一、collections模块
美 [kə'lekʃənz] ,收集,收藏
在内置数据(dict list set tuple)的基础上,collections模块海提供了几个常用的数据类型:counter deque defaulttdict namedtuple OrderedDict。
1:namedtuole: 生成可以使用名字来访问元素内容的tuple
2:deque: 双端队列
3:Counter:计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
1:namedtuple(具名元组) 常用在表示坐标,记录城市的信息等
from collections import namedtuple # 调用模块的功能,格式 info=namedtuple('info',['x','y','z']) # 格式:namedtuple('名称', [属性list]): p=info(1,2,3) print(p) city=namedtuple('上海GDP',['浦东区','徐汇区','青浦区']) data=city(15000,100000,130000) print(data) # # 注意元素的个数必须跟namedtuple第二个参数里面的值数量一致
2:deque: 美 ['dek] 双端对列
deque 是为了高效实现插入和删除操作的双向列表,适合用于队列和栈。
常用到的有:addpend() pop() appedleft() popleft() 按索引插入insert(1,’G‘)
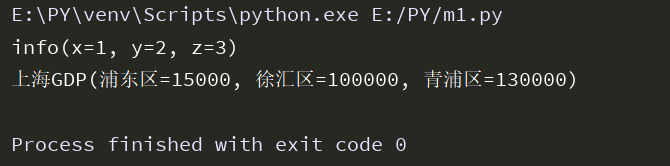
from collections import deque q=deque(['a','b','c']) q.append('x') q.appendleft('y') # 进栈,添加字符 print(q) res=q.pop() res1=q.popleft() print(res,res1) #出栈,取出字符,默认先进先出的原则 q.insert(1,'kevin') # 特殊点:双端队列可以根据索引在任意位置插值 print(q)
3、OrderedDict :有序字典
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序。
如果要保持Key的顺序,可以用OrderedDict:
常用的创建字典形式:
normal_d=dict([('a',4),('b',5),('c',6)])
print(normal_d)
结果:{'a': 4, 'b': 5, 'c': 6} key:vlave 是有序的,在Python2终端是无序的
from collections import OrderedDict order_d = OrderedDict([('a',1),('b',2),('c',3)]) order_d1 = OrderedDict() #建空字典,往里面添加值 order_d1['x'] = 1 order_d1['y'] = 2 order_d1['z'] = 3 print(order_d1) 结果: >> OrderedDict([('x', 1), ('y', 2), ('z', 3)])
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:
4、defaultdict: 带有默认值的字典
dict 原生字典按key取value的值,如果没有,就会报错
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict >>> dd = defaultdict(lambda: 'N/A') >>> dd['key1'] = 'abc' >>> dd['key1'] # key1存在 'abc' >>> dd['key2'] # key2不存在,返回默认值 是什么就返回什么,没有就 None
'N/A'
5、Counter :
用来跟踪值出现的次数,它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter a='habljdbgjdsbaljasdls' res=Counter(a) print(res) #Counter是用来统计字字符出现的次数,并以字典key:value的形势返回

二、时间模块 time datetime
常用的有:time.time time.sleep() 元组(struct_time) 时间戳:timestamp
三种表现形式:
1:时间戳
2:格式化时间(用来展示给人看的)
3:结构化时间
常用的:
import time 1.time.sleep(secs) (线程)推迟指定的时间运行。单位为秒。 2.time.time()
》》1500875844.800804 获取当前时间戳
时间字符串:表示年月日时用(重点掌握)
import time print(time.time()) print(time.strftime('%Y:%m:%d')) # 代表的是年月日 print(time.strftime('%Y-%m-%d %H-%M-%S')) # 时分秒 print(time.strftime('%Y-%m-%d %X')) print(time.strftime('%H:%M')) # 时分 print(time.strftime('%Y%m')) # 年月 中间的格式可以随便更改 %X等价于 %H:%M:%S

2、结构化时间:localtime
时间元组:localtime将一个时间戳转换为当前时区的struct_time time.localtime() time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24, tm_hour=13, tm_min=59, tm_sec=37, tm_wday=0, tm_yday=205, tm_isdst=0)
几种格式之间的转换:
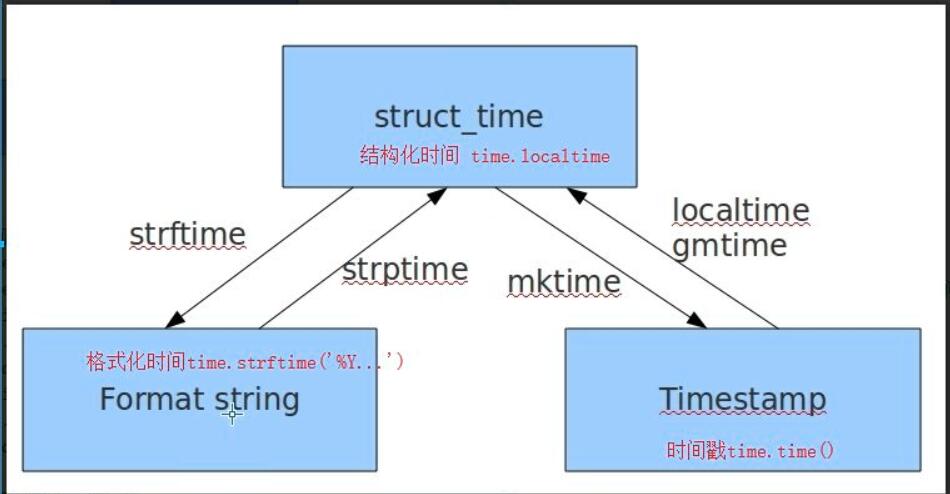
#结构化时间-->时间戳 #time.mktime(结构化时间) >>>time_tuple = time.localtime(1500000000) >>>time.mktime(time_tuple) 1500000000.0
