概述
先搞点儿别人写好的现成解析来康康
这篇文章实现了一个transcompiler的模型,作用是将一种编程语言写出的代码翻译成另一种编程语言。其最大特点是不需要任何手工编写的规则,具有良好的泛化性能。
该模型是一个seq-2-seq的模型,具体来说是一个transfomer结构。训练过程分为initialization、denoising auto-encoding与back-translation。
模型训练所用的语料是从Github上扒下来的一些开源代码,抽取了其中C++、Java和Python的一些函数。值得注意的是,这些训练数据都是monolingual(单一语言)的,也就是说并没有对应的平行语料。
模型测试所用的语料来自GeeksforGeeks,它有一些Online Judge的题库,支持多种语言提交。这样就得到了测试所需的平行语料。
模型使用了三种评价指标:基于朴素匹配的reference match,NLP问题常用的BLEU,以及针对transcompile这一问题专门设计,基于单元测试的“computational accuracy”。实验表明,前两种指标都不能很好地评价模型在该问题上的表现。
该模型的表现高于作者选定的两个baseline,但并没有达到很好的效果。其中c++与java的互转准确率较高,而涉及到python的转换中,computational accuracy都低于50%,即只有不到一半的代码段能通过测试。
问题简介
一个transcompiler的作用是将一种编程语言写成的代码转换为另一种编程语言,并保持其原始功能不变。
它与传统compiler不同,是high-level to high-level的,中间不会经过低级语言(例如汇编语言、机器语言)的过渡。
transcompiler可以用于代码在不同平台间的迁移,或用于淘汰过时的编程语言。这些工作用人工来做都非常耗时。
transcompile乍一看与普通的翻译问题非常类似,但编程语言有一些与自然语言大不相同的特性,决定了它不能简单地套用机翻模型。例如,在自然语言中,偶尔的一个漏字或赘余并不会影响人的阅读,但对于编程语言来说可能是致命的。
早期的transcompiler多使用rule-based的方法,即根据每种编程语言的语法规则,对输入的语料建立抽象语法树(AST)。但不同的编程语言有不同的语法规则与依赖,编写这些规则是非常耗时耗力的工作。
后来人们考虑使用NMT模型,但面临的问题是缺少训练数据。有监督的机翻需要大量平行语料。而在编程语言这方面,合格的平行语料并不仅仅需要满足功能相同,还需要有相同的编码思路才能让模型学习到正确的对应规则。这样的语料非常稀少,限制了NMT模型在这一领域的表现。
所以该文章提出了TransCoder,一种完全基于单一语言语料库训练出的,无监督的transcompiler模型。
模型训练
pretrain
pretrain的作用主要是让模型能够将source code中语义相同的token嵌入到空间中相同或相近的向量。这样能够提取source code中的语义信息,而忽略掉表层的实现方式。
下图是pretrain效果的一个直观显示。
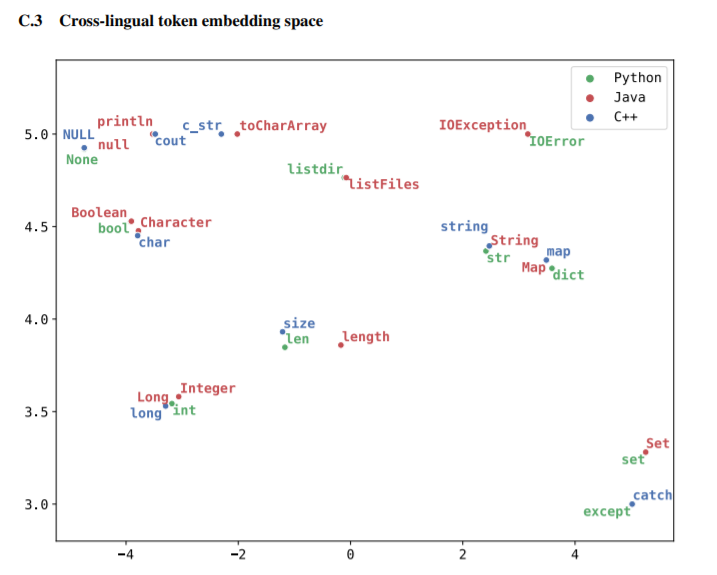
pretain的策略采用masked language model的方法。先在用于训练的数据上随机将一些token替换为MASK,随后让模型将这些MASK恢复为原来的token。通过训练时混合使用不同语言的数据,模型能够学习到不同的语言中一些相同的表示。
文章认为,这种pretrain过程之所以能发挥作用,依赖的是不同语言中一些具有明显含义的相同token,文中称为“anchor point”。在自然语言中,这些anchor point大多表现为数字、专有名词等。正因如此,对于一些较难产生anchor point的数据,这种训练方法的表现并不好。例如中英互译的语料,它们本身的字符集都不相同,模型难以找到anchor point。
然而这里选用的三种编程语言,c++、python和java,它们本身的保留关键字就有大量重合,非常容易找到大量anchor point。所以文章认为,这一pretrain策略会很自然地建立不同编程语言之间的联系。
下图直观描述了pretrain的过程。

