Maps
什么是 map ?
类似Python中的字典数据类型,以k:v键值对的形式。
map 是在 Go 中将值(value)与键(key)关联的内置类型。通过相应的键可以获取到值。
如何创建 map ?
通过向 make 函数传入键和值的类型,可以创建 map。make(map[type of key]type of value) 是创建 map 的语法。
// personSalary := make(map[string]int)
上面的代码创建了一个名为 personSalary 的 map,其中键是 string 类型,而值是 int 类型。
map 的零值是 nil。如果你想添加元素到 nil map 中,会触发运行时 panic。因此 map 必须使用 make 函数初始化。
//maps package main import "fmt" func main() { //maps的定义 //map的key值必须可hash //var a map[键值类型]value值类型 //map的空值是nil类型 var a map[int]string fmt.Println(a) if a==nil{ fmt.Println("xxxx") } }

map修改和添加元素
给 map 添加新元素的语法和数组相同
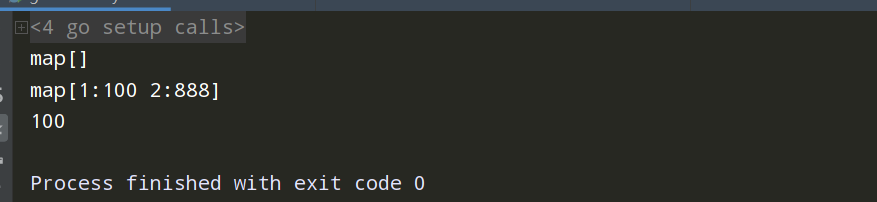
package main import "fmt" func main(){ //map的赋值跟取值 //map的初始化 var a map[int]string=make(map[int]string) fmt.Println(a) if a==nil{ fmt.Println("hello") } a[1]="100" a[2]="888" fmt.Println(a) fmt.Println(a[1]) ////取一个不存在的key值会?返回value值的空值
////fmt.Println(a[9]) //var b map[int]int=make(map[int]int) //b[1]=100 //fmt.Println(b) ////fmt.Println(b[9]) //if v,ok:=a[9];ok{ // fmt.Println("=-====",v) //}else { // fmt.Println("该值不存在") //} //v,ok:=a[1] //fmt.Println(v) //fmt.Println(ok) //定义和初始化的第二种方式 //var a =map[int]string{1:"10",2:"100"} ////a[1] //fmt.Println(a[1]) }
对应的以key:value的形式赋值,赋值和取值都是通过key来操作value的。
删除 map 中的元素
删除 map 中 key 的语法是 [delete(map, key)]。这个函数没有返回值。
package main import ( "fmt" ) func main() { personSalary := map[string]int{ "steve": 12000, "jamie": 15000, } personSalary["mike"] = 9000 fmt.Println("map before deletion", personSalary) delete(personSalary, "steve") fmt.Println("map after deletion", personSalary) }
上述程序删除了键 "steve",输出:
map before deletion map[steve:12000 jamie:15000 mike:9000]
map after deletion map[mike:9000 jamie:15000]
获取 map 的长度
获取 map 的长度使用 [len]函数。
package main import ( "fmt" ) func main() { personSalary := map[string]int{ "steve": 12000, "jamie": 15000, } personSalary["mike"] = 9000 fmt.Println("length is", len(personSalary)) }
上述程序中的 len(personSalary) 函数获取了 map 的长度。程序输出 length is 3。3对k:v键值对。
Map 是引用类型
和 [slices]类似,map 也是引用类型。当 map 被赋值为一个新变量的时候,它们指向同一个内部数据结构。因此,改变其中一个变量,就会影响到另一变量。
package main import "fmt" func main(){ //Map 是引用类型 var a =map[int]string{1:"10",2:"100"} test4(a) fmt.Println(a)
func test4(a map[int]string) { a[1]="888" fmt.Println(a) }

当 map 作为函数参数传递时也会发生同样的情况。函数中对 map 的任何修改,对于外部的调用都是可见的。
Map 的相等性
map 之间不能使用 == 操作符判断,== 只能用来检查 map 是否为 nil。
package main import "fmt" func main(){ //Map 的相等性 map1 := map[string]int{ "one": 1, "two": 2, } map2 := map1 if map1 == map2 { //报错 } //map循环出所有元素 //var a =map[int]string{1:"10",0:"100",10:"999"} ////for i:=0;i<len(a);i++{ //// fmt.Println(a[i]) ////} ////map是无序的 //for k,v:=range a{ // fmt.Println(k) // fmt.Println(v) //} //补充:切片删除元素 //var a =[]int{1,2,3,4,5,6} //a=append(a[0:2],a[3:]...) //fmt.Println(a) } }
上面程序抛出编译错误 invalid operation: map1 == map2 (map can only be compared to nil)。
判断两个 map 是否相等的方法是遍历比较两个 map 中的每个元素。我建议你写一段这样的程序实现这个功能
字符串
什么是字符串?
