什么是索引?
一个索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。索引是在表的列上创建。所以,要记住的关键点是索引包含一个表中列的值,并且这些值存储在一个数据结构中。请记住记住这一点:索引是一种数据结构。
因此,首先你要明白的一点就是,索引它也是一个文件,它是要占据物理空间的。
这个在MySQL目录下可以找到,比如:C:ProgramDataMySQLMySQL Server 5.7Datamysql
比如对于MyISAM存储引擎来说:.frm后缀的文件存储的是表结构。.myd后缀的文件存储的是表数据。.myi后缀的文件存储的就是索引文件。
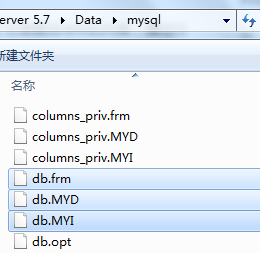
对于InnoDB 存储引擎来说:.frm后缀的文件存储的是表结构。.ibd后缀的文件存放索引文件和数据(需要开启innodb_file_per_table 参数)
如何使用索引?
创建索引
1.ALTER TABLE
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。
-
ALTER TABLE 表名 ADD INDEX 索引名 (列名)
-
ALTER TABLE 表名 ADD UNIQUE 索引名(列名)
-
ALTER TABLE 表名 ADD PRIMARY KEY 索引名(列名)
另外
- 索引名可不写
2.CREATE INDEX
CREATE INDEX可对表增加普通索引或UNIQUE索引。
-
CREATE INDEX 索引名 ON 表名 (列名)
-
CREATE UNIQUE INDEX 索引名 ON 表名 (列名)
注意:
- 索引名必须有
- 不能用CREATE INDEX语句创建PRIMARY KEY索引。
删除索引
-
DROP INDEX 索引名 ON 表名
-
ALTER TABLE 表名 DROP INDEX 索引名
查看索引
-
show index from 表名;
-
show keys from 表名;
索引优缺点?
优点
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
- 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
- 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
- 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
缺点
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
- 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
- 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
索引类型
如果有可视化MySQL客户端,可以较为清晰的看到索引类型(我用的navicat)
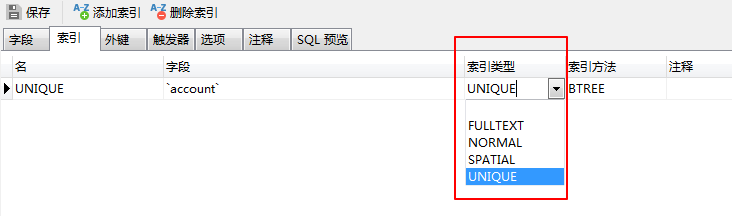
1. 全文索引(FULLTEXT)
全文索引主要用于海量数据的搜索,比如淘宝或者京东对商品的搜索,你不可能使用like进行模糊匹配吧,MySQL从5.6开始支持InnoDB引擎的全文索引,功能没有专业的搜索引擎比如Sphinx或Solr丰富,如果你的需求比较简单,可以尝试一下MySQL的全文索引,否则建议使用专业的搜索引擎。
2. 普通索引(NORMAL)
普通索引的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column=)或排序条件(ORDER BY column)中的数据列创建索引。
3. 空间数据索引(SPATIAL)
空间索引可用于地理数据存储,它需要GIS相关函数的支持,由于MySQL的GIS支持并不完善,所以该索引方式在MySQL中很少有人使用。
4. 唯一索引(UNIQUE)
确保了数据的唯一性,比如学生的的姓名可能会重复,但是学号绝不可能重复,这时候就可以给学号加上唯一索引
事实上,在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复。
索引方法?
