MySQL 数据库的存储结构
数据库存储结构
- 从小到大、行>页 >区>段>表空间 (在Oracle中将页称为"块")
- 页是数据库管理存储空间的基本单位,即,数据库I/O的最小单位是页
- InnoDB默认页大小为16K,可以通过
show variavles like '%innodb_page_size%'来查询页的大小。 - 一个区会分配64个连续的页,因此InnoDB的一个区是 1M
- 段是数据库的分配单位,且不要求段中的区与区必须连续。不同数据库对象以不同的段形式存在,也就是说创建一个表时会创建一个表段,创建一个索引时会创建一个索引段。一个段只能属于一个表空间。
- 表空间是一个逻辑容器,从管理上可以划分为 系统表空间、用户~、临时~、撤销~。InnoDB有两种表空间类型:共享表空间和独立表空间。使用
show variables like 'innodb_file_per_tble;'如果查询结果为ON,那么说明每张表都会大单独保存为一个.ibd文件
页内存储结构
借用陈旸老师的图:
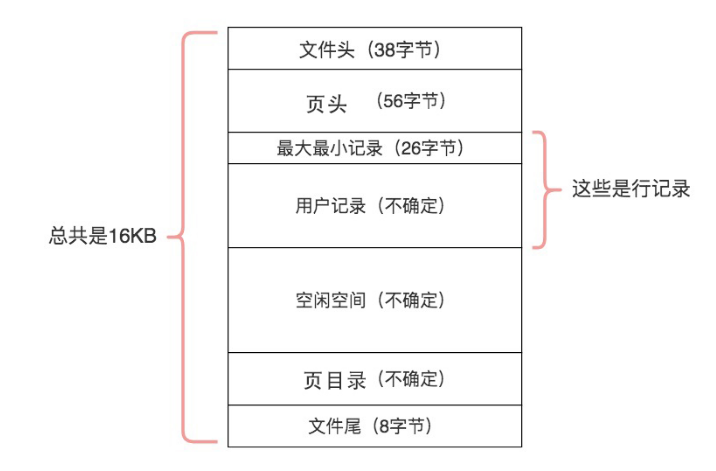
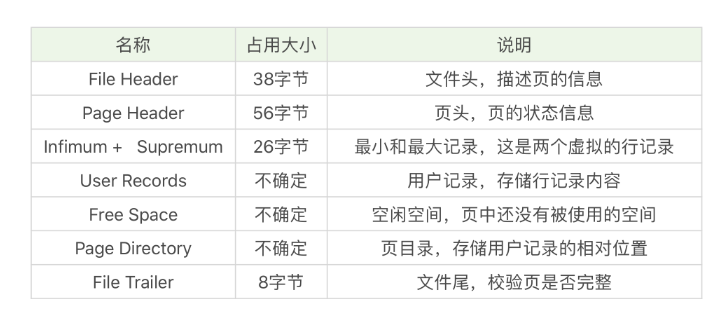
- 文件头:数据页之间形成双相链表。头文件中有两个字段---FILE_PAGE_PAGE和FILE_PAGE_NEXT。采用链表就使得数据页之间不必是物理上的连续,而是逻辑上的连续。
- 文件尾:进行页传输的时候可以将文件尾的检验和和文件头的检验和对比来进行校验。假如在传输页的时候发生了断电中断,就会造成校验和的不相等。
- 记录部分:“最小和最大记录”和“用户记录”占据页的主要空间,“空闲空间”则是在新数据插入时,会在空闲空间开始存储。
- 索引部分:页目录起到了索引的作用。因为在页的节点中记录是以单向链表的形式组织起来的,查询效率不高,因此在因此在页目录中提供了二分查找的方式来加速查询效率。
B+树如何在数据页上进行查询
B+结构与存储结构
- 在索引模型中我们说过索引可以分为聚集索引和非聚集索引,而每一个索引都相当于一棵B+树,只是两者的存储内容不同。
- 在B+树种每个节点都是一个页,这也就是为什么“每访问一次节点就需要对磁盘进行一次I/O操作”。
- 每次新建节点的时候都会申请一个页空间,而且同一层的节点之间会形成双向链表(利用文件头的双向指针)
- 在节点内部,非叶子节点存储的是索引键和指向下一层的指针,叶子节点存储的是关键字(或许还有行记录),节点内部的记录之间是单向链表并使用页目录加速。
- 即,同层节点之间构成双向链表,节点内记录之间形成单向链表
检索过程
- 从B+树的根节点开始,逐层顺着索引向下寻找目标关键字,找到关键字对应的节点后,就将该页加载到内存中
- 然后利用页目录进行粗略的二分查找,再通过链表遍历找到具体位置。
- (聚集索引的行记录在物理上是连续的)