一般会有这几个场景:
一. 主力的开发工具,这个首推sublime text。主要优点有以下几点:
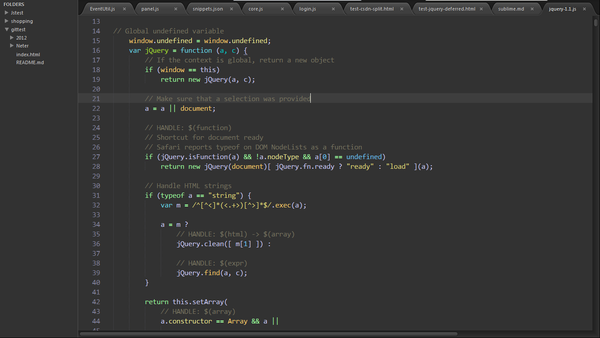
1. 功能强大,占用内存小,插件丰富,界面友好,可以免费试用(多谢评论区同学指正),适合前端开发这个岗位,支持语言比较多,可以跟不同的语言来合作还没有跨界的遗憾。
2. jikeytang/sublime-text: sublime-text 具体看这个网站。
二. 方便提交 ftp,svn,git,查看本地文件历史记录的。这个我推荐webstorm:
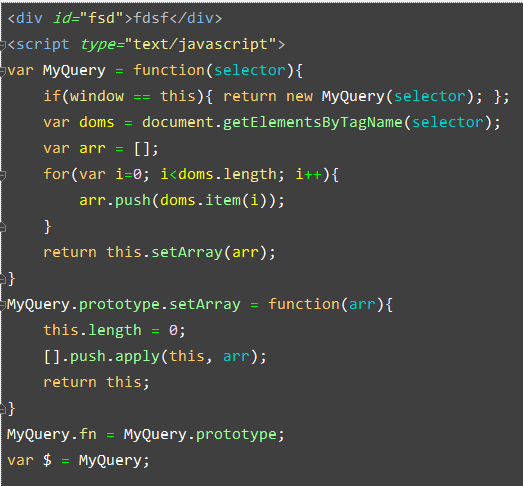
1. ftp看这个:
如何在Webstorm/Phpstorm中设置连接FTP,并快速进行文件比较,上传下载,同步等操作
2. 同时支持svn,git图形化操作,这里边不强调图形化比命令化功能对比,只说,图形化操作确实比较直观。
另外webstorm本身的svn功能与小乌龟功能还是差不少,比如查看一些历史记录,浏览等等的。
3. webstorm只是jetbrain大厂提供的一个,还有phpstorm, intellij idea也是不错的产品。
他的缺点是:占用内存大。
三. 方便查看源码的,这个场景主要在新老版本交替,为了防止改错文件,我特意拉一个编辑器来查看:
1. atom
界面风格离sublime最近的一款。
2. notepad++
也可以,主要有一个工程目录管理,新版本也加了一个右边文件快速预览的功能。
四. 单文件编辑,代替系统默认的notepad的,应用场景主要在临时记事,编辑小的文本,比如现在写答案用的。推荐:notepad2
五. 炫技的vim,其实vim的强大在于他的修改场景,就是他写的时候跟别人差别不大,主要在修改的时候,快捷键的颗粒支持到任何一个场景。删前一个字母,后一个字母,跳前面,跳后面,等等。但是sublime里边vim插件偶尔用用还是不错的,webstorm的vim插件老是感觉没有st里边用那个无缝。另外win上用vim也就那样了,mac上还是不错的,半透明,多标签等等都支持。
另外vim的场景是,一般的产品环境都是linux系统,这下面只有vim。
六. 有一些编辑器还有一定的应用场景,比如editplus里边批量修改文件编辑的功能,快速启动也是他的一个优点。ftp链接等等的,也是不错的。
七. vs code:这款跨平台的,他是我用过所有的编辑器里边提示是最快的一款,webstorm的代码提示问题延迟那么几毫秒,但是这款跟其它微软产品一样,除了这个优点之外,没找出其它任何一个比其它编辑器胜出的地方。只感觉有点像adobe的Bracket,不习惯顶部空着,把打开的文件放到左边。
然后说,都装了吗?常用的都装了,其实常用的就那几个。另外跨平台的几款做的比较好的:sublime, webstorm, atom这几款在win,mac平台下基本差别不大。
最后题外话:没有最好的,只有最合适自己心理特征的,而每个人的内心活动是有差异的,只有建议自己去试。另外编程的核心还是:算法+数据结构。如果用一张图形容,就借用@winter老师的这张图:
 看到没有,上面是知识,下面是能力,通过知识来积累编程的能力,不是通过工具来限制你思考的速度或深度。
看到没有,上面是知识,下面是能力,通过知识来积累编程的能力,不是通过工具来限制你思考的速度或深度。这个是你需要突破的瓶颈所在或所需要花费更多精力的地方,编辑器随便选一个,在入行初期对生产效率的影响并不大。限制产出的永远是人的思维,工具只是暂时的满足快速编程的假象。
以上仅供参考。