Go 语言中的字符串是一个字节切片。把内容放在双引号" "之间,我们可以创建一个字符串。让我们来看一个创建并打印字符串的简单示例。
package main import ( "fmt" ) func main() { name := "Hello World" fmt.Println(name) }
上面的程序将会输出 Hello World。
Go 中的字符串是兼容 Unicode 编码的,并且使用 UTF-8 进行编码。
其他方法:
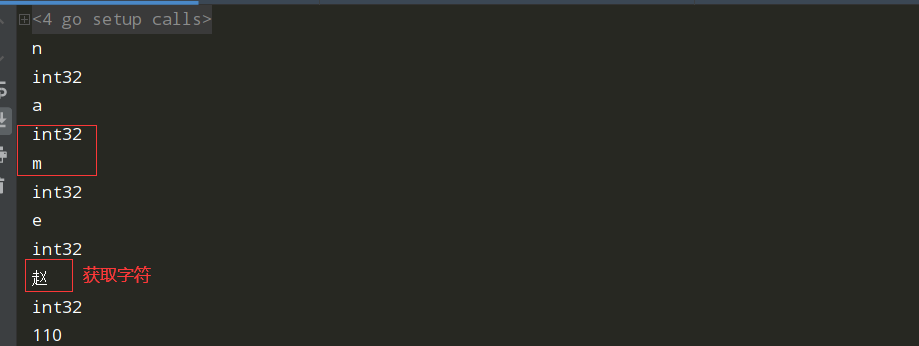
package main import ( "fmt" "unicode/utf8" ) package main import ( "fmt" "unicode/utf8" ) func main() { name := "Hello World蟒蛇" //name:="赵" //字符串长度,len统计字节数 //在go种string类型都是utf-8编码
fmt.Println(len(name)) fmt.Println(utf8.RuneCountInString(name)) //unicode是一个字符编码对照表 //循环 //字符串是个只读切片 //name := "name赵" //for i:=0;i<len(name);i++{ // fmt.Println(string(name[i])) // fmt.Printf("%T",name[i]) // fmt.Println() //} //for _,v:=range name{ // fmt.Println(string(v)) // fmt.Printf("%T",v) // fmt.Println() //} //name := "name赵" //name[0]=99 //fmt.Println(name[0]) //fmt.Println(string(name[0])) byteSlice := []byte{0x43, 0x61, 0x66, 0xC3, 0xA9}// 打印的是字节数 str := string(byteSlice) a:=len(str) b:=utf8.RuneCountInString(str) fmt.Println(b) fmt.Println(a) fmt.Println(str) }
需要注意的是:字节数和字符数的区别,一个字节占用了三个字符个数;取长度的关键字:-len(str) utf8.RuneCountInString(str)
单独获取字符串的每一个字节
由于字符串是一个字节切片,所以我们可以获取字符串的每一个字节。
package main import ( "fmt" ) func printBytes(s string) { for i:= 0; i < len(s); i++ { fmt.Printf("%x ", s[i]) } } func main() { name := "Hello World" printBytes(name) }
go中的string字符串的形式都是以utf-8的形式存入内存中,而其他语言以Unicode万国码形式,获取长度用:

字符串的 for range 循环
循环出来的是一个个的字符数,可以用rune的方法和for range的方法
package main import "fmt" func main(){ //循环 //字符串是个只读切片 // 第一种:循环字节的个数 name := "name赵" //for i:=0;i<len(name);i++{ // fmt.Println(string(name[i])) // fmt.Printf("%T",name[i]) // //fmt.Println() //} // 循环出来的字符的个数,一般用第二种,会乱码 for _,v:=range name{ fmt.Println(string(v)) //转格式 fmt.Printf("%T",v) fmt.Println() } //字符串是个只读切片,只能读,不能等修改 //name := "name赵" //name[0]=99 fmt.Println(name[0]) fmt.Println(string(name[0])) }
字符串是不可变的,Go 中的字符串是不可变的。一旦一个字符串被创建,那么它将无法被修改
