In the last years a lot of data has been released publicly in different formats, but sometimes the data we're interested in are still inside the HTML of a web page: let's see how to get those data.
One of the existing packages for doing this job is the XML package. This package allows us to read and create XML and HTML documents; among the many features, there's a function called readHTMLTable() that analyze the parsed HTML and returns the tables present in the page. The details of the package are available in the official documentation of the package.
Let's start.
Suppose we're interested in the italian demographic info present in this page http://sdw.ecb.europa.eu/browse.do?node=2120803 from the EU website. We start loading and parsing the page:
page <- "http://sdw.ecb.europa.eu/browse.do?node=2120803"
parsed <- htmlParse(page)
Now that we have parsed HTML, we can use the readHTMLTable() function to return a list with all the tables present in the page; we'll call the function with these parameters:
- parsed: the parsed HTML
- skip.rows: the rows we want to skip (at the beginning of this table there are a couple of rows that don't contain data but just formatting elements)
- colClasses: the datatype of the different columns of the table (in our case all the columns have integer values); the rep() function is used to replicate 31 times the "integer" value
table <- readHTMLTable(parsed, skip.rows=c(1,3,4,5), colClasses = c(rep("integer", 31)))
As we can see from the page source code, this web page contains six HTML tables; the one that contains the data we're interested in is the fifth, so we extract that one from the list of tables, as a data frame:
values <- as.data.frame(table[5])
Just for convenience, we rename the columns with the period and italian data:
# renames the columns for the period and Italy
colnames(values)[1] <- 'Period'
colnames(values)[19] <- 'Italy'
The italian data lasts from 1990 to 2014, so we have to subset only those rows and, of course, only the two columns of period and italian data:
# subsets the data: we are interested only in the first and the 19th column (period and italian info)
ids <- values[c(1,19)]
# Italy has only 25 years of info, so we cut away the other rows
ids <- as.data.frame(ids[1:25,])
Now we can plot these data calling the plot function with these parameters:
- ids: the data to plot
- xlab: the label of the X axis
- ylab: the label of the Y axis
- main: the title of the plot
- pch: the symbol to draw for evey point (19 is a solid circle: look here for an overview)
- cex: the size of the symbol
plot(ids, xlab="Year", ylab="Population in thousands", main="Population 1990-2014", pch=19, cex=0.5)
and here is the result:
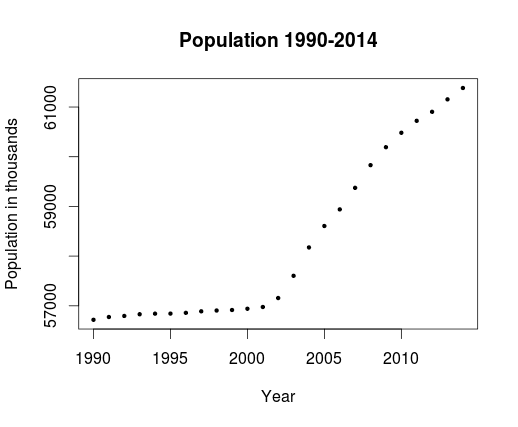
Here's the full code, also available on my github:
library(XML)
# sets the URL
url <- "http://sdw.ecb.europa.eu/browse.do?node=2120803"
# let the XML library parse the HTMl of the page
parsed <- htmlParse(url)
# reads the HTML table present inside the page, paying attention
# to the data types contained in the HTML table
table <- readHTMLTable(parsed, skip.rows=c(1,3,4,5), colClasses = c(rep("integer", 31) ))
# this web page contains seven HTML pages, but the one that contains the data
# is the fifth
values <- as.data.frame(table[5])
# renames the columns for the period and Italy
colnames(values)[1] <- 'Period'
colnames(values)[19] <- 'Italy'
# now subsets the data: we are interested only in the first and
# the 19th column (period and Italy info)
ids <- values[c(1,19)]
# Italy has only 25 year of info, so we cut away the others
ids <- as.data.frame(ids[1:25,])
# plots the data
plot(ids, xlab="Year", ylab="Population in thousands", main="Population 1990-2014", pch=19, cex=0.5)
from: http://andreaiacono.blogspot.com/2014/01/scraping-data-from-web-pages-in-r-with.html