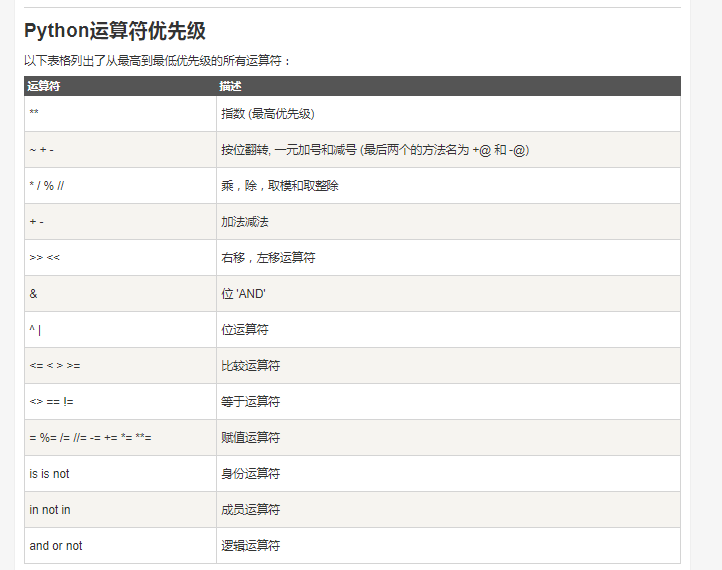
别人的总结图

JAVA vs PYTHON (还没细看)

总结:
至此,关于 python 基础的总结基本完结,其中有涉及到高阶知识 , 元类,位置参数关键字参数 可变参数(*args type: tuple,**kwargs type: dict),
生成器,装饰器,函数式编程风格的 map reduce filter sorted上下文管理器, 要补充的有 : 进程线程协程,异步io
接下来的时间应该是 学习 python 的重要常用模块(Pandas,Numpy,Scipy,PIL pillow , opencv,sk-learn,xgboost,爬虫库 scrappy等)以及框架(Django)
最后感慨一下,如果一开始碰到了python 也许根本就不会去学java了,感觉python的设计思想比较符合我的思想各种黑魔法的魅力吸引着我!!!
(虽然java不可否认也是一门优雅的工程化设计语言但不够精简,语法冗长)。。。life is short , I use python and java ! 其实语言本身没有好坏,
只有适用场景(多一门语言能力便多一种工具,而工具可以提高效率!),
每一门语言都有自己的设计思想,一个合格的程序员应该多学几门语言,了解怎样用不同的方法和思维去解决同一个问题。因此学习多门并不仅仅是为了更好的装逼!!!
我曾经还一直在想为什么没有出现一门语言一统天下呢 现在想想也是天真。。。
不过语言始终流于招式,接下来是要修炼一波内功了,算法才是灵魂!