#结构化时间-->字符串时间 #time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间 >>>time.strftime("%Y-%m-%d %X") '2017-07-24 14:55:36' >>>time.strftime("%Y-%m-%d",time.localtime(1500000000)) '2017-07-14'
3、datetime
import datetime print(datetime.date.today()) # date>>>:年月日 print(datetime.datetime.today()) # datetime>>>:年月日 时分秒 res = datetime.date.today() res1 = datetime.datetime.today() print(res.year) print(res.month) print(res.day) print(res.weekday()) # 0-6表示星期 0表示周一 print(res.isoweekday()) # 1-7表示星期 7就是周日

日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
current_time = datetime.date.today() # 日期对象 timetel_t = datetime.timedelta(days=7) # timedelta对象 res1 = current_time+timetel_t # 日期对象 print(current_time - timetel_t) print(res1-current_time)
计算生日:
import datetime birth=datetime.date(2019,8,24) # 生日 current_time=datetime.date.today() # 今天的时间 print(birth-current_time)
>>>> 37 days, 0:00:00
4、UTC 时间:世界标准时间
# 总结年月日时分秒及时区问题 import datetime dt_today = datetime.datetime.today() dt_now = datetime.datetime.now() dt_utcnow = datetime.datetime.utcnow() # UTC时间与我们的北京时间相差8个小时
print(dt_today) print(dt_now) print(dt_utcnow)
>>结果:
2019-07-18 20:27:55.550721
2019-07-18 20:27:55.550721
2019-07-18 12:27:55.550721
三、random
随机:应用场景:发红包、洗牌、摇色子等随机的事件
import random print(random.randint(1,6)) #随机取一个整数范围内的数 print(random.random()) # 随机取0-1之间的小数 print(random.choice([1,2,3,4,5,6])) # 随机从列表中取一个元素
>>>
3
0.9257484255619343
5
随机生成验证码:大写字母 小写字母 数字组成
5位数的随机验证码 chr #字符的转换 对应的ASCCII码 random.choice #利用radommo模块的choice功能 封装成一个函数,用户想生成几位就生成几位 """ def get_code(n): code = '' for i in range(n): # 先生成随机的大写字母 小写字母 数字 upper_str = chr(random.randint(65,90)) # A-Z 对应的ASCII码表 lower_str = chr(random.randint(97,122)) random_int = str(random.randint(0,9)) # 从上面三个中随机选择一个作为随机验证码的某一位 code += random.choice([upper_str,lower_str,random_int]) return code res = get_code(5) print(res)
>>5vcQu
四、os
模块:与操作系统交互的一个接口
os.listdir:
列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
import os print(os.listdir(r'E:\PY\陈奕迅的歌曲')) #打开文件目录
>>> ['不要说话.txt', '十年.txt', '孤独患者.txt', '最佳损友.txt', '爱情转移.txt', '陪你度过漫长的岁月.txt']
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
程序功能:实现打开文件夹目录,让用户挑选文件打开(运用os模块里的一些功能)
import os BASE_DIR = os.path.dirname(__file__) MOVIE_DIR = os.path.join(BASE_DIR,'陈奕迅的歌曲')# 添加文件路径目录 music_list = os.listdir(r'E:\PY\陈奕迅的歌曲') while True: for i,j in enumerate(music_list,1): print(i,j) choice = input('你想听那一首啊(今日排行榜)>>>:好久不见').strip() if choice.isdigit(): # 判断用户输入的是否是纯数字 choice = int(choice) # 传成int类型 if choice in range(1,len(music_list)+1): # 判断是否在列表元素个数范围内 # 获取用户想要看的文件名 target_file = music_list[choice-1] # 拼接文件绝对路径 target_path = os.path.join(music_DIR,target_file) with open(target_path,'r',encoding='utf-8') as f: print(f.read())