然后,如果喜欢前端,那就加这个前端群:492107297,禁止闲聊,非喜勿进。
vue爱好者,加这个群:364912432
进前,群规,月报先熟悉一下:
目录 - [ JS前端开发群规
目录 - [ JS前端开发群月报 ]



.
看了一圈,都是编程人员在回答,我就作为一个非编程人员来说点不同的视点吧。
既然说的是「文本编辑器」,最重要的当然是「编辑文本」,而不局限于编程。
我一直在使用的文本编辑器是 vim(windows 下用 gvim,OS X 下用 MacVim),偶尔写代码,主要用来做文本处理。Sublime Text、Emacs(包括纯 evil mode 和 spacemacs)、Atom、VS Code、em editor、notepad++ 等等都用过,最后还是回到 vim 。
究其原因,很多文本编辑器是针对编程来优化的,而不是「文本处理」,于是在文本处理上,远没有 vim 来得方便。
我用 vim 主要做的事情有这几件:
- 作为 markdown 编辑器写文章
- 特定的格式化文本处理
- 制作 epub 电子书
作为 markdown 编辑器写文章
vim 用来写文章的一个很大的优势就是 VOoM 插件。这是一个大纲列表,可以根据特定的标记符号生成像左边这样的文章大纲窗口。在 em editor 中你也可以找到类似的功能。这个插件默认是支持 markdown 的,能够识别出文章的标题。
#一级标题
##二级标题
###三级标题
####四级标题
#####五级标题
######六级标题
#一级标题
##二级标题
###三级标题

并且能够在大纲窗口中通过 ctrl + ↑、ctrl + ↓ 这样的快捷键操作,对标题(及下面所属的内容)进行上下移动,也能进行升级。对于写文章时列大纲、把握文章整体构造还有调整文章结构来说都是十分有利的功能。Emacs 的 org-mode 本身的功能虽然十分出色,但是唯独缺少这样方便的大纲功能,还是比较遗憾的。网上有一些通过 Emacs 的 mini buffer 来实现类似功能的建议,但是对于不熟悉 elisp 的非程序员来说,要自己来实现一个确实太困难了。
特定的格式化文本处理
得益于 vim 的 ex mode 和 viml( vim language ),我可以简单地编写一些脚本命令来进行重复的文本格式化处理。
比如说,我需要处如下的列表式文本,把左右列分开:
原作 - 川原礫(電撃文庫 / アスキー·メディアワークス刊)
原作イラスト·キャラクターデザイン原案 - abec
監督 - 伊藤智彦
キャラクターデザイン - 足立慎吾
美術監督 - 竹田悠介
色彩設計 - 中島和子
コンセプトアート - 堀壮太郎
撮影監督 - 廣岡岳
CG監督 - 雲藤隆太
編集 - 西山茂
音響監督 - 岩浪美和
音楽 - 梶浦由記
アニメーション制作 - A-1 Pictures
原作
原作イラスト·キャラクターデザイン原案
監督
キャラクターデザイン
美術監督
色彩設計
コンセプトアート
撮影監督
CG監督
編集
音響監督
音楽
アニメーション制作
川原礫(電撃文庫 / アスキー·メディアワークス刊)
abec
伊藤智彦
足立慎吾
竹田悠介
中島和子
堀壮太郎
廣岡岳
雲藤隆太
西山茂
岩浪美和
梶浦由記
A-1 Picture
在 vim 里面只需要两个命令:
:%s/ - /rt
:g/^ /m$
因为我需要频繁用到这样的需求,所以不想频繁重复地写这样的命令。所以我就可以写一个函数来处理:
function ListSplit()
:%s/ - /rt
:g/^ /m$
endfunction