字符只能读取,不支持修改。
用字节切片构造字符串
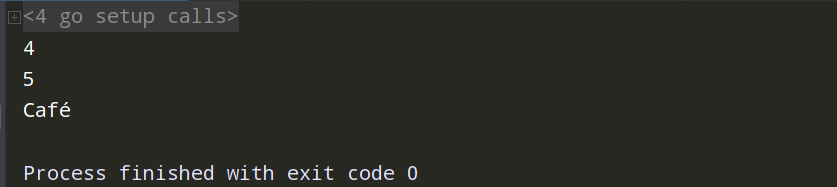
package main import ( "fmt" "unicode/utf8" ) func main() { byteSlice := []byte{0x43, 0x61, 0x66, 0xC3, 0xA9}// 打印的是字节数 str := string(byteSlice) a:=len(str) b:=utf8.RuneCountInString(str) fmt.Println(b) fmt.Println(a) fmt.Println(str) }
指针
什么是指针?
指针是一种存储变量内存地址(Memory Address)的变量。
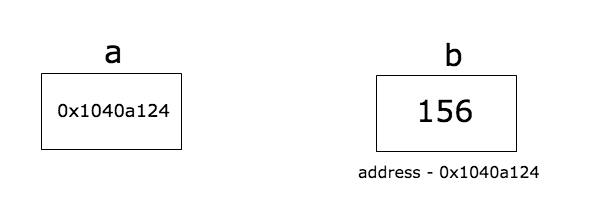
如上图所示,变量 b 的值为 156,而 b 的内存地址为 0x1040a124。变量 a 存储了 b 的地址。我们就称 a 指向了 b。
指针的声明
指针变量的类型为 *T,该指针指向一个 T 类型的变量。
总结:
//&取地址符号 //* 放在类型旁边,表示指向这个类型的指针 //* 放在变量旁边,表示解引用(反解)
例子:
//指针 package main import "fmt" func main() { //&取地址符号 //* 放在类型旁边,表示指向这个类型的指针 //* 放在变量旁边,表示解引用(反解) a:=10 //b就是一个指针 指向int类型的指针 //b:=&a //d:="sss" //var c *string=&d var b *int =&a fmt.Println(b) fmt.Println(*b) //把b对应的值给取出来 c:=&b //var c **int=&b //指向int类型的指针 fmt.Println(*(*c)) }
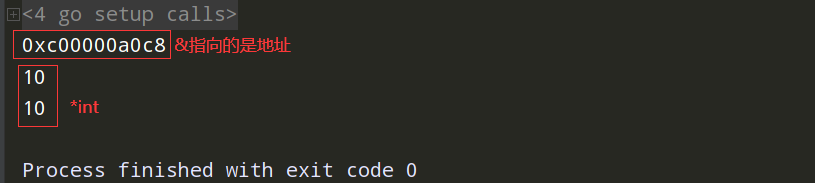
指针的零值(Zero Value)
指针的零值是 nil。
package main import "fmt" func main(){ //指针的零值(Zero Value),nil类型 //var a *int //fmt.Println(a) }>>>nil
向函数传递指针参数
package main import "fmt" func change(val *int) { *val = 55 } func main() { a:=58 fmt.Println(a) b:=&a change(b) fmt.Println(a) }
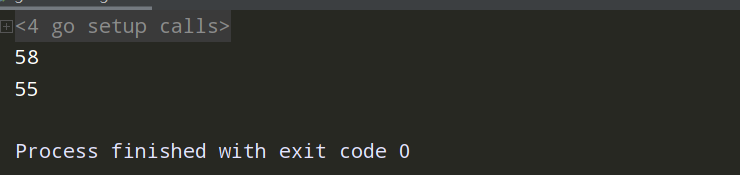
在上面程序中的,我们向函数 change 传递了指针变量 b,而 b 存储了 a 的地址。程序在 change 函数内使用解引用。
不要向函数传递数组的指针,而应该使用切片
假如我们想要在函数内修改一个数组,并希望调用函数的地方也能得到修改后的数组,一种解决方案是把一个指向数组的指针传递给这个函数。
//向函数传递指针参数 a := 10 b := &a test6(b) fmt.Println(a) test7(a) fmt.Println(a) //不要向函数传递数组的指针,而应该使用切片 var a [100]int test9(&a) fmt.Println(a) test10(a[:]) fmt.Println(a) //Go 不支持指针运算 func test9(a *[4]int) { (*a)[0]=999 fmt.Println(a) } func test10(a []int) { a[0]=999 fmt.Println(a) }
只是不建议,可以使用,但系统默认会认为是指针的地址。
Go 不支持指针运算
Go 并不支持其他语言(例如 C)中的指针运算。
package main
func main() {
b := [...]int{109, 110, 111}
p := &b
p++
}上面的程序会抛出编译错误:main.go:6: invalid operation: p++ (non-numeric type *[3]int)。
16. 结构体
什么是结构体?
类似其他语言的面向对象,一个类有属性有方法;go中可以通过其他的方法实现类的三大属性:继承,封装,多态派生的方法。