os.path:
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.abspath(path) 返回path规范化的绝对路径
os.path.getsize(path) 返回path的大小
五、SYS 模块: 与python 解释器交互的一个接口
重点了解:sys.argv 程序在终端运行时可以用来确认用户信息,核对后才能打开py文件
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path.append() 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
import sys sys.path.append() print(sys.platfimport sys sys.path.append() # 将某个路径添加到系统的环境变量中 print(sys.platform) print(sys.version) # python解释器的版本 print(sys.argv) # 命令行启动文件 可以做身份的验证 if len(sys.argv) <= 1: print('请输入用户名和密码') else: username = sys.argv[1] password = sys.argv[2] if username == 'jason' and password == '123': print('欢迎使用')
六、序列化模块:是将原本的字典、列表等内容转换成一个字符串的过程
序列化就i是字符串,为了兼容多平台的使用,需转换成同一的类型的字符,传输的数据必须是二进制
序列化:其他数据类型转换成字符串的过程
反序列化:字符串转成其他数据类型
1、Json模块提供了四个功能:dumps、dump、loads、load
所有语言都支持 json 格式,但它支持的数据类型很少: str list dict int tuple(元组转成列表) bool
2、pickle模块(****)
只支持python语言
python所有的数据类型都支持
3、模块的使用:
json: 用于字符串 和 python数据类型间进行转换
(1)、dumps:序列化 将其他数据类型转成json格式的字符串
loads:反序列化 将json格式的字符串转换成其他数据类型
import json d={"name":"jason"} # json格式的字符串 必须是双引号 print(d) res=json.dumps(d) print(res,type(res))
res1 = json.loads(res)
print(res1,type(res1)) >>{'name': 'jason'} {"name": "jason"} <class 'str'>
{'name': 'jason'} <class 'dict'>
(2)、dump,load 也是序列化和反序列化,是结合文件一起使用的
import json d={"name":"jason"} with open('userinfo','w',encoding='utf-8') as f: json.dump(d,f) # 装字符串并自动写入文件 with open ('userinfo','r',encoding='utf-8') as f: res=json.load(f) print(res,type(res)) >>>{'name': 'jason'} <class 'dict'>
想让传入的字典内容不变的,中文就是中文:关键字参数:ensure_ascii=False
import json d1={'name':'周杰伦'} print(json.dumps(d1,ensure_ascii=False)) #转换为不变的格式 >>>{"name": "\u5468\u6770\u4f26"} >>{"name": "周杰伦"}
pickle: 用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
import pickle d = {'name':'jason'} res = pickle.dumps(d) # 将对象直接转成二进制 print(pickle.dumps(d)) res1 = pickle.loads(res) print(res1,type(res1)) >>> 结果: b'\x80\x03}q\x00X\x04\x00\x00\x00nameq\x01X\x05\x00\x00\x00jasonq\x02s.' {'name': 'jason'} <class 'dict'>
用pickle操作文件的时候 文件的打开模式必须是b模式
with open('userinfo','wb') as f: pickle.dump(d,f) with open('userinfo_1','rb') as f: res = pickle.load(f) print(res,type(res))
六、subprocess :子进程模块
1.用户通过网络连接上了你的这台电脑
2.用户输入相应的命令 基于网络发送给了你这台电脑上某个程序
3.获取用户命令 里面subprocess执行该用户命令
4.将执行结果再基于网络发送给用户
这样就实现 用户远程操作你这台电脑的操作
while True: cmd = input('cmd>>>:').strip() import subprocess obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE) # print(obj) print('正确命令返回的结果:stdout',obj.stdout.read().decode('gbk')) print('错误命令返回的提示信息:stderr',obj.stderr.read().decode('gbk'))
>>>结果:
cmd>>>:123
正确命令返回的结果:stdout
错误命令返回的提示信息:stderr '123' 不是内部或外部命令,也不是可运行的程序
或批处理文件。