先用客户端看一下有几种方法
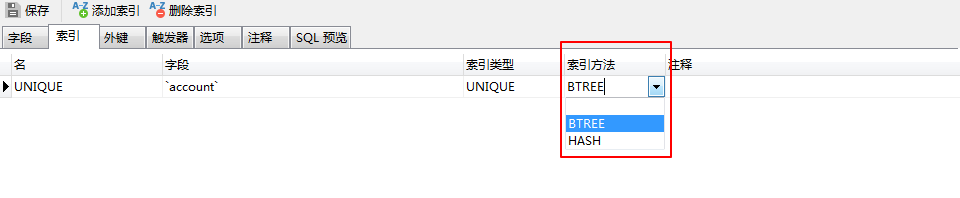
1. B-Tree索引
B-Tree索引是最常用的一种索引,如果没有指定特定的类型,那么多半就是B-Tree索引。
绝大多数的存储引擎,比如MyISAM和InnoDB都支持这种索引,因此说它是应用最广泛,最常用的一种索引方式,但是不同的存储引擎在具体实现时会稍有不同,比如MyISAM会使用前缀压缩的方式对索引进行压缩,InnoDB则不会。
下图展示了B-Tree索引是如何存储被索引的数据的:
说明:

- 左图是一个包含三列的数据表,右图则展示了数据是如何被索引的。
- 可以看出B-Tree是对索引列是按照顺序存储的,每个叶子节点指向被索引的数据,这也是B-Tree索引支持范围查找数据的原因。
2. 哈希索引
相比于B-Tree索引,哈希索引的实现就比较简单了,它是基于哈希表来实现的,对于要索引的列,存储引擎会计算出一一对应的哈希码,然后把哈希码存放在哈希表中作为key,value值是指向该行数据的指针。
下图是简单的原理展示:
说明:
左边紫色图表示一个二列的数据表。
中间表示对fname列进行哈希索引,计算出哈希值。
右边绿色图表示把生成的哈希值存放于哈希表中。
当我们执行以下查询时:

select * from testTable where fname = "mary";MySQL会首先计算查询条件mary的哈希值,然后到哈希表中去找该哈希值,如果找到了根据对应的指针也就找到了需要寻找的数据行。
哈希表的优势与限制:
优点:
- 只需比对哈希值,因此速度非常快,性能优势明显;
缺点:
- 不支持任何范围查询,比如where price > 150,因为是基于哈希计算,支持等值比较。
- 哈希表是无序存储的,因此索引数据无法用于排序。
- 主流存储引擎不支持该类型,比如MyISAM和InnoDB。哈希索引只有Memory, NDB两种引擎支持。
因此,哈希索引虽然速度快,但其实使用很受限,只适用于某些特殊的场合。
什么情况下索引会失效?
1、如果条件中有or,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引。
如:
-
select id from t where num=10 or num=20;
-
#可以这样查询:
-
select id from t where num=10;
-
union all
-
select id from t where num=20;
2、like查询是以%开头
3、如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
4、如果mysql估计使用全表扫描要比使用索引快,则不使用索引
5、对索引列进行运算导致索引失效,我所指的对索引列进行运算包括(+,-,*,/,! 等)
-
错误的例子:select*from test where id-1=9;
-
正确的例子:select* fromtest where id=10;
6、使用 <> 、not in、not exist、!=
比如
select id from t where num in(1,2,3);7、索引字段进行判空查询时。也就是对索引字段判断是否为NULL时。语句为is null 或is not null。
-
select id from twhere num is null;
-
#可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
-
select id from t where num=0;
最左前缀匹配原则?
对于多列索引,总是从索引的最前面字段开始,接着往后,中间不能跳过。
比如列索引(a,b,c)创建的同时,已经对(a)、(a,b)、(a,b,c)上建立了索引,中间不能跳过,比如(a,c)就不行。
但是内部顺序不要求一定按照顺序来,因为MySQL会自动优化,比如说(a,b)写成(b,a)也没问题
使用索引情况
什么情况下该使用索引?
- 在经常需要搜索的列上,可以加快搜索的速度;
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
- 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
什么情况下不该不使用索引?
- 对于那些在查询中很少使用或者参考的列不应该创建索引。因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
- 对于那些只有很少数据值的列也不应该增加索引。例如性别,只有两种可能数据。意味着索引的二叉树级别少,这样的二叉树查询无异于全表扫描。
- 频繁更新的字段不要使用索引