At some fundamental level, no one understands machine learning.
It isn’t a matter of things being too complicated. Almost everything we do is fundamentally very simple. Unfortunately, an innate human handicap interferes with us understanding these simple things.
Humans evolved to reason fluidly about two and three dimensions. With some effort, we may think in four dimensions. Machine learning often demands we work with thousands of dimensions – or tens of thousands, or millions! Even very simple things become hard to understand when you do them in very high numbers of dimensions.
Reasoning directly about these high dimensional spaces is just short of hopeless.
As is often the case when humans can’t directly do something, we’ve built tools to help us. There is an entire, well-developed field, called dimensionality reduction, which explores techniques for translating high-dimensional data into lower dimensional data. Much work has also been done on the closely related subject of visualizing high dimensional data.
These techniques are the basic building blocks we will need if we wish to visualize machine learning, and deep learning specifically. My hope is that, through visualization and observing more directly what is actually happening, we can understand neural networks in a much deeper and more direct way.
And so, the first thing on our agenda is to familiarize ourselves with dimensionality reduction. To do that, we’re going to need a dataset to test these techniques on.
MNIST
MNIST is a simple computer vision dataset. It consists of 28x28 pixel images of handwritten digits, such as:
Every MNIST data point, every image, can be thought of as an array of numbers describing how dark each pixel is. For example, we might think of 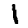 as something like:
as something like:
≃⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢000000000000000000000000000000000000000000000000000000000000000000000000000