Denoising auto-encoding
刚才的pretrain过程相当于对模型做了一个初始化,这个初始化过程是模仿XLM的训练策略来的。它能很好地fit模型的encoder部分,使模型有很好的语义抽取能力。但我们还希望模型的decoder能很好地把encoder得到的语义信息还原成目标语言的形式。
于是这里采用了denoising auto-encoding的训练方法。仍然是seq2seq的训练过程,但投入模型的训练数据被加入一些随机的噪声,例如mask掉一些token、移除一些token或打乱其顺序。模型需要输出正确的句子,即将输入中的噪声去掉。
例如在下图中,加入噪声后的code里面,第一行的变量名被删掉了,第二行最后少了一个数字1,第三行少了左括号和数字1,以及加入了一些MASK。模型需要将这些错误全部修正。

文中表示,这里在数据开头加了一个特殊的token,指定希望其输出的语言形式是python、cpp还是java,这样模型就能够完成不同语言之间的互转。
这个强调denoising的训练过程在这里确实是比较有意义的。因为编程语言的特性就是一个小差错(例如少了一个数字或字母)会很大地影响代码的实际功能。通过这一训练,模型生成的代码在语法上的准确性能够进一步提高,对输入噪音也比较robust。
Back-translation
理论上,前两个步骤已经足够让模型完成transcompiler的工作。但为了进一步提升效果,文中加入了back-translation过程。这是一种弱监督的训练方法。
它同时训练两个模型,一个source-to-target,一个target-to-source。其中tar-to-src模型接收target语言的句子作为输入,输出(可能有噪声的)source语言;而src-to-tar模型接受这些有噪声的source语言句子作为输入,输出正确的target语言。

实验设计
关于训练数据的一些细节
训练数据是从Github上扒下来的代码。需要注意的是训练的数据都是单一语言的,没有平行语料。
理想情况下它应该能够训练出program级别的transcompiler,但因为难度太大,这里只训练了function级别,即在程序中抽取一些函数用来训练。数据的量还是相当大的,三种语言的数据都到了百GB级别。
文章的附录中提到,这里将抽取出的函数分为了独立函数和类函数两种。独立函数就指那种不需要实例化就可以使用的函数,例如c++中定义在全局的函数,java中的static函数等。pretrain的时候使用了全部函数,但后续的训练过程只使用了独立函数。文章给出的理由是这样效果比较好(真是个有够直观的理由)。
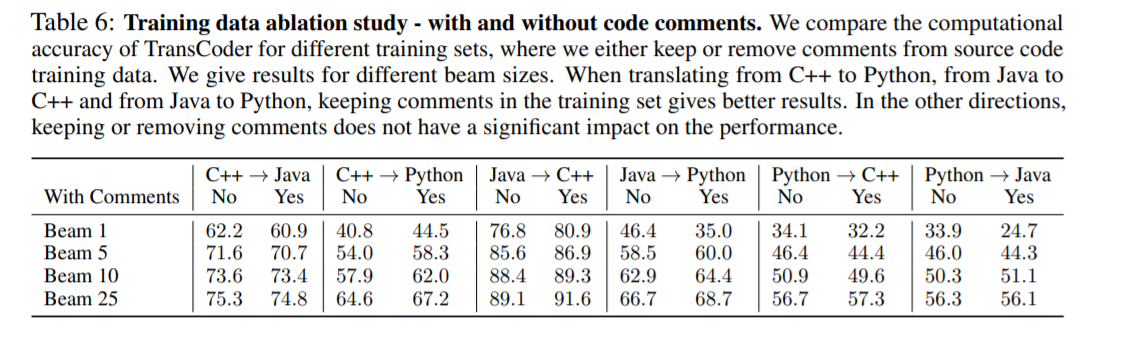
另外,在抽取数据的时候,函数中的一些comment也被保留了。文章给出的理由仍然是这样效果比较好(甚至还做了对比实验验证,在原文的附录C.2)
怎么说呢,我觉得这在理论上有点牵强。但人家的实验效果确实是保留comment要好一点点
在对raw data进行tokenize的时候,文中针对不同的编程语言使用了不同的tokenizer。因为不同的语言对很多字符的处理不一样,例如在c++中,多余的空格、缩进等等都是没有意义的,但在python中就一定要把缩进也tokenize,不然没有办法获得正确的语法结构。附录中也给了一个对python代码做tokenize的例子。