结构体是用户定义的类型,表示若干个字段(Field)的集合。有时应该把数据整合在一起,而不是让这些数据没有联系。这种情况下可以使用结构体。
例如,一个职员有 firstName、lastName 和 age 三个属性,而把这些属性组合在一个结构体 employee 中就很合理。
结构体的声明
格式:type 关键字 解构体名字 struct{ }
package main import "fmt" //结构体:是一系列属性的集合 //定义一个人结构体 //type关键字 结构体名字 struct{} type Person struct { name string sex int age int } func main() { //person :=Person{} //定义没有初始化 //结构体是值类型 //var person Person //var person Person=Person{name:"lqz"} var person Person=Person{"lqz",1,19} //person.name="lqz" fmt.Println(person.name) // 获取的话直接·属性 }
创建匿名结构体
匿名就是没有type的结构体名,但要引用的话必须先实例化才能使用,与一般的结构体有点区别而已。
package main import "fmt" func main(){ a:=struct { name string age int hobby string }{"rose",19,"music"} fmt.Printf(a.name) //fmt.Printf(a.age) fmt.Printf( a.hobby) }
结构体的零值(Zero Value)
当定义好的结构体并没有被显式地初始化时,该结构体的字段将默认赋为零值,有字段决定。
package main import ( "fmt" ) type Employee struct { firstName, lastName string age, salary int } func main() { var emp4 Employee //zero valued structure fmt.Println("Employee 4", emp4) }
该程序定义了 emp4,却没有初始化任何值。因此 firstName 和 lastName 赋值为 string 的零值("")。
而 age 和 salary 赋值为 int 的零值(0)。该程序会输出:
Employee 4 { 0 0}结构体的指针
也可以创建指向结构体的指针。
package main import "fmt" func main(){ //结构体指针 p:=Person{name:"lqz"} //pPoint:=&p var pPoint *Person=&p //fmt.Println(pPoint) //fmt.Println((*pPoint).name) fmt.Println(pPoint.name) }
匿名字段
当我们创建结构体时,字段可以只有类型,而没有字段名。这样的字段称为匿名字段
以下代码创建一个 Person 结构体,它含有两个匿名字段 string 和 int。
type Person struct { string int }
我们接下来使用匿名字段来编写一个程序。
package main import ( "fmt" ) type Person struct { string int } func main() { p := Person{"Naveen", 50} fmt.Println(p) }
上述直接传相应的字段类型的值即可,会自动匹配字段类型。
虽然匿名字段没有名称,但其实匿名字段的名称就默认为它的类型
嵌套结构体(Nested Structs)
字段定义的时候,字段里嵌套另一个字段。
// 嵌套结构体 package main import "fmt" type Person struct{ name string sex int age int hobby Hobby } type Hobby struct{ id int name string } func main(){ //erson{name:"gai",hobby:Hobby{id:10,name:"篮球“} // 两种传参方式 p:=Person{name:"lqz",hobby:Hobby{id:10,name:"篮球"}} p.hobby.id=102 fmt.PrintLn(P.hobby.name) // 获取属性值的方法 } }
