作业一:爬取当当网站图书数据
spider
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
# author: xm time:2020/10/27
import scrapy
from ..items import DangdangItem
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
class spider_dangdang(scrapy.Spider):
name = "spiderdangdang"
# key = 'python'
# source_url='http://www.dangdang.com/'
# start_urls=["http://search.dangdang.com/?key=python&act=input&page_index=2"]
def start_requests(self):
url="http://search.dangdang.com/?key=python&act=input"
print(url)
yield scrapy.Request(url=url,callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body,["utf-8",'gbk'])
data = dammit.unicode_markup
selector=scrapy.Selector(text=data)
lis = selector.xpath("//ul[@class='bigimg']/li")
for li in lis:
title = li.xpath("./p[@class='name']/a/@title").extract_first()
author = li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
price = li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
date = li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher = li.xpath("./p[@class='search_book_author']/span[position()=3]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
# print(title)
item=DangdangItem()
item["title"]=title.strip() if title else ""
item["author"]=author.strip() if author else ""
item['price']=price.strip() if price else ""
item['date']=date.strip()[1:] if price else ""
item['publisher']=publisher.strip() if publisher else ""
item['detail']=detail.strip() if detail else ""
yield item
except Exception as err:
print(err)
item
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
author = scrapy.Field()
publisher = scrapy.Field()
date = scrapy.Field()
price = scrapy.Field()
detail = scrapy.Field()
pipelines
import pymysql
class DangdangPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",
passwd="hadoop",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from books")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"本书籍")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into books(bTitle,bAuthor,bPublisher,bDate,bPrice,bDetail) values (%s,%s,%s,%s,%s,%s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count+=1
except Exception as err:
print(err)
return item
结果展示

心得体会
书上的代码copy之后,又看了看,最后发现了爬取时候怎么把数据库给用上。
作业二:爬取股票信息
spider
import scrapy
import json
import re
import math
from ..items import Gupiao2Item
class spider_gupiao(scrapy.Spider):
name = "spidergupiao"
start_urls=["http://11.push2.eastmoney.com/api/qt/clist/get?&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603874731034"]
def parse(self, response):
try:
sites = json.loads(response.body_as_unicode())
data = sites["data"]
diff = data["diff"]
print(diff)
print(len(diff))
for i in range(len(diff)):
item=Gupiao2Item()
item["mount"]=str(i)
item["code"]=str(diff[i]["f12"])
item["name"]=str(diff[i]["f14"])
item["lately"]=str(diff[i]["f2"])
item["zhangdiefu"]=str(diff[i]["f3"])
item["zhangdiee"]=str(diff[i]["f4"])
item["chengjiaoliang"]=str(diff[i]["f5"])
item["chengjiaoe"]=str(diff[i]["f6"])
item["zhenfu"]=str(diff[i]["f7"])
item["zuigao"]=str(diff[i]["f15"])
item["zuidi"]=str(diff[i]["f16"])
item["jinkai"]=str(diff[i]["f17"])
item["zuoshou"]=str(diff[i]["f18"])
yield item
#all_page = math.ceil(eval(re.findall('"total":(d+)', response.body.decode())[0]) / 20)
page = re.findall("pn=(d+)", response.url)[0] # 当前页数
if int(page) < 5: # 爬取页数
url = response.url.replace("pn=" + page, "pn=" + str(int(page) + 1)) # 跳转下一页
yield scrapy.Request(url=url, callback=self.parse)
yield scrapy.Request(url, self.parse)
except Exception as err:
print(err)
item
import scrapy