评价指标
文章使用了三种评价指标:BLEU、reference match,和computational accuracy。其中reference match是完全基于匹配的指标,BLEU是机器翻译中常用的指标,而computational accuracy是专门为此任务设计,基于单元测试来衡量两个代码段在功能上相似性的指标。
显然,第三个指标对于transcompiler来说是最根本的评价标准,毕竟翻译过来的程序首先要功能正确,其次再考虑美观性和可读性。而BLEU衡量了输出的句子与ground truth在形式上的相似度。
BLEU指标虽然比纯粹匹配的reference match要科学很多,但它无法很好地评判transcompiler的功能。原因在于,相同的功能可能有多样化的实现方法,而表面上相似的代码可能由于一个符号的差别而呈现迥然不同的效果。
针对beam search的对比实验
因为decoder最后生成句子的时候要用beam search,文章对于beam search的关键参数也做了一些对比。
beam search简单来说就是在搜索的时候,只扩展那些概率较大的节点,剩下的节点放弃(剪枝掉)。具体扩展多少节点由参数beam size决定。
本文的实验分别设置了不同的beam size(下文简称N)。另外,原本最后应该只生成一份结果(即最后一步在N个结果中选一个概率最大的),但文中也设计了这样的实验:最终的N个结果全部保留,只要有一个结果能通过单元测试,就算整体通过。期望通过这样的实验来衡量模型的生成能力(但我觉得好投机取巧啊orz)。
实验结果
贪心decoder,各个评价指标的对比
下面这些结果在beam search的时候把beam size设置成了1,也就是纯贪心地生成结果,每次取probability最大的那个。

可以发现reference match这个指标就很离谱,根本没法用
BLEU和computational accuracy还是有一丢丢相关性的(至少它们增降的趋势是一样的)
可以发现,这样生成的代码的BLEU值还是挺不错的,尤其是java和c++的互转,放在自然语言的翻译里面这个结果已经能看了。但是它们的computational accuracy仍然很低。这应该是要归因于在翻译的时候一些细节出了问题,导致虽然形式上看起来很像但是功能上出现问题。这确实是transcompiler这个任务里很大的一个难点,它太抠细节了。
与baseline的对比,以及不同beam size对比实验的结果
表格中,Beam 10-Top 1表示beam size为10,但最后只输出一个结果;其余都采用了上文提到的,集合中只要有一个结果通过,就算整体通过的评价方法。

baseline是两个已有的transcompile框架,一个是java转python的j2py,另一个是tangible software solution里面的cpp转java模块。
这个实验baseline也太少了点儿。。。
可以发现,纯贪心的结果还没有baseline高。随着beam size的增大,结果的computational accuracy也渐渐增大。
值得注意的是Beam 10-Top 1的结果比起Beam 10有了大幅度的下降,但比纯贪心的Beam 1要好一点点(真的只是一点点。。甚至还有下降,比如java -> c++)。
文中表示,这说明模型在一定范围内能够生成正确的代码,只是没能给正确的结果分配最高的概率,导致beam search的时候选不到而已。
确实,把beam size扩大到25了以后,java to c++的准确率甚至达到90%以上了,但是python到c++和java的转换还是准确率很低。
感觉这应该跟python本身的一些特性有关吧。比如说,python的一些函数允许它把本来要拆开写好几行的代码直接压缩成一个单独的语句,而在c++或java中,相同的功能可能需要写成一大段。如果这个模型的设计真的是基于前面提到的anchor point,这种压缩起来的语句就可能很难跟c++或java中的语句建立对应关系,因为重合度肯定会非常小。反之,c++或者java在转python的时候这种现象带来的影响可能会轻一点,因为c++和java的很多语句都可以很直接地翻译成python,不需要额外的拆解或者合并就可以保留原来的功能。
一些转换结果
文中的附录里给出了一些成功和失败的转换案例。
C++和Java的互转我觉得是相对简单的一个任务,因为这两种语言本身的结构以及设计思想就非常相似。
而无论是rule-based的方法还是像文中这样基于神经网络的方法,python的转换都是一个难点。python是一种解释型语言,它本身的结构并不如c++那样“严谨”。如果使用rule-based方法,就要涉及到变量类型推断的问题。不过从文中展示的一些结果可以看出,这个模型是具有一定解释变量类型的能力的。

另外,文章的结果也指出,该模型对于变量名的无意义修改不敏感。并且能够挖掘出一些较为细节的规则,例如python中实数除和取整除的区别。
下图是一些失败的例子。可以看出,第三个例子正是一个将“压缩”后的python语句对应到java的失败案例。因为它不是rule-based的,即使模型正确提取出了这一句的语义,它也比较难以把这一句展开成正确的java程序段。

参考文献
XLM原文,里面解释了本文中的pretrain策略
transformer原文
另一篇关于Unsupervised MT的文章,也是Facebook家的
大概是Back-translation原文。这个技术在上面那篇文章中也有用到
BLEU是什么