文件压缩原理的简单理解、、、
为什么会写这篇文章,因为Linux中的压缩和Windows中的压缩有些区别,可能理解一下压缩原理,能更好的去使用Linux中的压缩
先贴一下Linux中压缩文件的数学公式:摘自香农论文:《通讯的数学原理》
----------------------------------------------------------------------------------------------
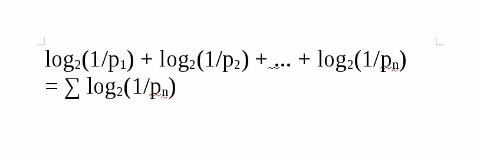
----------------------------------------------------------------------------------------------
我在博客园看到有人写了压缩的原理解释:写的超级长,看完之后我已经崩溃了,那篇文章我记得是有90个推荐的
文章的链接:https://www.cnblogs.com/esingchan/p/3958962.html
具体文章写的怎么样我不做评论,有兴趣的话可以点一下上个面的链接:过去看一下
----------------------
压缩和解压技术出现的可能和原因:
一个字节有 0 - 255 共 256 种可能的取值,三个字节有 256 * 256 * 256 共一千六百多万种可能的情况,更长的短语取值的可能情况以指数方式增长,出现重复的概率似乎极低,实则不然,各种类型的数据都有出现重复的倾向,一篇论文中,为数不多的术语倾向于重复出现;一篇小说,人名和地名会重复出现;一张上下渐变的背景图片,水平方向上的像素会重复出现;程序的源文件中,语法关键字会重复出现(我们写程序时,多少次前后copy、paste?),以几十 K 为单位的非压缩格式的数据中,倾向于大量出现短语式的重复。经过上面提到的方式进行压缩后,短语式重复的倾向被完全破坏,所以在压缩的结果上进行第二次短语式压缩一般是没有效果的。
-------------
解压缩(Decompression)是压缩的反过程,是将一个通过软件压缩的文档、文件等各种东西恢复到压缩之前的样子。
计算机处理的信息是以二进制数的形式表示的,因此压缩软件就是把二进制信息中相同的字符串以特殊字符标记来达到压缩的目的。
压缩可以分为有损和无损压缩两种。如果丢失个别的数据不会造成太大的影响,这时忽略它们是个好主意,这就是有损压缩。有损压缩广泛应用于动画、声音和图像文件中,典型的代表就是影碟文件格式mpeg、音乐文件格式mp3和图像文件格式jpg。但是更多情况下压缩数据必须准确无误,人们便设计出了无损压缩格式,比如常见的zip、rar
压缩软件(compression software)
压缩后所生成的文件称为压缩包(archive)
压缩后的文件内容包括这些东西(最简单的):规则表+内容+其他东西,解压时用规则表去套规则内容,比如规则表规定A=I LOVE YOU,那么就把内容中的所有A替换为I LOVE YOU(就像word的字符替换),如果文件重复性差,那么就没有替换的,算法差的话,规则表说不定比原来的所有内容还大,这样反而得不偿失了。
比如一个A-Z的字母表,在标准ZIP压缩后压缩率为107%!而一个26个A的文件压缩率就是15%。
-------------------
压缩工具只是根据文件保存字符的规律生成一套规则,然后用规则去保存源文件,解压就是用规则还原文件
------------
在通信原理中介绍数据压缩的时候,往往是从信息论的角度出发,引出香农所定义的熵的概念,
比如这句话:生,容易。活,容易。生活,不容易。
压缩原理就是 【通过寻找其中的规律,简化数字的排列】。
例如:
有字典列表:
00=Chinese
01=People
02=China
源文本:I am a Chinese people,I am from China 压缩后的编码为:I am a 00 01,I am from 02。压缩编码后的长度显著缩小,
---------------
常见的一些压缩算法:
RLE(Run Length Encoding)
是一个针对无损压缩的非常简单的算法。它用重复字节和重复的次数来简单描述来代替重复的字节。
-------------
固定位长算法(Fixed Bit Length Packing)
这种算法是把文本用需要的最少的位来进行压缩编码。
-------------------
霍夫曼编码(Huffman Encoding)
哈夫曼编码是无损压缩当中最好的方法。它使用预先二进制描述来替换每个符号,长度由特殊符号出现的频率决定。常见的符号需要很少的位来表示,而不常见的符号需要很多为来表示。
-----------------
Lempel-Ziv (LZ77)
LZ77算法的压缩原理
如果文件中有两块内容相同的话,那么只要知道前一块的位置和大小,我们就可以确定后一块的内容。所以我们可以用(两者之间的距离,相同内容的长度)这样一对信息,来替换后一块内容。由于(两者之间的距离,相同内容的长度)这一对信息的大小,小于被替换内容的大小,所以文件得到了压缩。
--------------------------
关于压缩形象的解释:
香农的信息理论,任何一个文件被无损压缩后的结果不可能小于其 熵 ,
如果一个文件有20多个G的大小,但是其信息熵只有20多M,则实现一个1000倍的压缩是完全可能的,一个文件如果虽然只有100M,但是其信息熵却高达90M,则这样的文件是无论如何也不可能被无损压缩至20M大小的。
压缩就是把原文件通过重新编码成另一种文件,就像我们生活中的速记法,用一个符号就能代表一句话,回家后再把符号还原回原文!
那么一百句话我只要十个符号就能表示,是不是就压缩了?
压缩后的文件也是,当你解压时就按这种压缩编码还原回原文件!