class Gupiao2Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
mount = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
lately = scrapy.Field()
zhangdiefu = scrapy.Field()
zhangdiee = scrapy.Field()
chengjiaoliang = scrapy.Field()
chengjiaoe = scrapy.Field()
zhenfu = scrapy.Field()
zuigao = scrapy.Field()
zuidi = scrapy.Field()
jinkai = scrapy.Field()
zuoshou = scrapy.Field()
pipelines
import pymysql
class Gupiao2Pipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",
passwd="hadoop",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from gupiao")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条")
def process_item(self, item, spider):
try:
print(item["mount"])
print()
if self.opened:
self.cursor.execute("insert into gupiao(bid,bbno,bbname,bLatestPrice,bZhangDieFu,bZhangDieE,bChengJiaoLiang,bChengJiaoE,bZhenFu,bZuiGao,bZuiDi,bJinKai,bZuoShou) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",(item["mount"],item["code"],item["name"],item["lately"],item["zhangdiefu"],item["zhangdiee"],item["chengjiaoliang"],item["chengjiaoe"],item["zhenfu"],item["zuigao"],item["zuidi"],item["jinkai"],item["zuoshou"]))
self.count+=1
except Exception as err:
print(err)
return item
结果展示
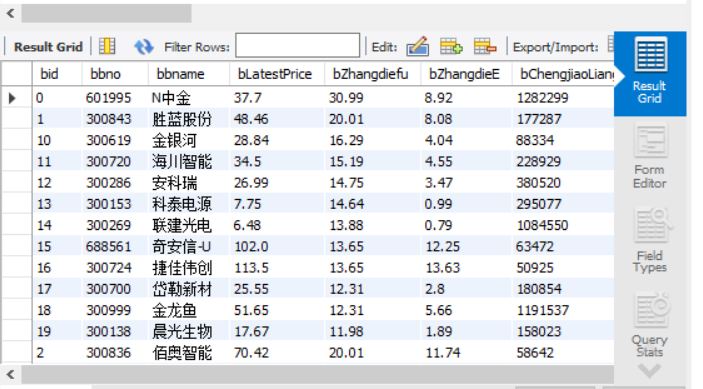
心得体会
数据库还是用的不够熟练,在雷明的教导下完成了本次爬取的结果,正则上面也是受到雷明的启发下才有进展。
作业三:爬取外汇数据
spider
import scrapy
from bs4 import UnicodeDammit
from ..items import WaihuiItem
class spider_Waihui(scrapy.Spider):
name = "spiderWaihui"
start_urls=["http://fx.cmbchina.com/hq/"]
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", 'gbk'])
data = dammit.unicode_markup
# print(data)
selector = scrapy.Selector(text=data)
trs = selector.xpath("//div[@id='realRateInfo']/table/tr")
# print(trs)
for tr in trs[1:]:
item=WaihuiItem()
a =tr.xpath("./td[position()=1][@class='fontbold']/text()").extract_first()
item["type"] = str(a).strip()
item["tsp"] = str(tr.xpath("./td[position()=4][@class='numberright']/text()").extract_first()).strip()
item["csp"] = str(tr.xpath("./td[position()=5][@class='numberright']/text()").extract_first()).strip()
item["tbp"] = str(tr.xpath("./td[position()=6][@class='numberright']/text()").extract_first()).strip()
item["cbp"] = str(tr.xpath("./td[position()=7][@class='numberright']/text()").extract_first()).strip()
item["time"] = str(tr.xpath("./td[position()=8][@align='center']/text()").extract_first()).strip()
yield item
except Exception as err:
print(err)
items
import scrapy
class WaihuiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
type = scrapy.Field()
tsp = scrapy.Field()
csp = scrapy.Field()
tbp = scrapy.Field()
cbp = scrapy.Field()
time = scrapy.Field()
pipelines
import pymysql
class WaihuiPipeline:
def open_spider(self,spider):
print("opened")
try:
self.con=pymysql.connect(host="127.0.0.1",port=3306,user="root",
passwd="hadoop",db="mydb",charset="utf8")
self.cursor=self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from waihui")
self.opened=True
self.count=0
except Exception as err:
print(err)
self.opened=False
def close_spider(self,spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened=False
print("closed")
print("总共爬取",self.count,"条")
def process_item(self, item, spider):
try:
if self.opened:
self.cursor.execute("insert into waihui(btype,btsp,bcsp,btbp,bcbp,btime) values (%s,%s,%s,%s,%s,%s)",(item["type"],item["tsp"],item["csp"],item["tbp"],item["cbp"],item["time"]))
self.count+=1
except Exception as err:
print(err)
return item
结果展示
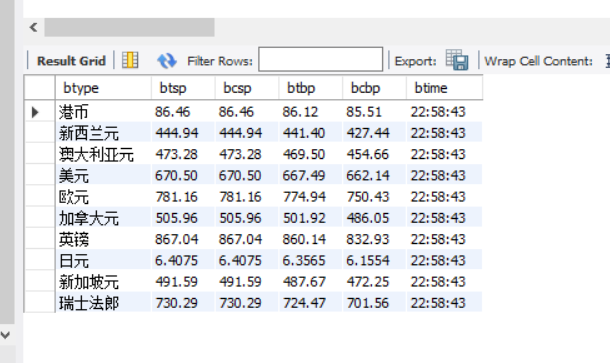
心得体会
在改了很久之后,自己终于完成了最后一次的爬取任务,不过在数据库的使用上面还是很不熟悉,以后还需要加强练习。