我们可以看到,这个所谓的函数,实际上就是只是把 ex mode 中输入的命令写上去而已。我平常是怎么在 vim 的进行操作的,就可以怎样很直觉地把这些操作整合成一个函数。对于没有编程基础的用户来说,这比起 elisp 这种过分强大的的语言来说简单明了得多。
在 Emacs 中,你是无法如此简单地把一般的操作转化为一个函数、一个脚本的。而在其他编辑器中,你甚至无法找到一个如此轻量化的解决方案。
完成定义之后,我就能用简单的调用函数来执行这两句命令:
:call ListSplit()
如果这样还觉得麻烦,那么可以为函数定一个自定义命令,省去写「 call 」的麻烦。
command! ListSplit call ListSplit()
如果连命令都懒得输,绑定一个快捷键也十分简单:
nmap <F1> :call ListSplit()<cr>
这样就可以用 F1(当然也可以是其他快捷键,配合 键甚至可以有更灵活的配置)调用这个函数。
制作 epub 电子书
制作一本简单的 epub 电子书,有两大部分工作:整理文本,和对文本进行打包。
整理文本是 vim 的拿手好戏,而把文本打包成 epub 文件,就涉及到了很多的 I/O 操作,viml 确实是搞不定的,这部分我用了 python 来写,因为 vim 本身有 python 接口。
这是我用来制作 epub 的小插件:dotvim/bundle/epub-build/plugin at master · zecy/dotvim · GitHub
说是插件,实际上里面只有一堆相互独立的函数,而函数的内部基本上都是大量的替换命令。如果是其他编辑器,你要自行制作同样的文本整理功能,就逃不了正儿八经的编程了。相对而言,用 viml 来做这个事情,远远要简单得多。
以下我说明里面的两个小函数。
function SymbolChange()
silent %s/v(1|2|3|4|5|6|7|8|9|0)/={'1':'1','2':'2','3':'3','4':'4','5':'5','6':'6','7':'7','8':'8','9':'9','0':'0'}[submatch(0)]/ge
silent %s/v(A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z)/={'A':'A','B':'B','C':'C','D':'D','E':'E','F':'F','G':'G','H':'H','I':'I','J':'J','K':'K','L':'L','M':'M','N':'N','O':'O','P':'P','Q':'Q','R':'R','S':'S','T':'T','U':'U','V':'V','W':'W','X':'X','Y':'Y','Z':'Z'}[submatch(0)]/ge
python << EOF
# -*- coding: UTF-8 -*-
import vim
import string
import re
b = vim.current.buffer
t = u'
'.encode("UTF-8").join(b)
t = t.decode("UTF-8")
def symbolchange(t):
t = re.sub(u'( | | )+', u' ', t)
t = re.sub(u'[[“【]', u'「', t)
t = re.sub(u'[]”】]', u'」', t)
t = re.sub(u'‘', u"『", t)
t = re.sub(u'’', u"』", t)
# t = re.sub(u'[‘’]', u"'", t)
t = string.replace(t, "&", "&")