不同的压缩软件的编码都不一样,所以压缩比也不一样。
知乎上的一个笑话:老师说,回去把课文抄一千遍,结果第二天你交上去十几万字的作业,外星人看了后惊叹道,老师说的九个字竟然包含了这么多信息,压缩比太惊人了。
------------------------
关于香农:
比特(bit)这个单位,就是他发明的,用二进制存储信息也是他的贡献。
8岁,他就经常把姐姐的作业抢过来做,不要问他会不会这种挑战智商的问题,因为他从没做错过一道题,并且在他的顺手辅导之下,最后他姐姐成了数学系的教授。
除此之外,他还喜欢机械制作,在同龄人还都在玩儿泥巴的时候,他已经DIY了很多小机械;在大家伙都忙着在校园里为那么点微不足道的邂逅脸红心跳的时候,这个哥已经能自己徒手制作电动船、电报机、各种机械动物了。。。注意这个时候,他还没上大学。
----------------
理科生的思维+工科生的动手能力+爆表的思维,注定了他非池中之物,所以,他不出意料的进了美国最牛X的理工科学校——麻省理工学院(MIT)。
---------------
他硕士毕业那一年,他把19世纪中叶英国数学家——乔治·布尔的布尔代数和电子电路中开关和继电器的工作原理,独创性地结合在一起,直接炸出了一个新的学科:信息学。
他告诉我们:这个世界所有的信息都可以用0和1来表示。
看到0和1你是不是第一个想到了计算机没错是的,
科学家们发现一个规律,发明家们发明一个产品,很多时候都是特定条件和需求下的产物,就好比牛顿被苹果砸中发现万有引力定律,爱迪生发明灯泡,可这个哥明显是因其强大的智商,超前的思维,颠覆了那个时代。
1943年,他在饭桌上跟人工智能之父阿兰·图灵说过这样一句话:“我不仅仅满足于向这台“大脑”里输入数据,还希望把文化的东西灌输进去。”当时,人工智能之父就被震惊了。
-----------------
1948年香农在Bell System Technical Journal上发表了《A Mathematical Theory of Communication 》(通讯的数学原理)
提出了熵(entropy)的概念
他证明熵与信息内容的不确定程度有等价关系。熵曾经是波尔兹曼在热力学第二定律引入的概念,我们可以把它理解为分子运动的混乱度。信息熵也有类似意义,例如在中文信息处理时,汉字的静态平均信息熵比较大,中文是9.65比特,英文是4.03比特。这表明中文的复杂程度高于英文,反映了中文词义丰富、行文简练,但处理难度也大。信息熵大,意味着不确定性也大。因此我们应该深入研究,以寻求中文信息处理的深层突破。不能盲目认为汉字是世界上最优美的文字,从而引申出汉字最容易处理的错误结论。
1948年香农长达数十页的论文“通信的数学理论”成了信息论正式诞生的里程碑。在他的通信数学模型中,清楚地提出信息的度量问题,他把哈特利的公式扩大到概率pi不同的情况,得到了著名的计算信息熵H的公式:
计算信息熵H的公式
----------------------------------------------
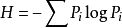
-----------------------------------------------
如果计算中的对数log是以2为底的,那么计算出来的信息熵就以比特(bit)为单位。今天在计算机和通信中广泛使用的字节(Byte)、KB、MB、GB等词都是从比特演化而来。“比特”的出现标志着人类知道了如何计量信息量。香农的信息论为明确什么是信息量概念作出决定性的贡献。
------------
香农仅仅从数学的角度解释信息,常常被人所诟病。认为他的信息论是狭隘的。对信息的诠释过于狭窄。我想作为数学家的香农,他也无可奈何。毕竟数学是不是科学,而是科学的工具,具有高度的抽象性;要想让具有高度抽象的数学负荷内容,难免免为其难。
‘信息’这个词在信息论的一般领域已经由各位作者赋予不同的意义。至少,这些意义很可能在某些应用领域充分证明是有用的,需要进一步的研究和做出永久性的承认。几乎不能指望一个单一的关于信息的概念能够令人满意地对一般领域的各种应用负责。”
香农为了避免继续被“追杀”,干脆对他提出的“信息”的概念放任自流了。别的领域爱怎么用就怎么用吧,只要你们能自圆其说。所以直到今天,信息无论是在哪个领域也没有一个定于一尊的定义!实际上,信息是一个不能被定义的“元概念”。颇有点儿像奥古斯丁(A. Augustinus)关于“时间”的说法。在其《忏悔录》卷十一中他说:“什么是时间?……如果没人问我,我知道它是什么。如果我想对他解释什么是时间,我却不知道了。”信息是否也和时间一样呢?
---------------------------------
熵”是信息论中最基本最重要的一个概念,香农最初想用“信息” (information) 来表达这一概念,但这个词当时已经被用滥了。香农便放弃用信息这个词。冯·诺依曼建议香农用“熵”;并给出二个理由:一是香农原本想用的“不确定性”(uncertainty)这个概念已经用于统计力学,二是没人知道“熵”倒底是什么,用它不会引起争论。
汉语中本无“熵”字,1923年德国物理学家普朗克(M. Planck)来华讲学时用到entropy这个词,由于entropy在表达形式上是两个量相除的商,我国著名物理学家胡刚复教授在现场口译时,把这个词翻译成“商”字加“火”旁创造了汉语的一个新术语“熵”。
最终,香农采纳了冯·诺依曼的建议,在信息论中提出了“信息熵”的概念,解决了信息的量化度量问题。一条信息的信息量大小和它的不确定性有直接关系。例如,我们要弄清楚一件很不确定的事情,或者我们一无所知的事情,就需要大量的信息。相反,如果我们对某件事已经有了较多的了解,就无需太多的信息就够了。所以,从信息论的角度看,信息量的度量等于不确定性的多少。信息熵的数学表达式很简洁:
信息熵的表达式
------------------------------------------------------------

-----------------------------------------------------------
---------------------