数据准备2 数据清洗2 小案例实战
好的数据分析师必定是一名数据清洗高手,没有高质量的数据,就没有高质量的数据挖掘
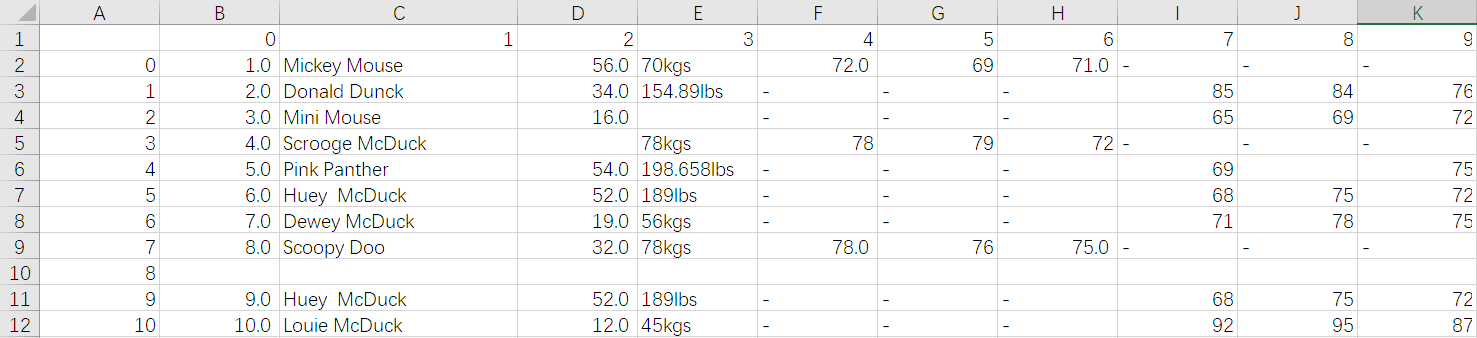
现有如下数据,然后我们对它进行数据清洗:
我个人进行清洗的原则是,先对列或行进行增加/删除/分割/插入,再对“单元格”进行修整
-
0.读取原始数据
import pandas as pd # 0.读取csv文件 df = pd.read_excel(r"C:yourpathtofile.xlsx") print("原始数据为:") print(df) print("-----------") ''' 数据解读: 用户信息表 是数据导出时的产生的序号 第0列是原始数据时的序号 第1列是用户姓名 第2列是用户年龄 第3列是用户体重 第4~6列是男性用户三围 第7~9列是女性用户三围 ''' -
1.删除多余列
df1 = df.drop(axis=1, columns=[' ',0], inplace=False) print(df1) print("-----------") -
2.删除空行
print("删除空行:* 'all' : If all values are NA, drop that row or column.") df1.dropna(how="all", inplace=True) print(df1) print("-----------") -
3.更改列名
print("更改列名:") # 更改全部列名 df1.columns = ['name', 'age', 'weight', 'male1', 'male2', 'male3', 'female1', 'female2', 'female3'] print("列名为:", df1.columns.values) print("-----------") # 如果使用print("列名为:"+df1.columns.values),则会在每个元素前都输出"列名为:" -
4.拆分列
print("拆分列:") df1[['first_name', 'last_name']] = df1['name'].str.split(expand=True) # expand=True时pandas会自动为你分成列,expand=False时仅仅是在原有列上分开,不自动分为列 print(df1) print("-----------") -
5.移动列(并删除多余列)
print("移动列:") df1 = df1.drop(axis=1, columns='name') first_name = df1.pop('first_name') last_name = df1.pop('last_name') df1.insert(0, 'first_name', first_name) df1.insert(1, 'last_name', last_name) # print(df1) pd.set_option('display.max_columns', 10) pd.set_option('display.width', 100) print(df1) # insert时必须要求列名 print("-----------") -
6.填充空缺值
df1['age'].fillna(round(df1['age'].mean(), 2), inplace=True) # df1['weight'].fillna(df1['weight'].mean(), inplace=True) print(df1) # 对weight这样还是str类型的自然不能求平均值,否则报错can only concatenate str (not "int") to str print("-----------") -
7.删除某些列中(可组合)的重复数据(保留第一条)
print("删除重复数据:") # df1.drop_duplicates('last_name', inplace=True) df1.drop_duplicates(['first_name', 'last_name'], inplace=True) print(df1) print("-----------") -
8.统一单位
rows_with_lbs = df1['weight'].str.contains('lbs').fillna(False) for i, r in df1[rows_with_lbs].iterrows(): num = int(float(r['weight'][:-3])/2.2) df1.at[i, 'weight'] = '{}kgs'.format(num) print(df1) print("-----------")
Fix Error
在“8.统一单位”可能会出现如下报错
-
(index of the boolean Series and of the indexed object do not match)原因:因为df1[rows_with_lbs]错写成了df[rows_with_lbs]导致因为df和df1的index不匹配
-
KeyError: 'weight'原因:df1['weight'].str.contains('lbs')错写成了df['weight'].str.contains('lbs'),因为df的列名没改,程序找不到
-
要小心df1.at[i, 'weight'] = '{}kgs'.format(num),这里假如写成了df,那么(可能)会修改df的部分weight值 且 不会报错