//变量提升过程中如果有重名的,就不提升了
//p:=Person{name:"lqz",Hobby:Hobby{10,"篮球"}}
//fmt.Println(p.Hobby.name)
//fmt.Println(p.name)
>>:篮球
提升字段(Promoted Fields)
有点类似面向对象的继承,继承类中的属性。
如果是结构体中有匿名的结构体类型字段,则该匿名结构体里的字段就称为提升字段。这是因为提升字段就像是属于外部结构体一样,可以用外部结构体直接访问。
type Address struct { city, state string } type Person struct { name string age int Address }
在上面的代码片段中,Person 结构体有一个匿名字段 Address,而 Address 是一个结构体。
现在结构体 Address 有 city 和 state 两个字段,访问这两个字段就像在 Person 里直接声明的一样,因此我们称之为提升字段。
package main import ( "fmt" ) type Address struct { city, state string } type Person struct { name string age int Address } func main() { var p Person p.name = "Naveen" p.age = 50 p.Address = Address{ city: "Chicago", state: "Illinois", } fmt.Println("Name:", p.name) fmt.Println("Age:", p.age) fmt.Println("City:", p.city) //city is promoted field fmt.Println("State:", p.state) //state is promoted field }
在上面代码中的第 26 行和第 27 行,我们使用了语法 p.city 和 p.state,访问提升字段 city 和 state 就像它们是在结构体 p 中声明的一样。该程序会输出:
Name: Naveen
Age: 50
City: Chicago
State: Illinois
结构体相等性(Structs Equality)
结构体是值类型。如果它的每一个字段都是可比较的,则该结构体也是可比较的。如果两个结构体变量的对应字段相等,则这两个变量也是相等的。
练习:
通过map为数组添加三个元素,执行代码map[0](9)得到9,map[1](9得到81,mapp[2](9)得到729.
//-map内放函数 //-通过map实现set func main() { var m map[int]func(a int)int=make(map[int]func(a int)int) m[1]= func(a int) int { return a } m[2]= func(a int) int { return a*a } m[3]= func(a int) int { return a*a*a } fmt.Println(m[1](9)) fmt.Println(m[2](9)) fmt.Println(m[3](9)) }

map 实现set类型,增加删除修改元素,判断元素是否存在,获取len 等
func main() { //集合 //可以放值,如果重复了,放不进去 //可以获取长度 //判断一个值是否在集合内 //把集合内所有元素打印出来 var m map[string]bool=make(map[string]bool) m["lqz"]=true m["egon"]=true m["lqz"]=true fmt.Println(len(m)) //"aa"是否在集合内 if m["aa"]{ fmt.Println("在里面") }else { fmt.Println("不再") } for k,_:=range m{ fmt.Println(k) } }