tesseract-ocr引擎
光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。OCR技术非常专业,一般多是印刷、打印行业的从业人员使用,可以快速的将纸质资料转换为电子资料。关于中文OCR,目前国内水平较高的有清华文通、汉王、尚书,其产品各有千秋,价格不菲。国外OCR发展较早,像一些大公司,如IBM、微软、HP等,即使没有推出单独的OCR产品,但是他们的研发团队早已掌握核心技术,将OCR功能植入了自身的软件系统。对于我们程序员来说,一般用不到那么高级的,主要在开发中能够集成基本的OCR功能就可以了。这两天我查找了很多免费OCR软件、类库,特地整理一下,今天首先来谈谈Tesseract,下一次将讨论下Onenote 2010中的OCR API实现。可以在这里查看OCR技术的发展简史。
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
###安装tesseract-ocr引擎
brew install tesseract然后我们通过tesseract -v看一下是否安装成成功
tesseract 3.05.01
leptonica-1.75.0
libjpeg 9b : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11这时候我们运行上面代码会出现乱码
这是因为tesseract默认只有语言包中没有中文包,如下图:
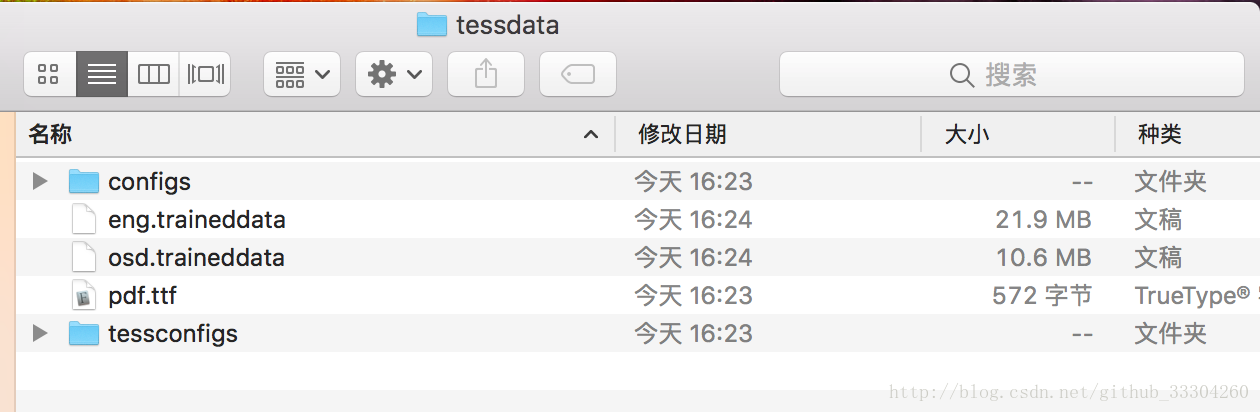
###安装tesseract-ocr语言包
我们去GitHub下载我们需要的语言包,这里我只下载了chi_tra.traineddata和chi_sim.traineddata
github:tesseract-ocr/tessdata
然后放到/usr/local/Cellar/tesseract/3.05.01/share/tessdata路径下面。
可以通过tesseract --list-langs查看本地语言包: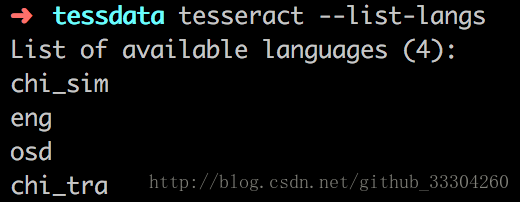
可以通过tesseract --help-psm 查看psm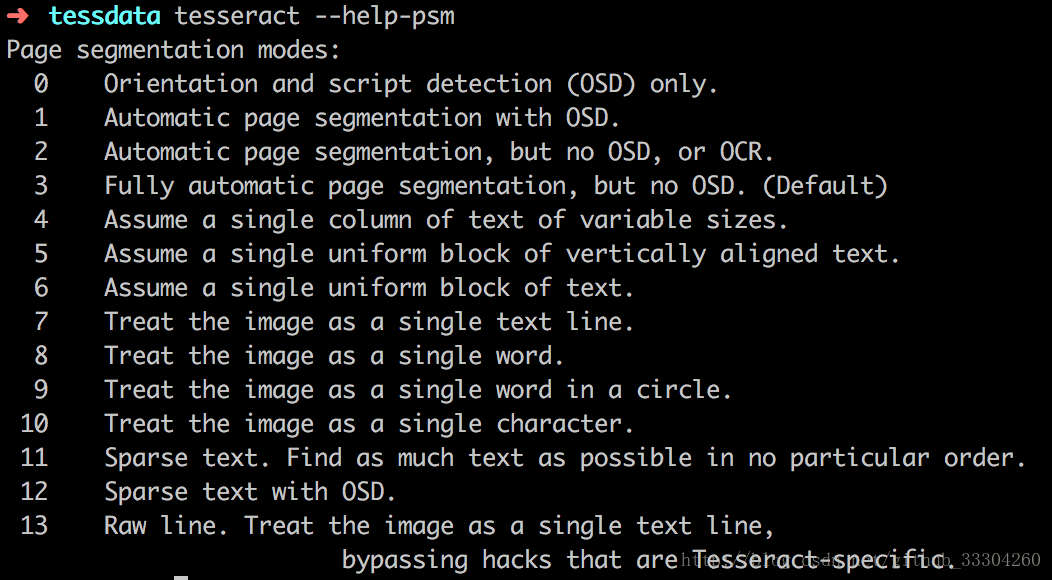
0:定向脚本监测(OSD)
1: 使用OSD自动分页
2 :自动分页,但是不使用OSD或OCR(Optical Character Recognition,光学字符识别)
3 :全自动分页,但是没有使用OSD(默认)
4 :假设可变大小的一个文本列。
5 :假设垂直对齐文本的单个统一块。
6 :假设一个统一的文本块。
7 :将图像视为单个文本行。
8 :将图像视为单个词。
9 :将图像视为圆中的单个词。
10 :将图像视为单个字符。
为什么这里要强调语言包和psm,因为我们在使用中会用到,
比如多个语言包组合并且视为统一的文本块将使用如下参数:pytesseract.image_to_string(image,lang="chi_sim+eng",config="-psm 6")
这里我们通过+来合并使用多个语言包。